改裝 2080 Ti 22G · part 2
[趣味競賽 進階 #2] 我把 100 tok/s 換成 30:快的 Gemma 12B 做完事就走人,慢的 Qwen 27B 才肯收尾
❯ cat --toc
TL;DR
選本地模型,我跟所有人一樣先看 tok/s。Gemma 12B QAT 跑 90-100 tok/s,爽。可是當我把它當 agent 腦掛上 kanban 工作板,它做完任務的「內容」就結束——寫完檔案、跑完整理,但 board 上那張卡永遠停在 in-progress,從不回頭呼叫 kanban_complete。換上慢三倍的 Qwen3.6-27B(~30 tok/s),board 突然就乖了。核心洞察有兩層:第一,「忘記呼叫工具」不會留錯誤行——遺漏是隱形的,所以你看 log 的成功計數會被騙(grep 數得到的看得見失敗只是冰山一角,我差點把它當失敗總數報出去)。第二,這不是「換 27B 就全好」:兩個腦在同一套 kanban 測試都是 2/3,差別在 Qwen 成功時乾淨一次就過、Gemma 要 retry;而 Qwen 唯一掛掉那張,改一下 prompt 就過了——所以連那個失敗都指向「車子問題,不是引擎笨」。先說清楚:這是 case study 不是 benchmark,Gemma 重度失敗期的 log 已被 rotate,我給的是體感 + 撈得回的一手碎片。
白話導讀:吞吐量是回話速度,不是守紀律的能力
所有人挑本地模型,第一眼都看 tok/s——一秒吐幾個字。我也是。所以我一開始給家裡那顆 agent 腦選了 Gemma 12B:90 到 100 tok/s,字嘩啦嘩啦地噴,誰不想要快的。
問題是,我這顆腦不是拿來聊天的,是拿來當 agent——掛在一塊 kanban 工作板上,接到任務、做完、然後要回頭跟「主管」(工作板)回報一聲:做完了就呼叫 kanban_complete 把卡標成完成、做不下去就呼叫 kanban_block 說卡在哪。Gemma 把前面那段做得飛快,但最後這個「回報」動作它常常就……忘了——既沒說「我做完了」,也沒說「我做不下去」。結果板子上沒人知道它到底怎樣,卡片就永遠卡在「進行中」。
換成慢三倍的 Qwen 27B,board 反而乖了。這篇講的就是這個反直覺的選擇:當一顆腦要在長 context 裡持續守一套程序(做完 → 收尾 → 標狀態),而不只是回一段漂亮的話,tok/s 根本不是你該盯的數字。
順帶一個小插曲:連我自己回頭查 log 想證明這件事,都差點被 grep 騙——因為「忘記」這件事,log 裡是完全隱形的。
前言:接著上一篇那顆 27B 腦,講「為什麼是 27B」
上一篇講的是那顆 27B 腦怎麼來的:一張二手改裝的 22G 2080 Ti,剛好夠在廉價老桌機上養一顆常駐 agent。但我跳過了一個問題——為什麼是 27B? 既然這台只塞得下一顆,而 Gemma 12B 明明快得多,為什麼最後選了慢的那顆?
