改裝 2080 Ti 22G · part 8
[趣味競賽 進階 #8] 為什麼 30 tok/s 體感比 14 還慢:TTFT 才是你真正感覺到的速度
❯ cat --toc
TL;DR
我把 agent 的腦從 14 tok/s 換成 30-40,體感反而變慢——因為你真正感覺到的速度是 TTFT(多久才開始吐字),不是 tok/s(開始之後吐多快)。Hina(Qwen3.6-27B)是 hybrid 架構,mainline llama.cpp 沒辦法重用它的前綴快取,一次 cache miss 就整段重算:同一台機、同一顆腦,暖機 2.6 秒、冷掉 216 秒——83 倍落差,在 decode 數字裡完全看不見。這是 case study 不是 benchmark,當故事讀。
白話導讀:你感覺到的不是「吐字多快」,是「多久才開始吐」
挑本地模型,大家第一眼都看 tok/s——一秒吐幾個字。我也是,盯了快一年。所以當我把家裡那顆 agent 腦,從別台一秒只吐 14 個字的,換成這台一秒吐 30 到 40 的,我以為它會明顯變快。
結果它感覺更慢。
我花了整整一天才搞懂為什麼。問題不在 decode——一秒吐幾個字,這顆新腦確實快兩倍。問題在我送出訊息之後、第一個字冒出來之前那段等待。那段等待有個名字叫 TTFT(time-to-first-token),而我盯了一年的 tok/s 根本沒在量它。
更糟的是,在這顆腦上,那段等待會爆炸性地拉長。它的架構(hybrid)有個特性:只要快取沒命中,它就得把你之前講的所有話從頭重新讀一遍才能回你。暖機的時候,這段等待是兩三秒;一旦快取沒了(服務重啟過、或快取被別的對話佔走),同一句話的等待可以拉到三分鐘。
這篇就是把這件事講透:為什麼 tok/s 是虛榮指標,為什麼你該盯的是 TTFT,以及這一切的病根——一顆 hybrid 腦不能重用快取——是怎麼回事。
前言:接著前面那顆 27B 腦,講它的第一個體感坑
前面幾篇講的是這顆腦怎麼來的(#1:一張二手改裝的 22G 2080 Ti)、為什麼選它(#2:慢的 Qwen 27B 比快的 Gemma 12B 更肯守紀律)。後來 #5 KV cache 存硬碟跟 #6 工具定義稅寫的都是解法——但當初逼我去找解法的那個病,也就是掛上去之後遇到的第一個反直覺的體感問題,反而一直沒寫。就是這篇。
故事是這樣的。我手上其實有兩顆 agent 腦:
- 一顆是光羽 / ds4(DeepSeek-V4-Flash,abliterated),跑在另一台機器(GB10)上,decode 只有 ~14 tok/s——慢。
- 一顆是雛羽 / Hina(Qwen3.6-27B Q4_K),就是這顆改裝 2080 Ti 養的,decode ~30-40 tok/s——快兩倍多。
按 tok/s 看,Hina 該是「比較快」的那顆。但實際用起來,慢的那顆光羽體感更順。
⚠️ 先把話講死:這不是 benchmark。14 跑在 GB10(Blackwell)、30 跑在 2080 Ti(Turing),兩顆不同模型、兩台不同 GPU,而且 14 那邊的數字是舊 log 的 memory 記錄,不是本次同硬體 paired 重測。這是真實的使用體感對照,不是控制變因的實驗。當 case study 讀。
那為什麼慢的反而順?因為我看錯了指標。
虛榮指標:tok/s 量的是後半段,不是前半段
一回合對話,從你按下送出到你看完整段回覆,時間其實分兩段:
- TTFT(time-to-first-token):從你送出,到第一個字冒出來。這段裡,模型要先把整個 prompt(系統提示 + 工具定義 + 你之前的對話 + 這句新的)讀進去、算出狀態——這個動作叫 prefill。prompt 越長、或快取命中率越低,這段就越久。
