改裝 2080 Ti 22G · part 3
[趣味競賽 進階 #3] 我把 context 開滿 256K,它載入成功——然後在真實對話裡 crash:一張 22G 改裝卡的 VRAM 偵探故事
❯ cat --toc
- 白話導讀:「模型支援的 context」不等於「你的卡跑得穩的 context」
- 前言:接著上一篇那個 503,把 crash 查到底
- 算盤:22GB - 15.7GB,中間那幾 GB 不就空著嗎
- 503 的鬼打牆:日誌裡沒有 OOM,只有一行 0xc0000409
- 嫌犯一:我先賴 context checkpoint——讀了原始碼才發現它根本不在 VRAM
- 嫌犯二:free-VRAM 對 context 是非線性的(這篇的主圖)
- 破案 + 128K 甜蜜點:壓力測試全過
- 誠實轉折:128K 仍偶發一次 crash,我不假裝完美
- 機制:為什麼這顆腦的 checkpoint 既大又愛失效
- 換別張卡也能用的判斷
- 接下來
TL;DR
模型卡片寫著 n_ctx_train=262144(256K)。卡有 22GB。27B 的 Q4 權重才 15.7GB。算盤一打:開滿 256K 啊,還剩好幾 GB。-c 262144 啟動——載入成功、沒報錯,爽。跑幾輪對話就 503,服務自己重啟。日誌裡沒有漂亮的 out of memory,只有一行 Windows Event 0xc0000409。nvidia-smi 一看:free VRAM 只剩約 170 MiB。剩下的 GB 去哪了?這篇把它查到底。三條線索:(1) 真正吃 VRAM 的是 KV cache(隨 context 線性長大)——我一開始賴給 context checkpoint,讀了 llama.cpp 原始碼才發現 checkpoint 其實住系統 RAM(std::vector<uint8_t>、從 GPU 讀回 host)、不是 VRAM;(2) free-VRAM 對 context 是非線性的——256K=170 / 200K=164 / 128K=約 2GB,降 56K 沒用,降到 128K 才鬆開;(3) checkpoint 為什麼又大又愛失效,根因在 hybrid 架構(對應 llama.cpp issue #22746,Open、正中 Qwen 3.6 27B;先例 #20225 是 3.5、已 closed)——那是下一篇 TTFT 的線。破案後 128K 是唯一穩的甜蜜點——但我不假裝完美:128K 仍偶發一次 crash,根因待抓,crash-log 已架著等下次抓。
白話導讀:「模型支援的 context」不等於「你的卡跑得穩的 context」
買改裝 22G 卡的人,十個有九個會做同一件事:看到模型卡片寫「最大支援 256K context」,就想把它開滿。我也是。算盤聽起來無懈可擊——卡有 22GB、27B 的權重壓到 Q4 才 15.7GB,中間還空著好幾 GB,那 256K 當然開得起來。
-c 262144,啟動。它真的載入成功了,一個錯都沒報。 這就是陷阱:在這種事情上,「載入成功」不是綠燈,只是「還沒撞牆」而已。跑幾輪真實對話,服務就自己 crash 重啟,client 那頭吃到 503 Loading model。我去翻 VRAM(顯卡上的記憶體),發現整張 22G 的卡 free 只剩 170 MiB——一絲頭髮的寬度。剩下那幾 GB 不是被權重吃掉的。我第一個賴的是 context checkpoint,結果查到最後翻案:真兇是 KV cache(模型用來記住整段對話的那塊 VRAM,對話越長吃越多),它隨 context 線性長大;checkpoint 根本不住 VRAM(我去讀了 llama.cpp 原始碼才確定)。