這篇就是補回那個決定。而且我得先把話說在前頭,因為這是寫這篇最容易誤導人的地方:
這不是一篇 benchmark。 我沒有跑 controlled paired eval,也沒有明確的成功率數字。更糟的是——Gemma 重度失敗那段時期(6/20 那幾天)的 agent.log 已經被 rotation 沖掉了。我現在能撈回的 log 裡,Gemma 反而看起來大致正常。所以我不能告訴你「Gemma 失敗 X 次、成功率 Y%」。
那為什麼還寫?因為失敗的痕跡被沖掉,本身就是這篇的核心洞察——我下面會講。我給你的,是養這顆 agent 兩天的體感,加上撈得回的一手產出物(雛羽自己寫在 disk 上的派工檢查單),再加上一組同一套 kanban 測試在兩個腦上跑出來的對照截圖。當 case study 讀,別當數字讀。
誘餌:Gemma 12B 那 90-100 tok/s 真的很爽
先講清楚為什麼一開始選 Gemma。
退役那顆腦是 Gemma 4 12B QAT(Huihui abliterated q4_0),@262K context,decode 90-100 tok/s,還內建 vision + audio。在這張改裝 2080 Ti 上,12B 塞起來很寬鬆,字噴得又快又順。當聊天助手、當隨手問東西的小幫手,它真的爽。
⚠️ 先擋個但書:這個 90-100,跟下面 Qwen 的 30-40,都是 memory 裡的數字,不是本次同硬體 paired 重測。當「賣點對比」看就好,別當 controlled benchmark 的軸。
所以我那時的盤算很單純:同一張卡,既然 12B 又快又裝得下,幹嘛挑慢的?
翻車:它做完事,就走人
把 Gemma 掛上 kanban 工作板之後,問題就浮出來了。
工作流程很簡單:雛羽(這顆 agent 的名字)接到一張卡 → 做完上面的任務 → 最後一步呼叫 kanban_complete,寫一兩句 summary,把卡片標成完成;做不下去就呼叫 kanban_block 說明缺口。前面那段「做任務」它沒問題;最後那步「收尾」,它常常直接跳過。
具體的畫面是這樣:它輸出了一大段文字、把任務內容交代得好好的,然後——就停了。沒有那一步收尾的回報——既沒呼叫 kanban_complete 說「我做完了」,也沒呼叫 kanban_block 說「我卡住了」。卡片永遠停在「進行中」,board 看起來像沒人做事,其實事都做完了,只是沒人回去翻牌、也沒人吭一聲。
這不是我事後腦補的印象。雛羽自己在 disk 上留了一份派工檢查單,白紙黑字寫著歷史問題(下面引)。
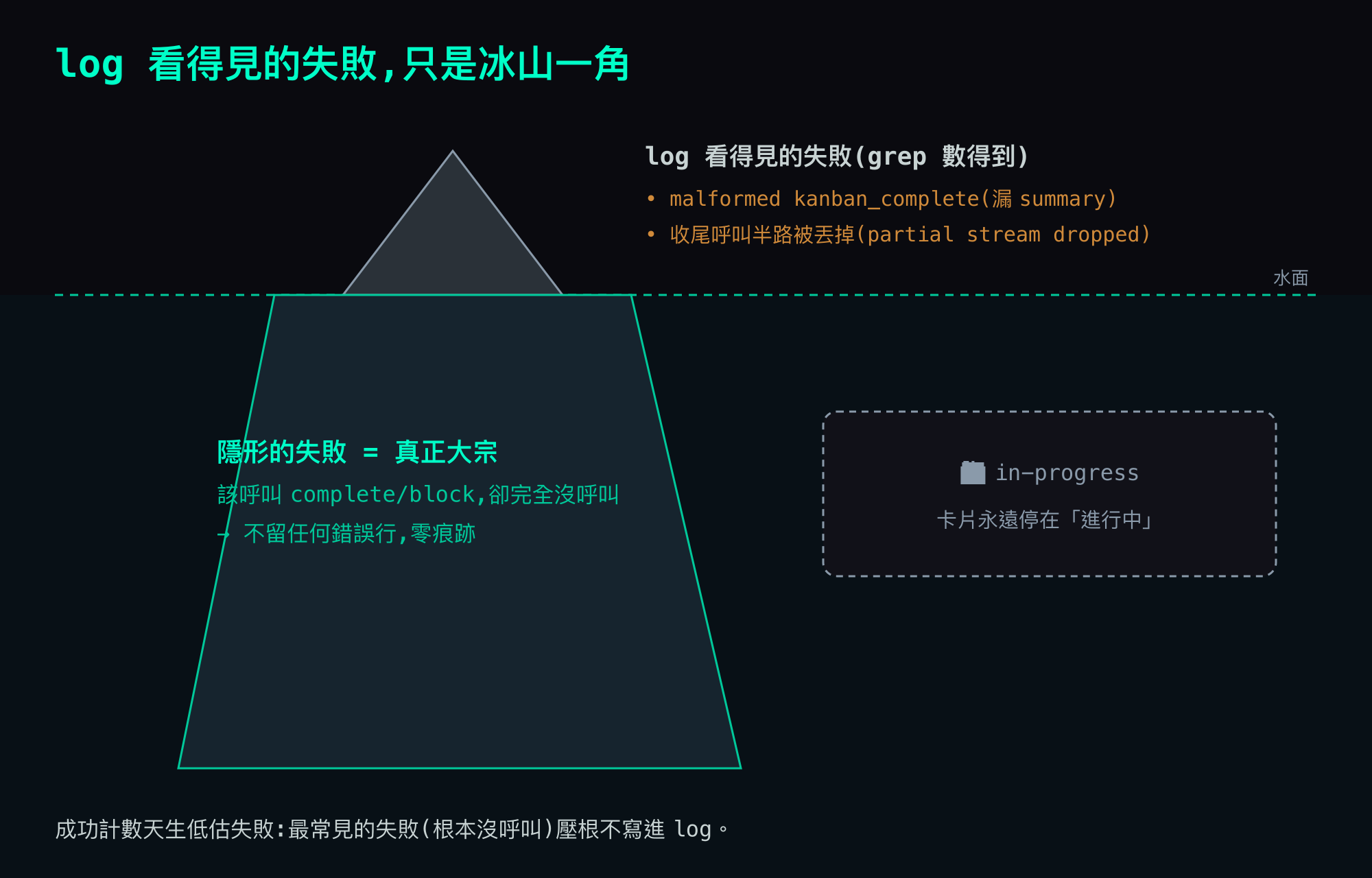
核心洞察:log 看得見的失敗,只是冰山一角——遺漏才是隱形的
這裡是這篇真正想講的東西,而且我自己在查證的路上差點踩偏一次,連這段都得誠實校正。
