改裝 2080 Ti 22G · part 6
[趣味競賽 進階 #6] 工具定義稅:還沒講話就先吃 17K token,而且每個 cache miss 都重算一次
❯ cat --toc
TL;DR
我數了家裡那顆 agent 腦(雛羽,跑在改裝 2080 Ti 上的 Qwen3.6-27B)每次開口前要付的「入場費」:還沒讀我半個字,prompt 裡就已經坐了約 23K token,其中 17,434 個(實測)只是 39 個工具的 JSON 使用說明書——佔了這個 floor 的約 73%。在正常 transformer 上這是一次性成本(prefill 一次、cache 起來、之後重用)。但這顆是 hybrid 模型,llama.cpp 對 hybrid 做不了 prefix cache 重用,cache 一 miss 就整段從頭重算——這 17K 就跟著重算。而一個 user 回合動不動就跑 6 到 16 次工具回合、實測還飆到過 30 幾次,等於這 17K 在一個回合裡可能被重算十幾次。核心結論有兩個:第一,這是 context 經濟學,不是工具太多的問題;第二,解法不是砍工具,是像 skills 那樣「用到才載」。先說清楚:token 數是 char/4 估計、不是 tokenizer 精算,方向確定、精確值有 ±。
白話導讀:agent 開口前要先付一筆「入場費」
你進一家店,還沒點東西,先收你一筆入場費——這就是我家那顆 agent 腦每次回話前的處境。
它能做很多事:開排程、委派任務、開 terminal、搜尋、操作 kanban 工作板……每一項能力,背後都是一個「工具」。而模型要知道某個工具怎麼用,你就得在每次請求裡,把那個工具的使用說明書(一份 JSON:工具叫什麼、吃哪些參數、每個參數什麼意思)塞進 prompt 裡給它讀。
我掛了 39 個工具。把這 39 份說明書加起來,約 17,434 個 token——這是它「還沒讀到我打的任何一個字」之前,就已經吃掉的開銷。再加上 system prompt,整個「空回合 floor」大概 23K token 起跳。
如果這顆是顆正常的模型,這筆錢只付一次:第一回合 prefill 完就 cache 起來,之後每回合直接重用那塊 cache。問題是我這顆是 hybrid 模型,它沒辦法重用那塊 cache——只要一個 cache miss,它就把整段 prompt(包含那 17K 工具說明書)從頭重算一遍。於是一次性的「入場費」變成了每個 miss 回合都要再繳一次的「稅」。
這篇講的就是這筆稅:它從哪來、為什麼這麼貴、以及為什麼正確的解法不是砍工具。
前言:上一篇把重算的 KV 存起來,這篇來看「被重算的」到底是什麼
上一篇(#5,把 KV cache 存硬碟那篇)講的是:這個 hybrid 模型一 cache miss,就把整段 prompt 從頭重算,TTFT(吐出第一個 token 前的等待)直接爆掉;解法是把算好的 KV 存到硬碟,下次直接讀存檔、不要重算。那篇證明了一件事:重算很貴,貴到值得存起來。
那篇講的是「怎麼讓它別重算」。這篇換個角度,從帳本切進去問:既然每次 cache miss 都得把整段 prompt 重算,那這段 prompt 裡到底裝了什麼、哪一塊最貴?
