改裝 2080 Ti 22G · part 7
[趣味競賽 進階 #7] 在慢腦上開漸進式串流,我把自己撞進了 Telegram 的 flood control
❯ cat --toc
TL;DR
為了讓慢吞吞的本地 agent 少一點等待焦慮,我開了 Telegram 的漸進式串流——讓字一個個浮現。但我這套 bot 的串流模式,是靠每隔 0.8 秒改寫一次同一則訊息(editMessageText)硬模擬出來的(沒用上 Telegram 原生的 sendMessageDraft 草稿串流)。問題:我那顆 ds4 腦只跑 ~14 tok/s,一個回應動輒拖到 175 秒——以 0.8 秒一次換算,約等於對同一則訊息發出上百次編輯請求(這是估算,log 沒逐筆記)。Telegram 直接祭出 flood control,log 裡一連串 Telegram flood control, waiting 247.0s、Retry in 226 seconds——罰等兩百多秒,連最終答案都送不出去,bot 卡死。附帶還吃到 Message is not modified(內容還沒變就重編)。解法很短:把兩顆慢腦的 top-level streaming 都關掉,算完一次送出完整答案。快模型/雲端模型才適合漸進式編輯串流;本地慢腦,逐字浮現是個會把自己鎖死的陷阱。
白話導讀:慢腦想討好你,結果把自己鎖死
慢的本地腦都有同一個尷尬:回應一拖就是一兩分鐘,使用者盯著一片空白,很容易以為當機了。
直覺會想到的就是開「串流」——讓字像打字機一樣一個個冒出來,起碼讓人知道「它在動」,減少等待焦慮。聽起來很體貼。
但在 Telegram 上,這個體貼會反咬你一口。我這套 bot 的逐字浮現,是靠它每隔幾百毫秒就把同一則訊息改寫一次(editMessageText)硬模擬出來的。快腦回得快、改幾下就收尾,沒事;慢腦回得慢,同一則訊息要被改寫上百次——這就直接踩進 Telegram 對訊息編輯的頻率限制(flood control)。
結果不是「串流卡頓」,是整個 bot 被罰等兩百多秒、最終答案根本送不出去。我想討好使用者,反而把自己鎖死。下面是 log 實證,加上那個短而毒的教訓。
前言:為什麼當初想開串流
這顆腦是光羽(ds4,DeepSeek 系),decode 只有 ~14 tok/s——比這系列另一顆雛羽(Qwen 27B,~30-40 tok/s)還慢一截。(先標清楚:這兩個數字是不同機器上的觀察值,ds4 在另一台、雛羽在這張改裝 2080 Ti,當「腦的實際手感」看就好,不是同硬體 benchmark。)慢腦最痛的地方不在算得慢,在使用者那端的等待焦慮:你在 Telegram 丟一句話,然後盯著一片空白等一分多鐘,完全不知道它到底在算、還是死了。
漸進式串流就是衝著這個來的:讓回應逐字浮現,哪怕整段要算很久,至少使用者第一時間就看到字在動,知道腦還活著。雲端那些 chat 介面都這樣做,體感確實好很多。
所以我把 Telegram 的 streaming 打開了。理論上是雙贏:慢腦該慢還是慢,但至少不再是「丟出去 → 空白 → 突然一大段」的恐怖體驗。
實際上,我踩進了一個只在「慢腦」上才會引爆的雷。