先講看得見的那半。log 裡確實撈得到 12B 期那個經典的 malformed 收尾呼叫——漏了必填的 summary 參數,被工具層擋下來:
2026-06-21 11:20:46 WARNING agent.tool_executor:
Tool kanban_complete returned error (0.00s):
{"error": "provide at least one of: summary (preferred), result"}
這行(以及同一份 log 裡另一條一模一樣的)是 [live] verbatim,出現在 model=gemma-4-12b 的 session 那段。它正是這篇講的那個失敗模式被工具層接住、留下痕跡的時刻:腦想標完成,但呼叫缺了必填欄位,工具拒收。
⚠️ 自我校正:我原本以為這行錯誤已經被 log rotation 沖掉、只能憑[memory] 轉述。重查源頭 log(在 yui 上)發現它還在——所以這裡給你的是真的 live quote,不是憑印象。下面那個「差點被 grep 騙」的故事也跟著翻案了一半,我照實寫。
而且還有更直接的一條——收尾呼叫在「半路被丟掉」的瞬間,transport 層接住了:
2026-06-21 16:01:40 WARNING agent.chat_completion_helpers:
Partial stream dropped tool call(s) ['kanban_complete']
after 156 chars of text; surfaced warning to user
讀這行:模型先吐了 156 個字的文字,然後那個 kanban_complete 呼叫在串流半途掉了。這幾乎就是「做完內容、丟掉收尾」這件事,被底層 transport 逮個正著。
但這就是重點所在,也是最容易被誤導的地方:這些看得見的失敗,只是冰山露出水面那一角。 真正大量的失敗模式是模型根本沒去呼叫 kanban_complete——它輸出一段文字就停了,工具層連個錯誤都接不到。「該呼叫卻完全沒呼叫」不會在 log 裡留下任何一行。
換句話說:遺漏是隱形的。 你去數 log 裡的成功呼叫,看到的是一串漂亮的 completed,加上零星幾個 malformed 的錯誤行;但這完全反映不出那些「根本沒發生的呼叫」。漏掉收尾的次數越多,log 反而越乾淨。這是個天生會騙你的指標——成功計數低估失敗,因為最常見的失敗模式(直接忘記、連呼叫都沒發起)壓根不寫進 log。
而這個坑差點主動咬我一口。我本次重跑 log 想撈失敗證據,跑了一條任務作者給我的 grep:
grep -iE 'kanban_(complete|show|block)' agent.log \
| grep -oiE 'kanban_[a-z]+|returned error' | sort | uniq -c