- decode:第一個字之後,每秒吐幾個字。這就是 tok/s 量的東西。
注意:tok/s 只量第二段。 它完全沒告訴你第一段要等多久。

對純聊天來說,prompt 短、prefill 快,TTFT 可以忽略,所以 tok/s 約等於體感速度——一年來我盯它盯得理直氣壯,就是因為我大多在聊天。但對 agent 來說,prompt 一點都不短:光是工具定義就先吃掉一萬七千個 token(就是 #6 工具定義稅拆開算的那筆帳),加上長對話,prompt 動輒三四萬 token。這時候 TTFT 不但不能忽略——整回合大半的時間,都卡在第一個字冒出來之前。
而我那顆「快」的 Hina,偏偏就在這段栽了。
一手證據:Hina 自己的 log,暖機 2.6 秒 vs 冷掉 216 秒
光講道理沒用,直接看 Hina 的 agent 框架連續記下來的真實 API 呼叫。下面這些都是 [live] 從 log 裡撈的,同一顆 Qwen 腦(model=qwen36-27b)、同一段時間。in= 是 prompt 的 token 數、cache= 是這回合快取命中多少、latency 是整回合的等待時間:
| prompt token (in=) | 快取命中 | 等待時間 | 發生了什麼 |
|---|---|---|---|
| 25,345 | 100% | 2.6s | 暖機——前綴整段命中 |
| 46,101 | 100% | 11.4s | 暖機,context 較長 |
| 47,928 | 98% | 185.2s | 98% 命中,context 深,照樣等 3 分鐘 |
| 25,167 | 24% | 43.1s | 大 miss |
| 45,014 | (無快取行) | 216.6s | 冷啟——伺服器已沒有這段對話的快取 |
| 49,796 | (冷) | 230.6s | 冷啟,整段重算 |
| 48,953 | (冷) | 211.2s | 冷啟,~49K context 整段重算 |
讀這張表,看那個對比:同一顆腦、同一台機——暖機那回合 2.6 秒,冷掉那回合 216 秒。
83 倍的落差。而這 83 倍,在 decode 的 tok/s 數字裡完全看不見——decode 從頭到尾都是那 ~32 tok/s,擺盪全藏在 TTFT 裡。

補一個 log 裡的細節:那幾筆「冷啟」(in= 四五萬卻沒有快取命中行、等 200 秒以上)不是憑空冒出來的——它們都是新一輪對話 loop 的第一次呼叫,伺服器手上已經沒有這段對話算好的狀態。狀態怎麼不見的?那一晚整條鏈其實重啟過不只一次:forge 上的 llama-server 服務 log 在 01:45、02:12 各轉檔重啟一輪(llama-server 一重啟,RAM 裡的 prompt 快取直接蒸發),yui 上的 gateway 也在 02:11:49 被訊號打斷重啟過(log 原文
Gateway stopped by an unexpected signal→02:11:51 Starting Hermes Gateway);就算沒人重啟,快取槽被別的對話佔走也一樣。只要狀態不在,hybrid 就沒得接——整段重讀四五萬 token。這就是「快取流失稅」被攤在陽光下的樣子,也就是 #5「KV cache 存硬碟」那篇後來解掉的問題。
病根:為什麼一次 miss 這麼痛——hybrid 整段重算
一回合等 200 秒,聽起來太誇張。普通模型不該這樣——它應該只補算「你新講的那句」,前面幾萬 token 都從快取拿就好。為什麼 Hina 不行?