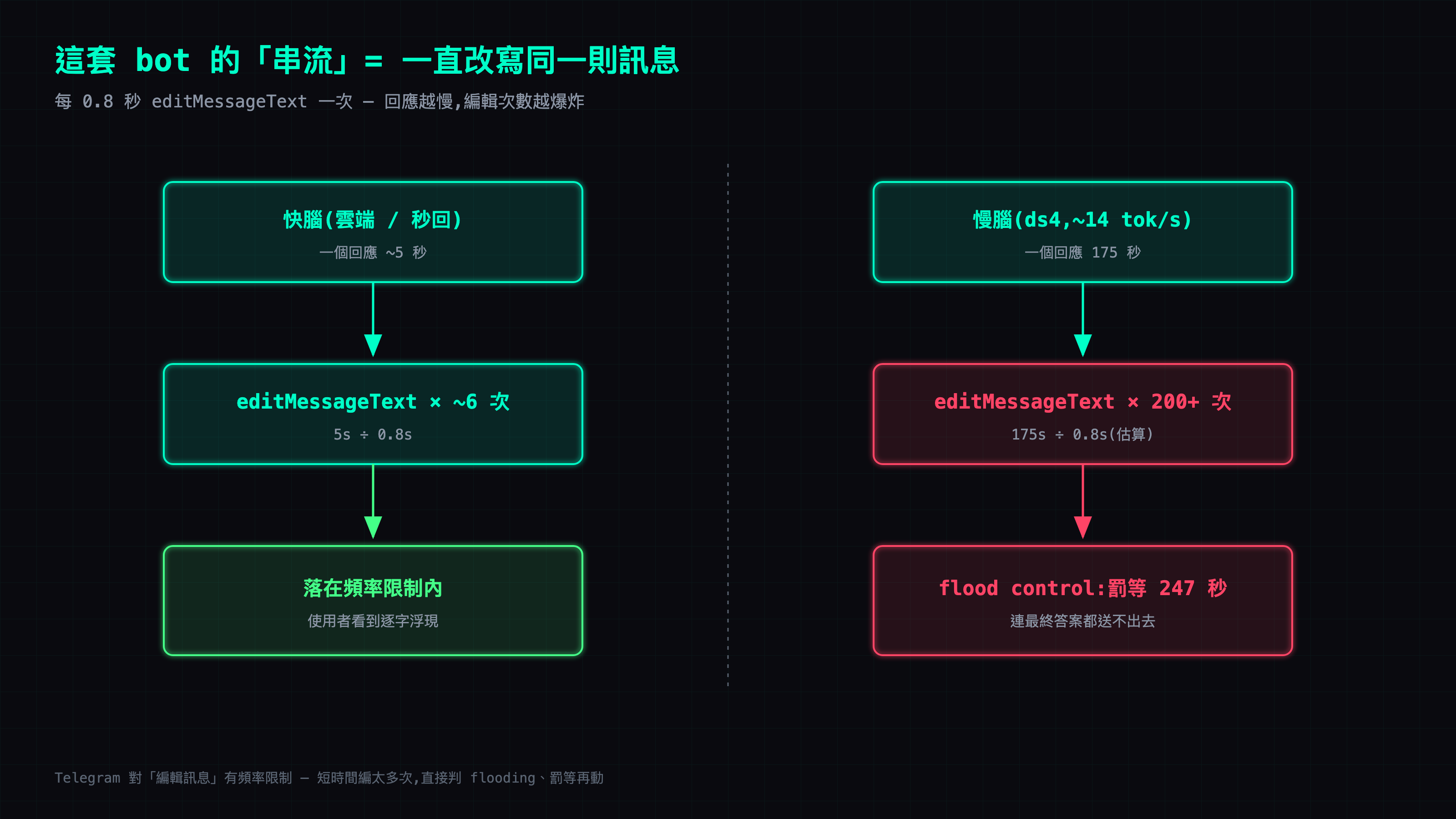
機制:這套 bot 的「串流」其實是一直改寫同一則訊息
關鍵在這裡:我這套 bot 是用「不斷改寫訊息」來假裝串流的。
先補一句:Telegram 其實有原生的串流機制——
sendMessageDraft,一個會持續更新的草稿泡泡,token 到了就推上去(Bot API 9.3 加入、9.5 開放給所有 bot),我之前在 openclaw 上接過它。但我這套 Hermes gateway 撞牆當時跑的不是它,而是更老、也更通用的做法——反覆編輯同一則訊息。下面講的坑,全是「用編輯模擬串流」在慢腦上踩出來的;要不要改接原生草稿串流,是另外一回事(openclaw 那篇就是在做這件事)。
用編輯模擬串流的話,bot 能做的就兩件事:「送一則訊息」跟「編輯一則已存在的訊息」。所以要做出「逐字浮現」,辦法是:
- 先送一則訊息(可能只有開頭幾個字);
- 然後每隔一小段時間,把同一則訊息整個改寫一次,塞進更多新算出來的字;
- 一直改、一直改,直到整段回應算完。
我的設定是 每 0.8 秒改寫一次(config 裡的 edit_interval: 0.8)。對一個幾秒就收尾的快回應來說,這頂多改個幾下,完全沒問題。
但 Telegram 對「編輯訊息」這個動作有頻率限制。一旦你在短時間內對同一則訊息發出太多編輯請求,它會直接判定你在 flooding,然後祭出 flood control:不只擋下這次編輯,還罰你等一段時間才准再動。
舊版機器人影片放在這裡剛好當提醒:逐字浮現看起來很貼心,但在慢回應上,它就是會膨脹成上百次訊息編輯的那個模式。
撞牆:一個 175 秒的回應,發出上百次編輯
把這套搭在 ds4 上,問題就引爆了。
ds4 跑 ~14 tok/s,一個稍微長一點的回應動輒一兩分鐘。看 log,那天凌晨幾個被串流出去的長回應長這樣(全部 streamed=True,確實走了漸進式串流):
00:54:34 response ready ... time=175.3s api_calls=2 response=2570 chars
Suppressing normal final send ... streamed=True ... content_delivered=True
00:59:41 response ready ... time=59.9s api_calls=1 response=1406 chars (streamed=True)
01:05:22 response ready ... time=175.0s api_calls=2 response=2492 chars (streamed=True)
一個 175 秒的回應,以每 0.8 秒改寫一次換算,就是對同一則訊息發出上百次編輯請求(175 ÷ 0.8 ≈ 200 出頭)。
⚠️ 老實說:log 沒有逐筆記錄每一次編輯(我撈過,per-edit 的行數是 0),所以「上百次」是用
edit_interval: 0.8× 回應秒數換算出來的數量級,不是逐筆數出來的。log 能逐字證明的,是下面那串 flood-control 罰等的秒數,以及這些被串流出去的長回應。