答案有點出乎意料:最大那塊不是我的對話、不是 system prompt,是工具的使用說明書。
而且我得先把方法講在前頭,免得後面被當成精算:下面所有 token 數,都是 char/4 估計——我抓了一份真實送進模型的 request dump,把它 tools 欄位的字元數除以 4。Qwen 自己的 tokenizer 算會有點出入,但大方向很清楚。當量級看,別當小數點後第幾位的精算看。
解剖這個 floor:工具佔了七成
先把帳攤開。我抓的這份 request dump,是 2026-06-21 晚上一次真實請求送進模型那一刻的完整 body([log])。把它拆開數:
| 項目 | token(估計) | 佔 floor 比例 |
|---|---|---|
| 工具 schema(39 個工具) | ~17,434 | ~73% |
| system prompt(已含 skills 目錄) | ~6,263 | ~26% |
| 空回合 floor 合計 | ~23.7K | — |
⚠️ 一個要講精確的量測細節:這份 dump 的 system 訊息是一整塊 25,052 字元(約 6,263 token),而且它已經把 skills 目錄包在裡面了([log]:
skill_view出現在第 2,184 字元、## Skills區段在第 10,664 字元)。所以別把「system ~6,263」「skills ~3,700」當兩筆相加——skills 目錄是住在 system 那塊裡面的。乾淨、站得住腳的數字就兩個:工具 = 17,434 token(實測)、system+skills 那塊 = 6,263 token(實測),floor ≈ 23.7K。
這個 floor 跑不掉。我去翻了整份 agent log,實測這顆腦在真實對話裡見過最精瘦的一個回合,in= 是 18,427 token([log])。那是一個「使用者只丟了極短一句話、system 區塊也壓到最小」的回合——它還是吃了 18K,而光工具 schema 就 ~17.4K 在那壓著,等於這個最瘦回合裡九成以上(~94%)都是工具說明書。換句話說:就算我一個字都不打、就算把其他能砍的都砍到最小,這顆腦也得先讀完那 17K 的工具說明書。(上面表裡那個 ~23.7K 是這份 dump 當下的快照——system 區塊會隨對話狀態與載入的 skills 浮動,所以「最瘦回合 18,427」比「快照 floor 23.7K」更小,並不矛盾:兩個都指向同一件事——工具 schema 是壓死人的那塊。)

最肥的幾份說明書
那 39 份說明書不是均分的,有幾份特別肥。從同一份 dump 實測,前 12 名([log]):
| 工具 | token(估計) |
|---|---|
| cronjob | 1,802 |
| delegate_task | 1,734 |
| terminal | 1,349 |
| session_search | 1,268 |
| kanban_create | 1,077 |
| skill_manage | 1,036 |
| kanban_complete | 846 |
| execute_code | 676 |
| memory | 544 |
| patch | 482 |
| search_files | 446 |
| send_message | 412 |
光最肥的兩個(cronjob + delegate_task)就 ~3,500 token——比很多人整段對話還長。而且這每一份都得逐回合重新讀給模型聽(下面解釋為什麼)。
順帶一個誠實的小校正:這幾個數字跟我之前 handoff 筆記裡記的(cronjob 1,791、delegate_task 1,732…)差個位數——那是因為我這次重抓 dump 重算,字元數抓得比上次完整一點點。方向、排名一模一樣,我用本次實測的數。
為什麼這變成「每回合」的稅(整篇的重點)
這裡是整件事的核心,也是最容易被當成「廢話、不就一次性開銷嗎」而略過的地方。
- 在正常的 transformer 上:這 17K 工具說明書坐在 prompt 的最前面(prefix),第一回合 prefill 完就被 cache 起來,之後每一回合都直接重用那塊 cached prefix。一次性成本,後面回合幾乎免費。
- 在我這顆 hybrid 模型上:llama.cpp 對 hybrid(混合注意力 + Mamba2/SSM recurrent state)做不了 prefix cache 重用。只要一個 cache miss,它就被迫把整段 prompt 從頭重算——這 17K 工具說明書,跟著一起重算。
這不是我猜的。這正是上一篇(disk-KV 那篇)裡那條 llama.cpp server log:
slot update_slots: forcing full prompt re-processing due to lack of cache data
(likely due to SWA or hybrid/recurrent memory, ...)