因為 Hina 的腦是 hybrid 架構:Qwen3.6 把標準注意力跟 Gated DeltaNet 線性注意力(帶循環狀態)混在一起,llama.cpp 把後者當 recurrent 記憶體處理。而 mainline llama.cpp 在 hybrid + SWA 模型上沒辦法重用前綴快取。這不是我猜的,是 llama-server 自己在 log 裡標出來的。下面這行是 [live] 從 forge 上撈的,一字不改:
slot update_slots: id 0 | task 282 | forcing full prompt re-processing
due to lack of cache data (likely due to SWA or hybrid/recurrent memory,
see https://github.com/ggml-org/llama.cpp/pull/13194#issuecomment-2868343055)
slot update_slots: id 0 | task 282 | erased invalidated context checkpoint
(pos_min = 44, pos_max = 44, n_tokens = 45, ... size = 62.813 MiB)
兩行連著看(都是 [live] 從 forge 撈的,一字不改):第一行說「因為沒有快取資料,強制把整段 prompt 從頭重算(很可能是 SWA 或 hybrid/循環記憶導致的)」;第二行說它把一個 context checkpoint 標成失效、清掉了(erased invalidated)。也就是說,即便手上有一份先前算過的狀態,hybrid 架構讓它沒辦法接著用,只能作廢、整段重來。
llama.cpp 的 PR 討論串也把這個取捨講得很白:
- PR #13194(「kv-cache : add SWA support」,已 merge):它明說 SWA / hybrid 模型「沒辦法做前綴快取、沒辦法 context shift、沒辦法 context reuse」——「視窗一滑動,舊的 KV 就被『忘掉』了,除了重算沒有辦法救回來」。這正是上面那行 log 的出處。
- Issue #20225(「Qwen 3.5 每回合都整段重算」,狀態 closed 的 eval bug 回報):它確認了就是這個模型家族——「Qwen 3.5 27B(混合注意力 + Mamba2/SSM)每一回合都強制整段重算 prompt」,一段 15K token 的對話「每回合要 ~8 分鐘,而不是幾秒」。(⚠️ 標題寫的是 Qwen 3.5,forge 跑的是 3.6——同一個 hybrid 家族、同一個毛病;「Mamba2/SSM」是回報者的用語,Qwen 官方模型卡把這層線性注意力叫 Gated DeltaNet。我把它當「實務上已被確認的 hybrid 限制」來引,不深究它的 open/closed 狀態。)
所以這顆腦的病,不是「context 太長」,也不是「工具太多」,是「hybrid 不能重用快取」。一顆普通 transformer 在前綴穩定、快取暖著的時候不會有這問題:它把前綴 prefill 一次、之後一直重用那份快取。把這句記牢,不然你會去修錯的東西。
冷啟有多貴:prefill 越長越久,而且越大越慢