它回了一行 2 returned error。我本來打算寫成「kanban 只失敗 2 次」就帶過——正好踩進上面那個陷阱:把 log 裡那兩條看得見的 malformed 失敗,當成「失敗總數」報出去。其實那 2 不是假象(那兩條是真的 malformed 收尾呼叫),問題是它只數得到看得見的那兩條,完全漏掉了那些「連呼叫都沒發起」的隱形遺漏。看得見的失敗用 grep 數得到,但真正的失敗根本不在 log 裡——這恰恰證明了上面那句:查 log 量 agent 紀律,你數到的「失敗」是冰山一角,真正的遺漏沉在水面下。
還有看得見的那一半:其他撈得回的失敗訊號
除了上面那兩條 kanban 收尾的失敗,慢腦時期也留下一些 client 那端會吃到的訊號。這些都是 [live] verbatim:
- 工具迴圈卡死:
[Tool loop warning: repeated_exact_failure_warning; count=2; terminal has failed——同一個呼叫一直撞同一面牆(這條是terminal工具不是 kanban,但同樣是 12B 期model=gemma-4-12bsession 裡的卡死)。 - 連線被重置:
Streaming failed before delivery: [Errno 54] Connection reset by peer。 - 腦在重新載入,client 吃 503:
Streaming failed before delivery: Error code: 503 - {'error': {'message': 'Loading model', ...}}——這條對應 context 爆掉、腦 crash 重新載入的場景(那個 256K OOM 的偵探故事是後面硬核篇的主題,這裡先埋個線)。⚠️ 誠實標:這個 503 不是 12B 專屬,Qwen 27B 期的 log 一樣吃到不少——crash-reload 是這顆腦本身的特性,不是哪個模型的鍋。
換腦:Qwen 27B 慢,但肯收尾
切到現任的 Qwen3.6-27B Q4_K(~30-40 tok/s,MTP 接受率 0.5-0.75),speed 掉了快三倍。但 board 開始乖了。
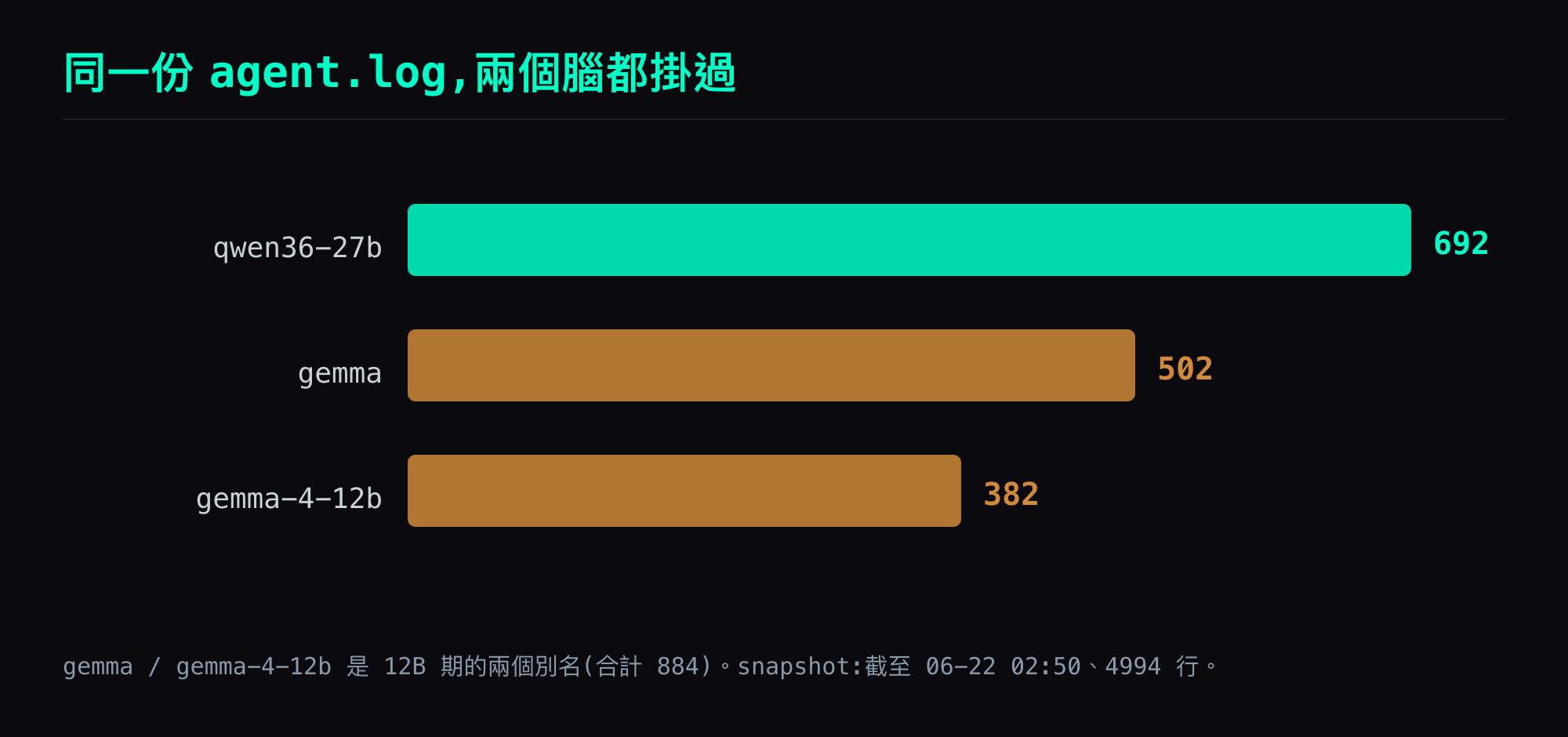
log 在 27B 期撈得到一串連續的 kanban_complete completed,每筆 0.01-0.02 秒乾淨完成。同一塊 board、同一套 prompt,兩個腦都掛過——log 裡的 model 名分佈也佐證了這點(同一份 agent.log 同時有 qwen36-27b、gemma、gemma-4-12b 三種名字)。
但這裡是最容易誤導人的地方,我得把話講死:換 27B 不是「換上去就全好」。
誠實校正:兩個腦都是 2/3,差別在「成功的品質」
小唯(yui 的 default hermes,跑 gpt-5.5)2026-06-22 拿同一套 kanban 派工測試,把 Gemma-era 跟 Qwen-26B 的雛羽各跑了一輪。逐字結果如下(截圖在文末)。