而這個限制是有正式來源的:
- PR #13194("kv-cache : add SWA support",已 merged):這條主要是 SWA 的取捨來源——它引入的就是「SWA 模型無法做 context caching(prefix caching、context shift、context reuse),因為視窗滑動時 token 資訊會遺失」。上面那行 log 把 SWA 跟 hybrid/recurrent 並列,SWA 那半就是出自這裡。
- Issue #22746("Eval bug: Qwen 3.6 27B forcing full prompt re-processing due to lack of cache data",狀態 Open):這條才是正中我這顆——Qwen 3.6 27B(就是 forge 跑的同一顆),貼的 log 一字不差就是上面那行,顯示它檢查完所有 checkpoint 都對不上、把 15 個失效 checkpoint 全清掉、然後把整段 53,564-token 的 prompt 從頭重算。多種量化(Q3_K_M / Q4_K_M / IQ4_XS…)都中。
- Issue #20225("Eval bug: Qwen 3.5 Full prompt re-processing on every conversation turn",狀態 Closed):這條是上一代同家族的佐證——Qwen 3.5(hybrid attention + Mamba2/SSM)每個對話回合都被迫整段重算,回報一個 15K-token 的對話每回合要等約 8 分鐘,而不是幾秒。(⚠️ 它標題寫的是「3.5」、狀態 Closed;真正打中 3.6 的是上面那條 Open 的 #22746,別把 3.5 那條的 Closed 讀成「3.6 也修好了」。)
把這條限制套到那 17K 上,稅就現形了。一個 user 回合裡,agent 常常要連續呼叫好幾個工具——做一步、看結果、再做一步,每一步都是一次新的請求、prompt 又長一點。我去數了真實 log:單一 user 回合的工具回合數(tool_turns)實測落在 6 到 16 很常見,而且飆到過 30、34([log])。如果這當中有 9 個回合 cache miss,那就是這 17K 工具說明書,在一個 user 回合裡被重算了 9 次。
至於重算一次要多久?cold prefill 大約 360-624 tok/s([memory]),17,434 token 換算下來,光是把工具說明書重讀一遍,每次 miss 就要花約 28 到 48 秒。
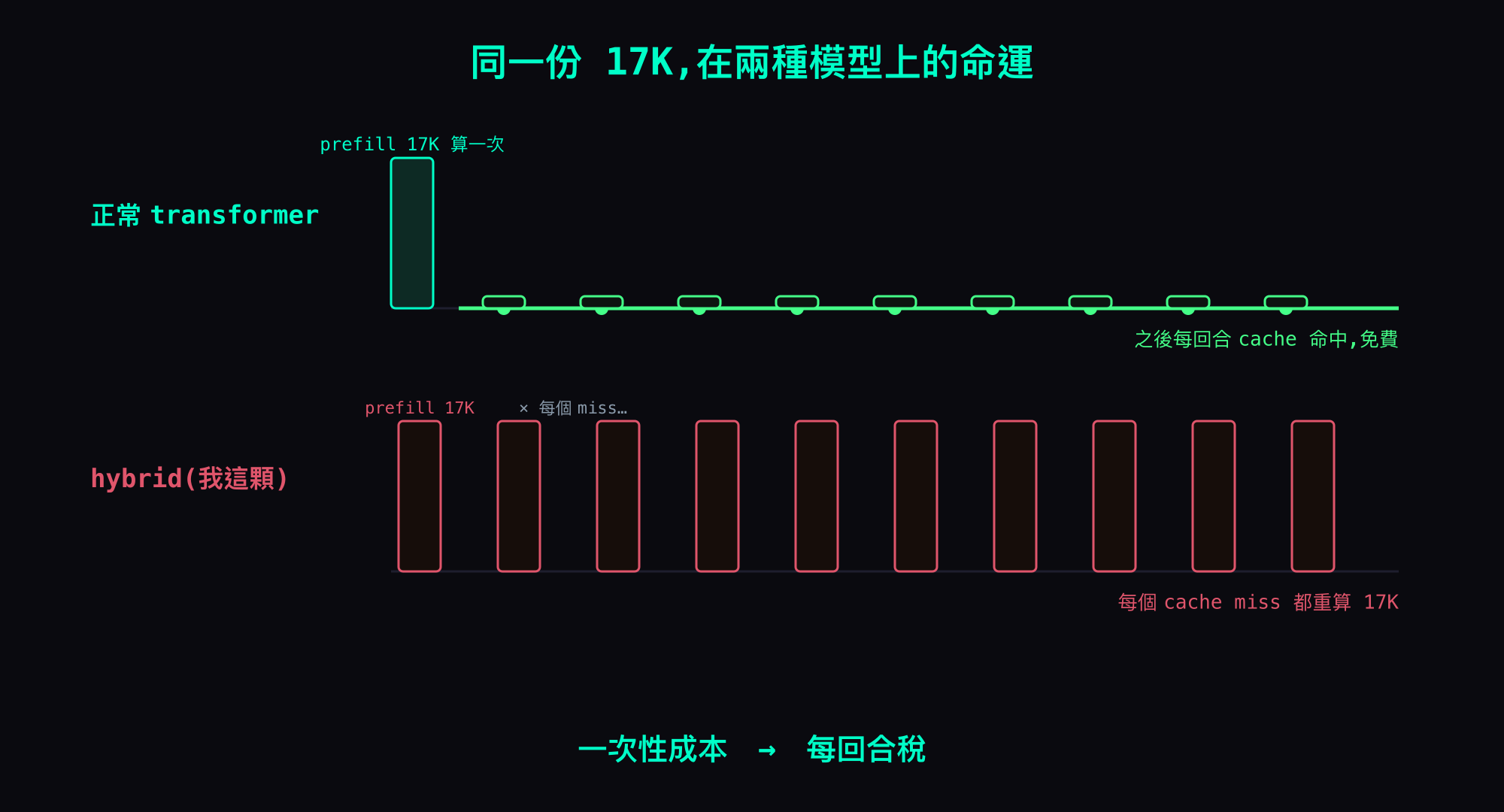
先講清楚:這稅是「陣發」的,不是每回合都 16 倍
我得把話講清楚,免得你帶錯結論走:「重算 16 次」是最壞情況,不是常態。
cache 命中的回合(warm,命中率 98-100%)幾乎不付這筆錢——對話接得上、prefix 還在 cache 裡,工具說明書不用重讀。真正爆的是 cache miss 的回合:對話跳掉、或模型剛 crash 重載把 RAM cache 清空了。所以這筆稅是陣發的——平常很安靜,集中在那些 cold / miss 的回合一次炸開。
別讀成「每回合都重算 16 次工具說明書」。真實的樣子是:大多數 warm 回合幾乎不繳稅,少數 miss 回合一次繳一大筆。但因為 miss 回合的 TTFT 又長又痛(上一篇 disk-KV 那種冷重算動輒幾十秒、長對話飆到分鐘級),這筆「陣發稅」對體感的殺傷力,遠超過它的平均值給你的印象。