前言:接著上一篇那個 503,把 crash 查到底
上一篇講「為什麼選慢的 Qwen 27B 當 agent 腦」時,我埋了一條線:log 裡撈得到一條 503 Loading model,我說那對應「context 爆掉、服務 crash 後重新載入模型」,是後面硬核篇的主題。這篇就是那個主題。
設定接著前兩篇:一張二手改裝的 22G RTX 2080 Ti(Turing sm_75、記憶體頻寬約 616 GB/s),裝在一台只有 16GB RAM、六核 CPU 的廉價老桌機上,跑 llama.cpp、serve 一顆 abliterated 的 Qwen3.6-27B Q4_K(約 15.7GB)當常駐 agent 腦。
開工前先把這顆模型的規格從 forge 撈出來確認(/v1/models 的 metadata,live):
n_ctx_train = 262144 # 模型原生訓練到 256K
n_ctx = 131072 # 我現在實際開的是 128K
n_vocab = 248320
n_params = 27.32B
size ≈ 16.8 GB # Q4_K 權重在 disk 上的大小
n_ctx_train=262144 是白紙黑字的「模型支援 256K」。底下那個 n_ctx=131072 是劇透——我現在開的是 128K,不是 256K。為什麼從 256K 退到 128K,就是這篇的全部。
算盤:22GB - 15.7GB,中間那幾 GB 不就空著嗎
直覺的帳是這樣算的:
- 卡:22528 MiB(改裝 22G)
- 權重:Q4_K 約 15.7GB
- 剩:約 6GB
「6GB 拿來放 KV cache、開滿 256K,綽綽有餘吧?」我一開始就是這樣想的,而且這個直覺錯得很合理——它只算了權重,沒算 runtime 要的那一大票暫存。
啟動時 llama.cpp 還貼心地丟了一行 warning(verbatim):
n_ctx_seq (131072) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
(這行是我現在開 128K 時的紀錄,所以它在抱怨「你沒開到模型上限」。我當初開 256K 時是真的把 -c 設到 262144 的——那次也是順順地載入成功,沒報任何錯。這就是第一個陷阱:n_ctx_train 是模型的能力,不是你的卡的能力;載入成功更不是。)
503 的鬼打牆:日誌裡沒有 OOM,只有一行 0xc0000409
開 256K 跑了幾輪對話之後,事情開始不對。再跑,503。又跑,又 503。服務自己重啟了。
最先卡住我的是:日誌裡根本沒有漂亮的 out of memory。 沒有 CUDA OOM、沒有 ggml 的 alloc 失敗訊息,只有 Windows Event Log 裡冷冰冰一行 0xc0000409——一個 fail-fast abort 的 status code(經 ucrtbase,看起來是 llama.cpp 自己 abort,疑似 GGML_ASSERT 或某個沒被捕捉的例外;這個歸因是推測,我只能確定「fail-fast abort + 自動重啟」這件事)。
然後我去看 nvidia-smi:free VRAM 只剩約 170 MiB。
權重才 15.7GB,free 卻只剩 170 MiB。剩下的去哪了?
嫌犯一:我先賴 context checkpoint——讀了原始碼才發現它根本不在 VRAM