那「整段重算」到底多貴?說白了,它就是把整段 prompt 重新 prefill 一次:prompt 越長,等越久——更陰的是,長度越大,每秒能 prefill 的 token 數反而越掉:
| prompt 長度 | 冷啟 prefill 吞吐 | 冷啟整段等待 |
|---|---|---|
| 4K | 624 tok/s | ~5s |
| 16K | 610 tok/s | ~16s |
| 48K | 501 tok/s | ~55s |
| 110K | 360 tok/s | ~131s |
⚠️ 這張 4K→110K 的縮放曲線是 [memory] 的數字(早先的 bench session 量的),本次沒有同硬體重測,當數量級看;等待欄是當時記到的整段等待,不是長度÷吞吐換算出來的。要分清楚兩種 prefill:暖機接著補算的那種(只算你新講的一小段、前面從快取拿)很便宜,實測到的暖機 bulk prefill 在 31-43K context 上跑 ~496-540 tok/s [memory];真正貴的是整段冷重算那種大 prefill,才會慢成上表那樣。decode 端則本次在 forge 上一路實測到 ~34-38 tok/s [live],對得上 ~32-40 的說法。
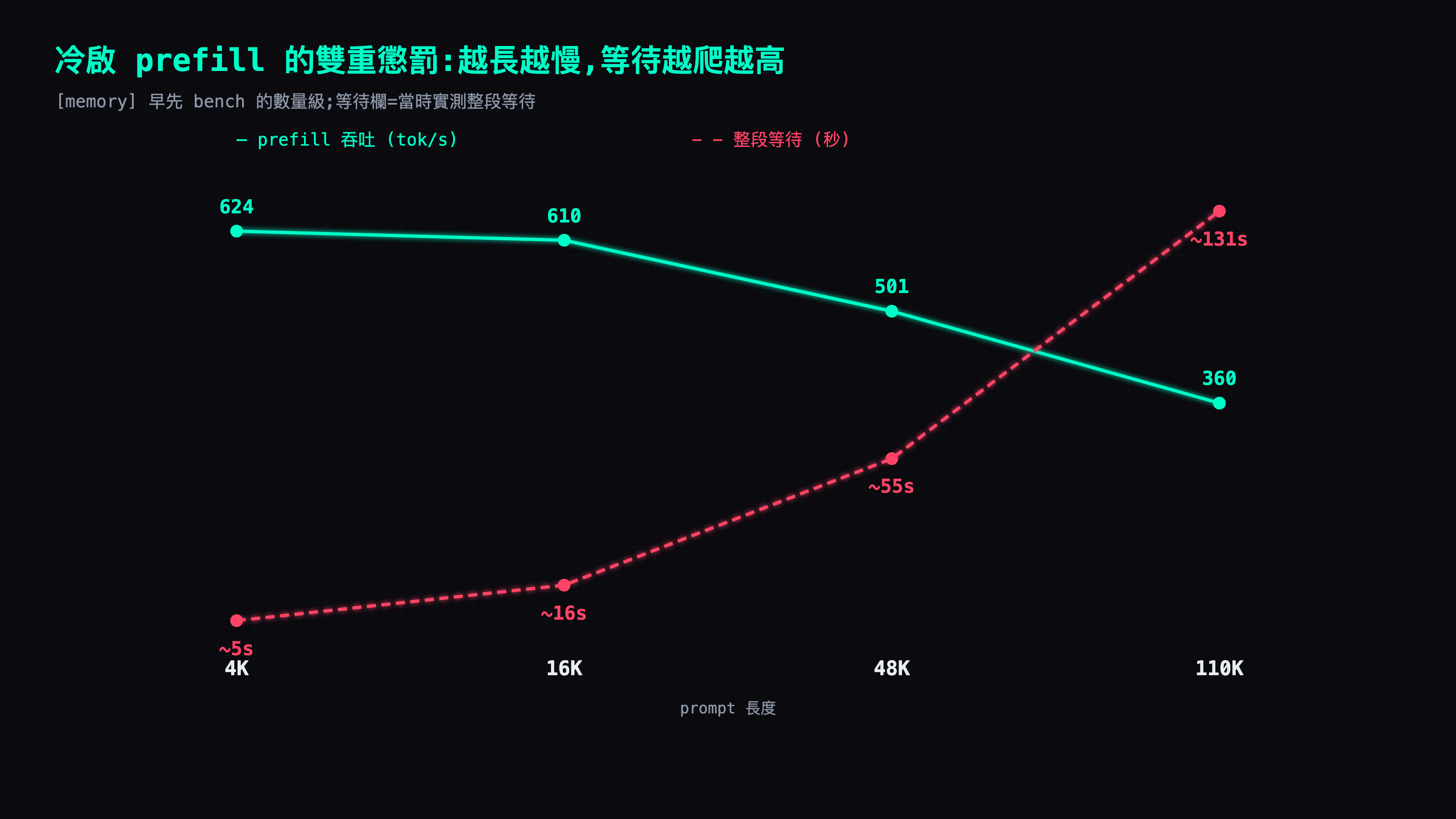
把上表跟前面那張 log 表對起來看,一切就通了:一段四五萬 token 的對話,冷啟整段重算,就是要等個一百多到兩百多秒——這跟 log 裡那幾筆 200+ 秒的冷啟對得上。而暖機命中時,同一段對話接話只要兩三秒。
雪上加霜:多工具回合會把這筆稅乘上好幾倍
agent 還會把這個問題再放大。一個「使用者回合」常常不是一次 API 呼叫就結束——模型要呼叫工具、拿到結果、再想、再呼叫,來來回回。每一次工具往返都是一個新的、更長的 prompt 送進去;在 hybrid 上,每一次 miss 都是一次整段重算。
實測:翻 Hina 的 log,一個使用者回合裡的工具往返次數(tool_turns)常態落在 2 到 13 之間——光是 tool_turns=13 就出現了 14 次,忙起來一回合甚至衝到 39 次。一個有 9 次工具往返、每次都 miss 的回合 = 9 倍的重算稅。這也是 #6 工具定義稅那篇算的帳——那 17K 的工具定義,在這種回合裡會被一遍又一遍地重讀。
換個角度看:decode 卡在 bandwidth,能動的只有快取
最後把 decode 這件事擺正。
decode 本身是 bandwidth-bound:不管 context 是 4K 還是 110K,記憶體頻寬都被頂滿(mem clock 釘在 6800MHz),所以 decode 大概都在 ~32 tok/s,跟 context 長短幾乎無關。意思是:你沒辦法靠「縮短 context 讓 decode 變快」來修體感——decode 根本不隨 context 變。
那要修體感,能動的在哪?全部在 TTFT / 快取那一側。 暖機命中,TTFT 兩三秒;冷掉 miss,TTFT 兩百秒。修體感 = 讓更多回合命中快取、別讓快取被清掉。這就是為什麼系列裡有 #6 工具定義稅(那 17K 工具定義能不能不要每回合重算)跟 #5 KV cache 存硬碟(快取要怎麼存才不會蒸發)這兩篇。