正確的解法不是砍工具
看到「73% 是工具」,直覺反應是「那砍掉一半工具不就好了」。這是錯的。
那 39 個工具——cron、委派、terminal、搜尋、kanban、skills 管理……——幾乎每一個都有它存在的理由。砍掉就是把 agent 的能力砍掉。為了省 prefill 把 agent 弄笨,是本末倒置。
真正的解法,這套系統裡其實已經有現成的範本——就是 skills 的做法:
- system prompt 裡只放一份 skill 名字的目錄(很小一塊),不放完整內容。
- 完整的 skill 說明,要等模型真的決定用它、發起呼叫的那一刻才載進來(透過
skill_view;在這份 dump 裡,skill_view出現在 system prompt 第 2,184 字元 [log])。
如果工具也照這個模式設計——第一次呼叫某工具時才把它的 schema 載進來,而不是 39 份全部預先塞好——那個 17K 的 floor 就會塌掉一大半。模型平常只需要知道「我有哪些工具可用」(一份名字清單),要用某個工具的細節時再去查。
這個直覺,其實跟前傳那台老卡的教訓是同一個。GTX 970 系列那篇 RAG bot 我刻意不裝重依賴(沒有 torch、沒有向量資料庫、不碰 LangChain)——能省則省。在 2080 Ti 這顆腦上,咬人的「肥肉」換成了工具 schema,但解法是同一個本能:只載你真的會用到的東西。
另一條路,是把上游那個 hybrid cache 重用的限制修好,讓這 17K 像正常模型那樣只 cache 一次。但那是 llama.cpp 上游要處理的事,不是我在家機上改 prompt 就能解的。兩條路——「工具用到才載」或「修好 hybrid cache」——都比直接砍功能合理。
收尾:這是 context 經濟學,不是工具問題
把這篇講成一句話:
agent 的瓶頸常常不在「它聰不聰明」,而在「它每次思考前要先付多少入場費」。 那份 17K 的工具說明書,在一顆會 cache 的正常模型上是一次性投資;在一顆不會 cache 的 hybrid 模型上,變成一筆每個 miss 回合都要再繳的稅。同一份 schema,放在不同的 cache 架構上,帳算出來天差地遠。
而最反直覺的地方在於:你以為的成本(模型多大、跑多快)都不是這裡真正的主角。真正咬人的是那段你根本沒在看、每個 cache miss 就默默被重算一遍的 prefix。盯著 decode tok/s 看,你永遠不會發現這筆錢正在流走。
至於這塊值得被 cache 的 prefix 到底該存哪(RAM 自動但會蒸發,還是 disk 撐得住重開)——上一篇 disk-KV 已經回答了。這篇補的是另一半:在那塊被反覆重算的東西裡,最肥、最該先處理的,就是這 17K 工具說明書。
誠實聲明(醜話講在前頭)
- token 數是 char/4 估計,不是 Qwen tokenizer 精算。量級與排名確定,精確值有 ±。
- system 與 skills 目錄是重疊的:那份 dump 的 system 區塊已經包含 skills 目錄,所以別把 17,434(工具)+ 6,263(system)+ skills 三筆相加。乾淨的帳是:工具 17,434 + system(含 skills)6,263 ≈ 23.7K floor。
- 「重算 16 次」是最壞情況:warm 回合(命中 98-100%)幾乎不繳稅,所以這稅是陣發的、集中在 cold/miss 回合,不是每回合 16 倍。