第一個嫌犯,是我當初算盤裡完全沒算進去的東西:context checkpoint。
簡單講,llama.cpp 為了不要每輪對話都從頭重算整段 prompt,會把對話中間的計算狀態快取下來,下一輪直接從快取接回來、不用整段重算。這個快取就是 context checkpoint,而且它不小。
到底多大?本次在 forge 上實測撈了一串 checkpoint 事件的 verbatim log:
created context checkpoint 1 of 8 (... size = 298.773 MiB)
restored context checkpoint (... size = 268.442 MiB)
erased invalidated context checkpoint (... size = 268.646 MiB)
一串樣本落在 248 ~ 299 MiB 之間,還隨對話位置往後漲(早期較小、後面較大)。每個 ~280 MiB、池子預設開到一堆——我當下的直覺很順:「就是這東西把 VRAM 吃光的啊。」(順帶把舊筆記那個「約 200 MiB」校正成實測的 250-300。)
然後我去讀了 llama.cpp 原始碼,當場翻案。 checkpoint 的結構 common_prompt_checkpoint(在 common/common.h)裡,存狀態的主要就是這兩塊 host buffer(target / draft):
std::vector<uint8_t> data_tgt;
std::vector<uint8_t> data_dft;
std::vector<uint8_t> 是系統 RAM,不是 VRAM。建 checkpoint 走的是 llama_state_seq_get_data——把 KV/recurrent state 從 GPU 讀回 host buffer;log 印的 size = 298 MiB 是 host RAM 的佔用,不是顯卡上的。換句話說,checkpoint 池吃的是那台機器的 16GB 系統記憶體(這是它自己的一條壓力,後面會提),但它從頭到尾沒佔到 VRAM 一個 byte。 我原本的直覺錯了,而且錯得很合理——名字裡有「context」、log 又印 MiB,誰不會以為它在卡上。
⚠️ 自我校正:我筆記跟初稿都寫 checkpoint 是 VRAM-resident,讀 source 後確定錯了——它在 host RAM。這條翻案直接換掉了這一節的兇手:不是 checkpoint,是下面這個。
那 VRAM 到底被誰吃掉?KV cache。 KV cache 才是貨真價實 VRAM-resident、而且隨你開的 context 線性長大的東西。那 6GB 的「空間」,256K 的 KV cache 幾乎整碗端走,只給我留 ~170 MiB。對話短時一切正常;一旦真實負載讓某個 runtime 暫存(forward pass 的 compute buffer,尤其 full-reprocess 一段長 prompt 時)要再多吃一點 VRAM,170 MiB 這條髮絲根本擋不住 → abort → 服務重啟 → client 吃 503。鬼打牆破案,只是兇手換了人。
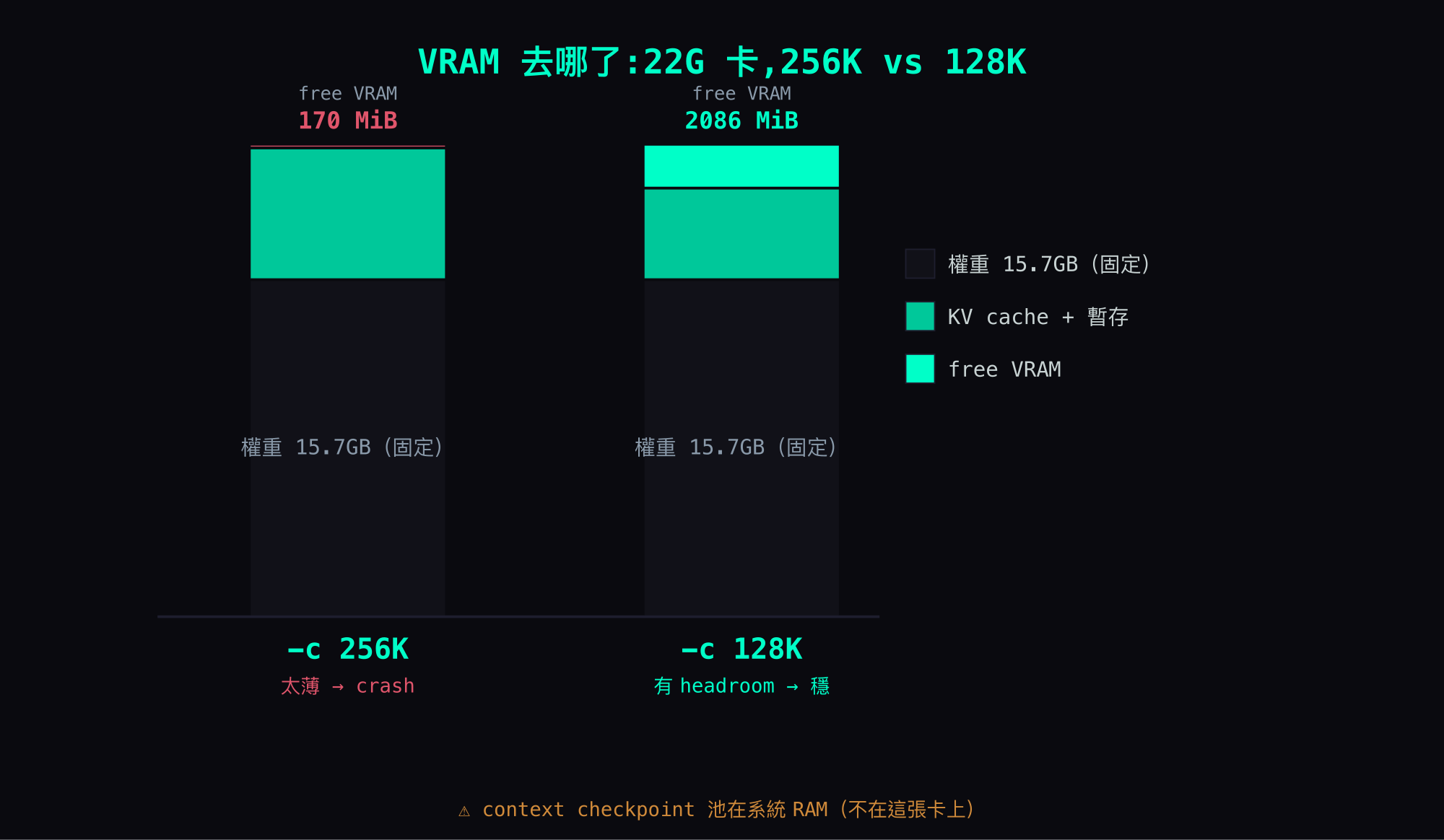
嫌犯二:free-VRAM 對 context 是非線性的(這篇的主圖)
抓到「KV cache 才是吃 VRAM 的兇手」之後,我以為解法很簡單:那就退一步,別開 256K,開 200K 嘛,KV 少一截、降 56K 總該擠出點 headroom 吧?