而那顆「慢」的光羽為什麼體感反而順?因為它的環境(DeepSeek 自己改的 build,帶自動 disk-KV)能把五萬 token 的前綴在 ~87ms 內從硬碟載回來——它幾乎不付重算稅。
⚠️ 誠實提醒:光羽那 87ms 是在 DeepSeek 自己改的、帶自動 disk-KV 的 build 上量的,不是 stock llama.cpp——這是 infra 不對等,但這恰恰是重點:真正決定體感的是「會不會付重算稅」,不是 decode 多快。 一邊幾乎不付,一邊一付就是 200 秒,decode 那兩倍差距根本不夠看。
一句話結論:體感速度 = TTFT + decode
把這篇收成一句:
decode tok/s 是虛榮指標,你真正感覺到的速度 = TTFT + decode。 在一顆 hybrid 腦上,一次 cache miss 就把整段 prompt 從頭重算,TTFT 在四五萬 context 上可以炸到 200 秒以上——這時候 decode 快兩倍,你一點都感覺不到。我把腦從 14 tok/s 換成 30,體感卻變慢,不是因為新腦爛,是因為我量錯了東西。
| 光羽 / ds4 | Hina(2080 Ti) | |
|---|---|---|
| decode tok/s | ~14 | ~32 |
| cache miss 時的 TTFT | ~87ms(disk-KV 載回) | 冷啟整段重算到 ~230s(實測那批 200-230s) |
| 體感 | 順 | 忽快忽慢:暖機俐落、冷掉卡死 |
挑卡看 VRAM、聊天看 tok/s——但養 agent,你該盯的是 TTFT。
接下來
這篇講的是「為什麼 miss 這麼痛」。解法其實已經寫在系列裡了:#6 工具定義稅拆那筆每回合先吃 17K token 的帳單;#5 KV cache 存硬碟講怎麼讓快取在崩潰重啟後不用整段重算、7 倍速回神。至於這顆慢腦的另一個體感坑——回應慢到連開個漸進式串流都會撞上 Telegram 的 flood control——在 #7。
同系列其他篇:
- (上一篇)在慢腦上開漸進式串流,我把自己撞進了 Telegram 的 flood control
- Gemma 12B vs Qwen 27B:我為什麼放棄 100 tok/s 換 30
- 工具定義稅:還沒開口,就先吃掉 17K token
- KV cache 存硬碟,回神快 7 倍
前傳:
- GTX 970 系列 Part 3:在老卡上,Flash Attention 讓長 context 的 decode 接近翻倍(上一系列我發現 FA 翻轉了「KV cache 的直覺」;這一系列翻轉的直覺,是 decode tok/s 本身)
常見問題
- decode tok/s 比較高,為什麼體感反而比較慢?
- 因為你真正感覺到的速度 = TTFT(time-to-first-token,從你送出到第一個字冒出來)+ decode(之後每秒吐幾個字)。decode tok/s 只量後半段。我這顆 Hina(Qwen3.6-27B,~30-40 tok/s)decode 確實比另一台的 ds4(~14 tok/s)快兩倍多,但只要它 cache miss,就得把整段 prompt 從頭重算,TTFT 在我量到的 ~45-50K context 上會炸到 200 秒以上。前半段一炸,後半段吐得再快你也感覺不到。tok/s 是虛榮指標。
- 為什麼一次 cache miss 就要把整段 prompt 重算?別的模型不是這樣嗎?