- tool_turns 數字是 snapshot:6-16 常見、飆到過 30/34,是某次 agent log 區間的實測分佈,不同時段會變。
- 39 個工具是這顆 sib(雛羽)的設定,別的 sib 工具數不一樣。
- cold prefill 360-624 tok/s 是 [memory] 數字,「每次 miss 27-47 秒」是用它換算出來的量級,不是逐次計時。
我能放心給你的就是這些:一份真實 request dump 拆出來的工具帳(本次重新實測)、整份 agent log 撈出來的最短回合與 tool_turns 分佈、加上兩條解釋「為什麼 hybrid 不能 cache」的上游 GitHub 來源。當 context 經濟學的一個 case 讀,不當精算報表讀。
同系列其他篇:
- (上一篇 · #5)別讓助理每次都重讀整本對話:KV cache 存硬碟,回神快 7 倍(本篇這 17K,正是它在解的「被重算的 prefix」裡最肥的一塊)
- (#3)我把 context 開滿 256K 然後 crash:22G 卡的 VRAM 偵探(context 經濟學的另一面:吃的是 VRAM)
前傳:
- GTX 970 系列:用一張老卡架部落格 RAG 客服(不裝 torch、不用向量資料庫)(「只載你真的會用到的東西」同一個本能)
常見問題
- 什麼是「工具定義稅」?為什麼是稅、不是一次性成本?
- agent 能呼叫的每一個工具,都要在 prompt 裡塞一份 JSON schema(名稱、參數、說明),好讓模型知道怎麼用。我家這顆腦掛了 39 個工具,光這些 schema 就約 17,434 個 token(本次實測)。在一顆正常的 transformer 上,這 17K 坐在 prompt 最前面,prefill 一次就被 cache 起來、之後每回合重用——是一次性成本。但我這顆是 hybrid 模型,llama.cpp 對 hybrid 沒辦法做 prefix cache 重用,只要 cache miss 就把整段 prompt 從頭重算——這 17K 就跟著被重算。所以它從「一次性成本」變成「每個 cache-miss 回合都要再繳一次的稅」。
- 那把工具砍掉不就好了?
- 別這樣解。那 39 個工具(cron、委派、terminal、搜尋、kanban、skills…)幾乎每個都有用,砍掉就是把 agent 變笨。真正的解法是『用到才載』——這正是 skills 已經在做的事:system prompt 裡只放一份 skill 名字的目錄(很小),完整的 skill 內容要等真的呼叫時才載進來。如果工具也這樣設計(第一次呼叫才載 schema,而不是全部預先塞好),這個 floor 就會塌掉一大半。另一條路是把上游 hybrid 的 cache 重用修好,讓這 floor 像正常模型那樣只 cache 一次。兩條路都比砍功能好。
- 這些 token 數字是精確的嗎?
- 是估計值,而且我講清楚方法:我抓了一份真實的 request dump(送進模型那一刻的完整 JSON),把 tools 欄位的字元數除以 4 當 token 估計。Qwen 自己的 tokenizer 算出來會有點出入,但方向沒有任何模糊空間——工具 schema 就是這個 base context floor 的絕大多數。另外從 agent log 撈到,這顆腦在真實對話裡見過最精瘦的一個回合 in= 是 18,427 token,而光工具就 ~17.4K,等於說一個『什麼都還沒講』的回合,九成以上都是工具說明書。