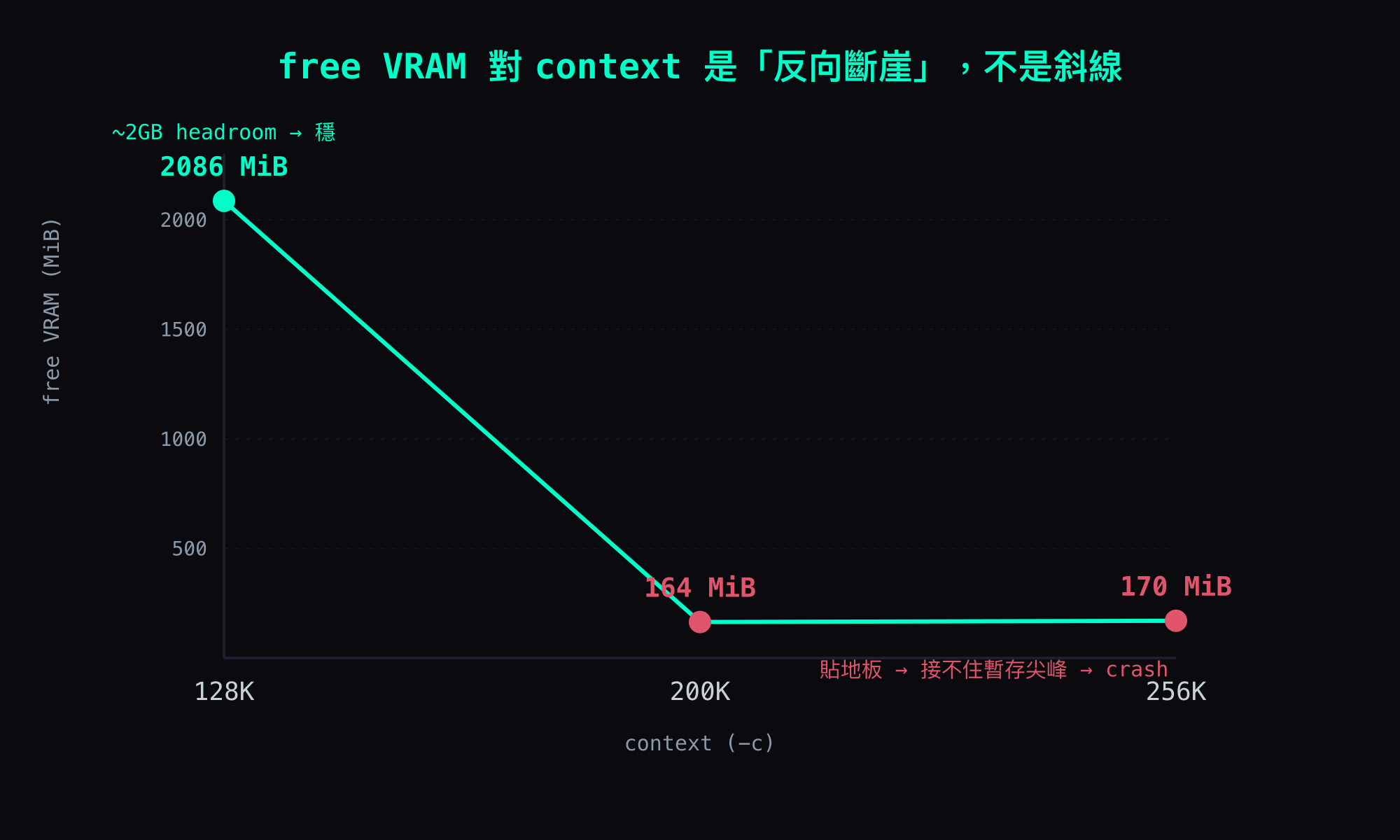
實測打臉。三個 context 設定量到的 free VRAM:
context (-c) | free VRAM | 註 |
|---|---|---|
| 256K (262144) | 170 MiB | 載入成功,但對話一長就在我的負載下穩定 crash |
| 200K | 164 MiB | 降 56K,headroom 幾乎沒變(甚至更低) |
| 128K (131072) | 約 2GB(live 復測 2086 MiB) | 唯一穩;runtime 暫存有充足 headroom |
讀這張表會嚇一跳:256K → 200K,降了 56K context,free VRAM 從 170 變 164——根本沒換到 headroom。 但 200K → 128K,只多降 72K,free 卻從 164 一口氣跳到約 2GB。 這條曲線不是斜的直線,是一道斷崖:200K 跟 256K 都貼在地板上,只有降到 128K 才整個跳起來。
為什麼會非線性?因為你縮 context 省下來的 KV cache,在 200-256K 那個區間,會被別的 VRAM 暫存(compute / graph buffer、draft state,還有 allocator 的對齊與保留)默默吃回去——你以為降 context 在還 headroom,其實只是把 VRAM 從一個口袋挪到另一個口袋(注意:checkpoint 池不在這串裡,它在系統 RAM)。要降到夠低、低過那些暫存的需求門檻,free 才會真正鬆開。
⚠️ 誠實標:
256K=170跟200K=164這兩個數字是單組量測、沒有 live 復測;128K=2086是 live 雙確認過的。要更嚴謹可以在 forge 上各-c跑一次復測。但「128K 才真正鬆開、256K/200K 都貼地」這個非線性的形狀,結論本身是穩的。
破案 + 128K 甜蜜點:壓力測試全過
既然 128K 才真正有 headroom,我就把 daily 退回 128K,然後對它做了一輪壓力測試(2026-06-22),想確認它是真穩、不是運氣:
| 測試 | 內容 | 結果 |
|---|---|---|
| 同時多請求 | 4 個請求(--parallel 1,排隊處理) | 全回 OK |
| checkpoint flood | 連續 10 × 8K | LRU 正常淘汰(erased invalidated → created),不 crash |
| 近上限 prefill | 一發 110K | 不 crash |
| VRAM 穩定度 | 全程監看 | 紋風不動,約 2086 free |
checkpoint flood 那一項特別有意思:連灌 10 段 8K 進去,log 裡可以看到 checkpoint 池在做 LRU 淘汰——created context checkpoint N of 8 配上 erased invalidated context checkpoint。這證明了一件事:checkpoint 池是有上限的(--ctx-checkpoints 8,從預設降下來),滿了就 LRU 踢舊的,不會無限長大。 但記得上一節翻的案:這個池在系統 RAM 不在 VRAM——8 × ~280 MiB ≈ 2.2GB 是 host RAM 的尖峰,在那台 16GB 機器上是要顧的一條線(所以我把它從 32 降到 8),但跟這張卡的 VRAM free 一點關係都沒有。