Gemma-era 雛羽(小唯自己標「結果不算理想,但有一點改善」)——成功 2/3,但三張全在第 1 次 protocol violation、靠 retry 才過:
- ✅
t_e5d03aafKanban workload 摘要短卡:第 1 次 protocol violation → 第 2 次完成 → done - ✅
t_40650250Research handoff checklist:第 1 次 protocol violation → 第 2 次完成 → done(產出research_handoff_checklist.md) - ⛔
t_4d52ea69失敗任務事後摘要:第 1 次、第 2 次都 protocol violation → blocked
Qwen-26B 雛羽(小唯標「2 成功 / 1 失敗」)——成功 2/3,但成功那兩張乾淨、沒 protocol violation:
- ✅
t_c7fd541aworkload 摘要:done,約 5 分鐘,kanban_complete成功,沒 protocol violation - ✅
t_5466770d已給原因的 incident 格式化:done,約 4-5 分鐘——小唯註「這張很重要:Gemma 之前 incident-style 會掛,Qwen 這次成功了」,沒亂加原因、沒亂推理 - ⛔
t_cc59d407短 checklist complete/block:第 1 次跑 6 分鐘 protocol violation、第 2 次跑 1 分鐘 protocol violation → blocked
讀這兩組對照,真正的差別不是「對幾題」(都 2/3),是「對的時候有多乾淨」:
- Qwen 成功那兩張是一次就過、零 violation;Gemma 那兩張是靠 retry 才勉強過。
- Qwen 扛住了 Gemma 會掛的 incident-style 任務。
而 Qwen 唯一掛掉那張短 checklist(t_cc59d407)——據小唯的操作筆記,這張的錯更新 prompt 之後就順利成功了(⚠️這條只有小唯的口頭筆記為憑,那張任務的 log 本身沒留下「改 prompt 後通過」的紀錄,所以當操作者轉述、不是 log 實證)。換句話說,剩下那張失敗很可能不是「Qwen 也笨」,而是那張卡的 prompt 沒寫好。
這正好呼應整個系列的 thesis,也是漂亮的收尾,不是黑點:問題常常在 harness(車子),不在 engine(引擎)。 換更穩的腦只是把容易守紀律的門檻降下來;真正壓得住的,是「短卡、來源先抽離、卡尾強制 complete/block」這套派工方式。
一手佐證:雛羽自己寫的派工檢查單