就在這幾個長回應被一輪輪串流出去的同一段時間裡,Telegram 翻臉了。flood control 的警告從 01:04:56 開始噴,跟那批 175 秒的串流回應交疊在一起:
01:04:56 WARNING [Telegram] Telegram flood control, waiting 247.0s
01:04:56 WARNING [Telegram] Telegram flood control, waiting 247.0s
01:04:57 WARNING [Telegram] Telegram flood control, waiting 246.0s
01:04:57 WARNING [Telegram] Telegram flood control, waiting 246.0s
01:05:18 WARNING [Telegram] Telegram flood control on send (attempt 1/3),
retrying in 226.0s: Flood control exceeded. Retry in 226 seconds
01:05:23 WARNING [Telegram] Telegram flood control on send (attempt 1/3),
retrying in 221.0s: Flood control exceeded. Retry in 221 seconds
讀這串:Telegram 直接判我 flooding,罰等 247 / 246 / 226 / 221 秒。注意最後兩行的 on send——這已經不只是編輯被擋,連送最終答案都被擋下來了。
也就是說:我為了讓使用者「早點看到字」開的串流,結果是腦辛辛苦苦算了 175 秒,答案卻被 flood control 鎖在門外送不出去。使用者看到的不是逐字浮現的體貼,是一個算完了卻吐不出來、整整卡死好幾分鐘的 bot。完美的反效果。

順便踩到的坑:Message is not modified
還有一個更尷尬的副作用。慢腦有時候隔了 0.8 秒,根本還沒算出新的字——但編輯計時器到了,還是傻傻地拿「一模一樣的內容」去改寫同一則訊息。Telegram 對這個也有意見:
telegram.error.BadRequest: Message is not modified: specified new message
content and reply markup are exactly the same as a current content and
reply markup of the message
「你要我改,結果改完跟原本一字不差。」這行錯誤一樣被記了下來,正是「慢腦 × 固定編輯間隔」的另一個症狀:編輯間隔是固定的(0.8 秒),但慢腦吐新字本來就又慢又不穩——兩邊一錯開,就會送出一堆「沒變化的編輯」——白白浪費掉幾次請求,log 也被洗一排,很可能也順手加重了 rate-limit 的壓力(這些被退回的 no-op 編輯到底算不算進 flood control 的計數,log 沒明說,我不敢把話說死)。