128K 之所以穩,穩在 VRAM 那邊:KV cache 矮了一截,留下約 2GB 真正的 VRAM headroom,接得住 forward pass 那些暫存尖峰。256K 之所以爆,反過來——free 只剩 170 MiB,薄到接不住任何一次暫存尖峰。
誠實轉折:128K 仍偶發一次 crash,我不假裝完美
如果這篇到這裡就收,那會是一個太乾淨的故事。但真相有個轉折,而且我覺得這個轉折比「完美收尾」更值得寫。
128K 不是 100% 不 crash。 壓力測試全過之後,我仍在一次真實負載下(input 約 54K)觀察到一次 crash:同樣是 Windows Event 0xc0000409(fail-fast abort)。crash-log 我已經架好了(留 stderr 的 .prev-<時間> 截檔 + 一份 service 事件 log),但這次沒抓到新的 ggml 錯誤行——事件 log 只記到兩次乾淨的重啟時間戳:
2026-06-22T01:45:29 starting qwen-128k
2026-06-22T02:12:45 starting qwen-128k
兩次重啟、相隔約 27 分鐘,都自動恢復了,但那次 crash 的 root cause 我還沒 100% 確認。
所以正確的講法是:128K 把 crash 從「開 256K 時每隔幾輪必爆」壓成「偶發一次、根因待抓」,不是「治好了」。對一個常駐 agent 來說,「偶發一次 + 自動重啟」可以接受(client 偶爾吃一次 503、retry 就回來);「每隔幾輪必爆」不行。我把限制全攤開,那次 128K 的 crash 不藏。
機制:為什麼這顆腦的 checkpoint 既大又愛失效
最後一塊拼圖:為什麼這顆腦的 checkpoint 又大(吃系統 RAM)、又這麼容易失效要重算?線索指向架構。
Qwen3.5/3.6 是 hybrid 模型——不是純 transformer 的 full attention,而是 linear/recurrent attention(類 Mamba2/SSM 的 recurrent memory)混上部分 full attention。這個混血設計,正好能解釋前面那一連串現象。
而且這不是我一個人的怪事。llama.cpp 上有一個還開著、而且講的就是同一顆模型的 issue——#22746,"Eval bug: Qwen 3.6 27B forcing full prompt re-processing due to lack of cache data"(Open)——標題裡的 model 跟錯誤訊息,跟我 live log 看到的一字不差。
再往前一個,是同家族的 Qwen 3.5 版本 #20225,"Eval bug: Qwen 3.5 Full prompt re-processing on every conversation turn"(2026-03-08 開、當天即以 completed 結):多輪對話每一輪都被迫 full prompt re-processing,一段 15k-token 的對話每輪要重算約 8 分鐘。issue 裡指的成因是 "the recurrent memory's pos_min always exceeding the SWA-based pos_min_thold threshold"——白話講:checkpoint 那套邏輯本來是為 SWA(sliding-window attention)設計的,沒正確處理 hybrid 模型 recurrent memory 的語義,於是 checkpoint 動不動就被判定失效、整段重算。