上面那組對照是別人(小唯)跑的測試。但這篇最硬的單一證據,是雛羽自己在 disk 上留下的一份派工檢查單——一手、on-disk、她親手寫的。檔案是 t_cc59d407 工作區裡的 hina_new_model_kanban_checklist.md(產出者標「雛羽」,2026-06-21):
歷史問題 — Gemma 12B 時期常出現 protocol violation:輸出文字後未呼叫 kanban_complete / kanban_block。
改善策略 — 使用短卡、來源先抽離、卡尾強制 complete/block 三者組合。
這把「做完內容卻丟掉收尾」從我的[memory] 體感,升級成「有一手文件白紙黑字這樣寫」——而且跟上面那兩條 [live] 的 malformed kanban_complete 錯誤行對得起來:雛羽寫的「歷史問題」不是抱怨,是 log 裡有痕跡的真事。那條改善策略也漂亮地補上了上一節的結論:換 27B 還不夠,還得改派工方式才壓得住。 同一份檔案也順手記下這顆新腦是「Qwen ~26B, ~36 tok/s」——跟我別處寫的「27B / 30-40 tok/s」是同一顆 Qwen3.6 的不同近似,挑一個標清楚就好,別在數字上裝精確。
⚠️ 採信度標清楚:這份 checklist 是「描述歷史問題 + 測試計畫」,仍是 case study,不是量化失敗率。但它是這篇目前最強的單一可引用證據——一手、on-disk、當事 agent 親寫。
thesis 收束:吞吐量 ≠ 有用
把這篇講完一句話:
「回一段漂亮的話」跟「在長 context 裡持續守一套程序」,是兩種不一樣的能力。 小模型輸的是第二種。tok/s 量的是第一種——它有多快把字吐出來;但它量不到第二種——它能不能在做完內容之後,記得回頭把卡片翻完、把狀態標對、不漏掉那個沒人會提醒它的最後一步。
agentic 紀律不是「夠不夠聰明」,是「夠不夠穩地守住一個無聊但必要的收尾動作」。而最陰的是:守不住的時候,它不會跳錯誤——它只是安靜地走人,留下一張永遠停在「進行中」的卡。
所以我把 100 tok/s 換成 30。不是因為慢比較好,是因為我量錯了東西。
對照截圖:同一套 kanban 測試,兩個腦
下面兩張,是小唯跑完那兩輪派工測試後回報在 Telegram 上的原始結果——上面那組逐字 bullet,就是從這兩張轉出來的。第一張 Gemma-era、第二張 Qwen-26B:


誠實聲明(明擺著,不藏)
這篇不是 benchmark,我把限制全攤在這:
- 不是 controlled paired eval,沒有明確的成功率 / 失敗率數字。
- 看得見的失敗只是冰山一角:log 撈得到的是少數 malformed 收尾呼叫(那 2 條
kanban_complete returned error是真的),但最大宗的失敗是「連呼叫都沒發起」的隱形遺漏,根本不在 log 裡——所以不能從成功計數反推「Gemma 失敗 X 次」。 - 數字凍結在 snapshot:model 名分佈、kanban 工具計數都是「截至 06-22 02:50、4994 行」那個 snapshot;源頭 log 後來繼續長(qwen36-27b 已到 888),別把舊數字當「目前」報。