解法:慢腦一律關掉漸進式串流
解法很短,短到有點掃興:把慢腦的 top-level streaming 關掉,改成「整段算完,再一次送出完整答案」。
兩顆腦的 config 現在都是這樣:
streaming:
enabled: false # ← 從 true 改成 false,就這行
transport: auto
edit_interval: 0.8
一個容易踩的坑:這兩份 config 裡其實有兩個不同的
streaming。一個是上面這個 top-level 的 block(管的是 Telegram 那種漸進式編輯串流),這個要關;另一個藏在 CLI / 本地終端機的設定區塊裡(streaming: true),管的是你在自己機器上跑 TUI 時的逐字輸出——那個是不同東西,沒撞 flood、也不該關。改的時候別連那個一起關了。
關掉之後,代價很明確:使用者要等到整段算完才看到字(慢腦該慢還是慢,這沒救)。但至少:不會被罰等、不會卡死、答案算完一定送得出去。對一顆 ~14 tok/s 的慢腦來說,「老老實實等完、然後一次給你完整答案」遠比「逐字浮現但隨時會把自己鎖死」可靠太多。
兩顆慢腦——光羽(ds4)跟雛羽(Qwen 27B)——都關了。
⚠️ 老實說:flood control 是真的在光羽(ds4)身上撞到的(上面那串 log 確鑿)。雛羽(Qwen 27B)的 log 裡沒有它自己撞 flood 的紀錄——我不是說雛羽也撞過,而是「同樣是慢腦、同樣的風險」,所以預防性地一起關掉。別把雛羽也算進「實測撞牆」那一欄。
一句話的教訓
漸進式串流不是壞東西——它是為快模型設計的。雲端那些秒回的腦,一個回應編輯幾下就收尾,逐字浮現確實討喜。
但它有一個沒人寫在說明書上的前提:回應要夠快、編輯次數要落在平台的頻率限制以內。 慢的本地腦把這個前提整個踩破——回應越慢,模擬串流的編輯次數越爆炸,越往 flood control 的牆上撞。最毒的是,它不是「串流變慢」而已,是「連最終答案都送不出去」:你越想讓使用者早點看到字,越可能讓他一個字都收不到。
所以結論很簡單:快模型開串流,慢模型一次送完。 你那顆腦回得越慢,就越不該用「一直改寫訊息」去假裝它回得快。
順帶一個對照:同一批慢腦跑的另一條管線——雛羽的創意工作室(生圖、轉影片,之後會單獨寫一篇)——任務更長,卻從沒撞過 flood。因為它走的是 send_message,一次把產物(圖檔 / 影片檔)送回去,不是用上百次文字編輯去模擬串流。差別不在「慢」,在你到底發幾個 request 才把東西送回去。
同系列其他篇:
- (#1 腦怎麼來的)老將漢升(GTX 970)退場,天水的麒麟兒(RTX 2080Ti 22G)登場:NT$11k 改裝卡養一顆 27B agent
- (#5 同一顆慢腦的另一個等待解法)別讓助理每次都重讀整本對話:把對話記憶存硬碟,回神快 7 倍
相關:
- openclaw 用 Telegram Bot API 9.5 sendMessageDraft 做即時串流(原生草稿串流長怎樣、怎麼接)
常見問題
- 為什麼開漸進式串流會撞到 Telegram 的 flood control?