⚠️ 講清楚版本:我這顆腦跑的是 3.6,對得上的活 issue 是 #22746(open、同 model)。#20225 標的是 3.5、而且已 closed——我引它是當「同家族先例」,因為它把
pos_min那層成因講得最清楚,不是說它是 3.6 的 issue。
而 live log 也真的抓到 full-reprocess 正在發生(verbatim,跟 #22746 標題的訊息同一行):
forcing full prompt re-processing due to lack of cache data
(likely due to SWA or hybrid/recurrent memory, ...)
一句話收束這條機制:hybrid 架構讓 checkpoint 既大(要存 recurrent memory 的狀態)又愛失效(checkpoint 邏輯沒對齊 hybrid 語義)。 「既大」吃的是系統 RAM(16GB 機要顧),「愛失效」害你一 miss 就整段重算、TTFT 飆到分鐘級。注意這跟前面那個 VRAM 兇手是兩條不同的線:VRAM 不夠是 KV cache 害的(這篇主題);checkpoint 愛失效 → 重算 → 為什麼 30 tok/s 體感比別台 14 還慢,是下一篇硬核篇的主題。 至於那次 crash 的唯一 root cause(0xc0000409),我前面已經誠實標了還沒 100% 確認——這條機制是「能解釋現象」,不是「已證實的唯一兇手」。
換別張卡也能用的判斷
把這篇濃縮成幾條,換別張卡、別個模型也能套:
- 「模型支援的 context」≠「你的卡能穩跑的 context」。 真正的天花板是 VRAM headroom 要放得下隨 context 線性長大的 KV cache + 它的 runtime 暫存(compute buffer / draft state),不是權重塞得下就好。
- 載入成功不是綠燈,只是還沒撞牆。 Hybrid 模型的 KV cache 是隨 context 動態長大的;要在真實長對話 + 同時多請求 + checkpoint flood 下壓測,別只看冷啟那一下沒報錯。
- free-VRAM vs context 可能是非線性的。 別假設「降 context 一定線性換 headroom」;實測曲線,可能要降一大階(這裡是 200K → 128K)才有感。
- 分清楚兩塊記憶體,各自留 headroom。 VRAM 要留給隨 context 長大的 KV cache + compute buffer(這是 256K 爆的地方);系統 RAM 要留給 context checkpoint 池(每個 ~280 MiB、
--ctx-checkpoints 8下8 × ~280 ≈ 2.2GB,16GB 機尤其要顧)。最容易踩的雷就是把這兩塊混為一談——我自己一開始就把 host-RAM 的 checkpoint 當成 VRAM 兇手。挑卡看「權重 + KV + VRAM 暫存」,挑機器別忘了系統 RAM。
接下來
這篇把那條 170 MiB 的髮絲查到底:真兇是 KV cache 吃 VRAM(checkpoint 其實住系統 RAM,我讀 source 翻過案)、free-VRAM 對 context 非線性、而 checkpoint 又大又愛失效的根因在 hybrid 架構。但故事還有一半沒講——checkpoint 一 miss 就要整段重算,這正是「30 tok/s 的 decode 速度,體感卻比別台 14 tok/s 還慢」的兇手:你看到的不是 decode,是 TTFT。那是下一篇硬核篇的主題。