- 速度 90-100 / 30-40 是 memory 數字,非本次同硬體 paired 重測。
- 「改 prompt 後通過」是操作者(小唯)筆記,不是 log 實證。
- 上面那組對照 n 很小、有 retry 雜訊,當 case study 看。
我能放心給你的,就是這些:兩天的體感、撈得回的 [live] log 碎片(含那兩條真的 malformed kanban_complete)、一份雛羽親寫的 on-disk 檢查單、一組小唯跑的對照截圖。當故事讀,不當論文讀。
同系列其他篇:
- (上一篇)老將漢升退場,天水的麒麟兒登場:NT$11k 改裝卡養一顆 27B agent(這顆 27B 腦怎麼來的)
- (下一篇 · 硬核篇)把 context 拉到 256K 然後 crash:VRAM 跟 context 的數學(對應本篇那個 503 Loading model)
前傳:
- GTX 970 系列:E2B 撐不住 agent 的原版 musing
常見問題
- Gemma 12B 比 Qwen 27B 快三倍,為什麼還換掉它?
- 因為這顆腦是拿來當 agent、掛在 kanban 工作板上的,不是拿來聊天。Gemma 12B 把任務的「內容」做完之後就停手,從不回頭呼叫 kanban_complete 把卡片標成完成——它丟掉的是程序的收尾。換成慢的 Qwen 27B,成功時是乾淨一次就過、沒有 protocol violation。tok/s 量的是回話速度,不是「持續守一套程序」的能力,那是兩種不一樣的能力。
- 所以換成 Qwen 27B 就全好了嗎?
- 沒有,別這樣讀。兩個腦在同一套 kanban 測試裡都是 3 題對 2 題。真正的差別在「成功的品質」:Qwen 成功那兩張是乾淨一次就過、沒 violation;Gemma 那兩張都是第 1 次 protocol violation、靠 retry 才勉強過。而且 Gemma 之前會掛的 incident-style 任務,Qwen 這次扛住了。至於 Qwen 唯一失敗那張短 checklist——更新 prompt 之後就順利完成了,所以那其實是 prompt 問題,不是模型笨。
- 這是一篇 benchmark 嗎?有明確的失敗率數字嗎?
- 不是,這是 case study。沒有 controlled paired eval,也沒有明確的成功率/失敗率數字。Gemma 重度失敗那段時期的 log 已經被 rotation 沖掉了,我能撈回的碎片裡反而看不到大量失敗——這恰好是這篇的核心洞察:模型「忘記呼叫工具」不會留下任何錯誤行,遺漏是隱形的,所以 log 的成功計數天生會騙你。我給的是養 agent 兩天的體感,加上撈得回的一手產出物。