- 因為我這套 bot 的串流模式,是靠每隔幾百毫秒呼叫一次 editMessageText 改寫同一則訊息來模擬逐字浮現的——它沒有用 Telegram 原生的草稿串流(sendMessageDraft,Bot API 9.3 加入、9.5 開放給所有 bot),用的是更老、更通用的「一直改寫」做法。快模型回得快、編輯次數少,沒事;但慢的本地腦(我這顆 ds4 約 14 tok/s)一個回應拖到一百多秒,以 0.8 秒一次的編輯間隔換算,約等於對同一則訊息發出上百次編輯請求(估算,非逐筆計數)。Telegram 對訊息編輯有頻率限制,撞到就觸發 flood control,罰你等兩百多秒——這段時間連最終答案都送不出去,bot 等於卡死。
- 那快模型也不能開串流嗎?
- 可以,而且漸進式串流本來就是為快模型設計的。快腦/雲端模型一個回應幾秒內收尾,編輯次數落在限制以內,使用者看到字一個個冒出來、體感很好。問題只發生在「慢腦 × 漸進式編輯」這個組合上:回應越慢,編輯次數越爆炸,越容易撞牆。所以這不是「串流是壞東西」,是「慢模型不適合用編輯來模擬串流」。
- 你怎麼修的?
- 把兩顆慢腦(光羽 ds4、雛羽 Qwen 27B)的 top-level streaming 都關掉(enabled: false),改成回應算完之後一次把完整答案送出去。代價是使用者要等到整段算完才看到字,但至少不會被 flood control 罰等、不會卡死。對慢本地腦來說,「一次送完整答案」遠比「逐字浮現但會撞牆」可靠。光羽是真的撞到 flood 才關;雛羽沒撞過,是同類風險預防性一起關。
接著讀
- 2026-06-27[趣味競賽 進階 #6] 工具定義稅:還沒開口,就先吃掉 17K token——而且每次重算都重來一遍
我數了一下家裡那個 AI 助理每次回話前的開銷:還沒開始處理我輸入的文字,就先吃掉約 23K token,其中 17K 只是『工具的使用說明書』。更慘的是它是 hybrid 模型,快取一沒命中就把這 17K 從頭重算——一個對話回合可能重算十幾次。這篇講一個被嚴重低估的成本:模型開口前的「打底開銷」。解法不是砍工具,是像技能那樣『用到才載』。
- 2026-06-23[趣味競賽 進階 #2] 我把 100 tok/s 換成 30:快的 Gemma 12B 做完事就走人,慢的 Qwen 27B 才肯收尾
選本地模型我也是先看 tok/s。Gemma 12B 跑 90-100、爽到飛起,可是掛上 kanban 工作板,它做完內容就「結束」,從不回頭把卡標完成。換成慢三倍的 Qwen 27B,board 反而開始乖。這篇講一個反直覺的選擇:當腦要持續守一套程序,吞吐量根本不是該看的數字。附:連我查 log 都差點被 grep 騙。
- 2026-06-22[趣味競賽 進階 #1] 老將漢升(GTX 970)退場,天水的麒麟兒(RTX 2080Ti 22G)登場:NT$11k 改裝卡養一顆 27B agent
GTX 970 那系列結尾我說「想在老卡上掛 agent,但 E2B 太小」。與其買新卡,我去二手市場撈了一張改裝 22G 的 2080 Ti——淘寶標價 ¥2079、到手含海運雜費約 NT$11,000——剛好夠把一顆常駐 27B 的 agent 腦養在家裡那台廉價老桌機上。這篇講用合理價錢挖到剛好夠用的好料的爽,跟它背後的工程。
- 2026-06-26[趣味競賽 進階 #5] 別讓助理每次都重讀整本對話:KV cache 存硬碟,回神快 7 倍
對話一長,每傳一句它都要把整段重讀一遍(re-prefill)才回你——重開、被擠掉快取後尤其痛。stock llama.cpp 沒內建把 KV cache 存硬碟(feature 被官方標 not planned),我用一支 60 行的 proxy 騙它做到:restore 比重算快 7×(5K 對話 9.9 秒→1.4 秒)。附:機制、proxy 設計、和為什麼我目前還沒上線它。
不想錯過新文章?
訂閱我確保不漏接!
隨時一鍵退訂。