- 因為 Hina 的腦是 hybrid 架構(Qwen3.6 = 標準注意力混搭 Gated DeltaNet 線性注意力,帶循環狀態)。mainline llama.cpp 在 hybrid + SWA 模型上「沒辦法重用前綴快取」——視窗一滑動,舊的 token 資訊就丟了,沒辦法只補算新的那段,只能整段重來。這是 llama.cpp 自己在 server log 裡標明的限制(連 PR 連結都給了)。一顆普通 transformer 前綴穩定時不會這樣:它把前綴 prefill 一次、之後一直重用那份快取。所以這不是「context 太長」的病,是「hybrid 不能重用快取」的病。
- 那 decode 的 30-40 tok/s 是假的嗎?
- 不是假的,是被誤用了。decode 本身是 bandwidth-bound——不管 context 是 4K 還是 100K,記憶體頻寬一樣 ~616 GB/s,所以 decode 大概都在那個範圍,跟長短沒關係。問題是它只反映「暖機之後吐字多快」。當一回合的時間被 TTFT 吃掉,decode 再快也救不了體感。要修體感,唯一的旋鈕是 cache / TTFT,不是 decode。
- 這篇是 benchmark 嗎?14 vs 30 是同硬體對比嗎?
- 不是 benchmark,是 case study。14 tok/s 的 ds4 跑在 GB10(Blackwell)、30 tok/s 的 Hina 跑在改裝 2080 Ti(Turing)——兩顆不同模型、兩台不同 GPU,而且 14 那邊的數字是舊 log 的 memory 記錄。所以這不是控制變因的對照,是真實的使用體感:一個 decode 慢但從不重算的腦,體感可以贏過一個 decode 快但會整段重算的腦。當故事讀,別當論文讀。
接著讀
- 2026-06-26[趣味競賽 進階 #5] 別讓助理每次都重讀整本對話:KV cache 存硬碟,回神快 7 倍
對話一長,每傳一句它都要把整段重讀一遍(re-prefill)才回你——重開、被擠掉快取後尤其痛。stock llama.cpp 沒內建把 KV cache 存硬碟(feature 被官方標 not planned),我用一支 60 行的 proxy 騙它做到:restore 比重算快 7×(5K 對話 9.9 秒→1.4 秒)。附:機制、proxy 設計、和為什麼我目前還沒上線它。
- 2026-06-27[趣味競賽 進階 #6] 工具定義稅:還沒開口,就先吃掉 17K token——而且每次重算都重來一遍
我數了一下家裡那個 AI 助理每次回話前的開銷:還沒開始處理我輸入的文字,就先吃掉約 23K token,其中 17K 只是『工具的使用說明書』。更慘的是它是 hybrid 模型,快取一沒命中就把這 17K 從頭重算——一個對話回合可能重算十幾次。這篇講一個被嚴重低估的成本:模型開口前的「打底開銷」。解法不是砍工具,是像技能那樣『用到才載』。
- 2026-06-25[趣味競賽 進階 #4] 量化 draft cache 反而更慢:Qwen MTP 投機解碼的反直覺實測(f16 比 q4 快 34%)
主 KV 我量化成 q4 省記憶體,很合理。那 MTP 的 draft cache 順手也量一下吧——它只是個小草稿,直覺穩賺。測下去打臉:q4 draft cache 29.6 tok/s,不量化的 f16 反而 39.7,還更省記憶體。draft cache 是少數「量化淨虧」的地方。附:量化為什麼會同時拉低速度、acceptance 跟省不到記憶體的三重損失。
- 2026-06-24[趣味競賽 進階 #3] 我把 context 開滿 256K,它載入成功——然後在真實對話裡 crash:一張 22G 改裝卡的 VRAM 偵探故事
模型卡片寫 n_ctx_train=262144。22G 的卡。27B 的 Q4 權重才 15.7GB。算盤一打:開滿 256K 啊,還剩好幾 GB。-c 262144 啟動,載入成功、沒報錯。跑幾輪對話就 503、服務自己重啟。日誌沒有漂亮的 out of memory,只有一行 0xc0000409。free VRAM 一看只剩 170 MiB——剩下的 GB 去哪了?這篇是把它查到底的偵探故事:我原本賴給 context checkpoint,讀了 llama.cpp 原始碼才發現它其實住系統 RAM、真正吃 VRAM 的是 KV cache;free-VRAM 對 context 是非線性的,而真正穩的甜蜜點不是 256K,是 128K。
不想錯過新文章?
訂閱我確保不漏接!
隨時一鍵退訂。