這篇跟 GTX 970 系列是同一個母題的兩端:那邊是 4GB Maxwell + SWA 的「小卡 context 經濟學」,這邊是 22GB Turing + hybrid。卡大了一個量級,但「context 不是你設多大就多大」這件事,一點都沒變。
同系列其他篇:
- (上一篇)我把 100 tok/s 換成 30:快的 Gemma 12B 做完事就走人,慢的 Qwen 27B 才肯收尾(本篇那個 503 就是從那邊埋的線)
- 系列開篇:NT$11k 改裝卡養一顆 27B agent(這顆腦怎麼來的)
- (下一篇 · 硬核篇)為什麼 30 tok/s 體感比 14 還慢:checkpoint miss、full reprocess 與 TTFT
前傳:
- GTX 970 系列 Part 3:在老卡上 Flash Attention 讓長 context decode 接近翻倍(同樣是「小卡 context 經濟學」的母題)
常見問題
- 模型支援 256K context,我的 22G 卡為什麼開不到 256K?
- 因為「模型訓練支援的 context」跟「你的卡能穩跑的 context」是兩回事。256K 在這張卡上是「載入得起來」(不是 load-time OOM),但載入後 free VRAM 只剩約 170 MiB。真正的天花板不是權重塞不塞得下,是有沒有 headroom 放得下隨 context 線性長大的 KV cache——256K 的 KV cache 把那 6GB 幾乎吃光,只剩約 170 MiB,薄到任何一次 runtime 暫存的尖峰都可能把它推爆。(我一開始賴給 context checkpoint,後來讀原始碼發現 checkpoint 其實住系統 RAM、不是 VRAM,內文有交代。)
- 什麼是 context checkpoint?它是不是把 VRAM 吃掉的兇手?
- 不是。context checkpoint 是 llama.cpp 為了避免每輪對話都從頭重算 prompt,把對話中間狀態快取下來的機制(暖 restore)。但讀 llama.cpp 原始碼(`common_prompt_checkpoint`)會發現它存在系統 RAM(`std::vector<uint8_t>`,從 GPU 讀回 host),不是 VRAM——每個約 250-300 MiB,吃的是那台 16GB 機器的系統記憶體。它在 hybrid(linear/recurrent + 部分 full attention)模型上既大又容易失效,是下一篇「TTFT 為什麼爆」的主角;但它不是這篇 VRAM 不夠的兇手,真正吃 VRAM 的是 KV cache。
- 那把 context 從 256K 降到 200K,是不是就有 headroom 了?
- 幾乎沒用。實測 256K 留 ~170 MiB free、200K 留 ~164 MiB——降了 56K 幾乎沒換到任何 headroom(KV 縮的被別的暫存吃回去了)。free-VRAM 對 context 是非線性的:要一路降到 128K,free 才真正鬆開到約 2GB。所以別假設「降 context 一定線性換 headroom」,得實測曲線,可能要降一大階才有感。
- 128K 就 100% 不會 crash 了嗎?
- 不能這樣講。128K 把 crash 從『每隔幾輪必爆』壓成『偶發一次、根因待抓』——壓力測試(同時多請求、checkpoint flood、近上限 prefill)全過、VRAM 全程紋風不動約 2GB free;但仍觀察到一次真實負載下的 crash(0xc0000409),已自動重啟恢復、根因尚未 100% 確認。128K 是目前唯一穩的甜蜜點,不是「保證零 crash」。