改裝 2080 Ti 22G · part 7
[Just for Fun — Advanced] Progressive Streaming on a Slow Model Got My Bot Rate-Limited by Telegram
❯ cat --toc
- The short version: a slow brain tries to please you and locks itself out instead
- Why I wanted streaming in the first place
- The mechanism: this bot's "streaming" is just rewriting the same message
- Hitting the wall: a 175-second reply, a couple hundred edits
- Adding insult to injury: `Message is not modified`
- The fix: slow brains, kill progressive streaming
- The one-line lesson
TL;DR
To take the edge off a pokey local agent, I turned on Telegram's progressive streaming — the typewriter reveal. But the way this bot did it, that effect is faked by rewriting the same message every 0.8 seconds (editMessageText) — not via Telegram's native sendMessageDraft draft streaming. The problem: my ds4 brain runs ~14 tok/s, and a reply routinely takes 175 seconds — which at 0.8s per edit works out to an estimated couple hundred edit requests against a single message (the log doesn't tally each edit). Telegram answered with flood control, and the log fills with Telegram flood control, waiting 247.0s and Retry in 226 seconds — a four-minute timeout in which even the final answer can't be sent, and the bot just hangs. As a bonus I also collected Message is not modified (re-editing before any new text existed). The fix is short: turn off top-level streaming on both slow brains and send the finished answer once. Progressive edit-streaming is for fast and cloud models; on a slow local brain it's a trap that locks itself out.
The short version: a slow brain tries to please you and locks itself out instead
Slow local brains share an awkward problem: a reply can take a minute or two, and a user staring at a blank chat assumes the thing has crashed.
The obvious fix is to turn on "streaming" — let the text appear character by character, like a typewriter, so at least the user can see it's working and the wait feels less dead. Considerate, in theory.
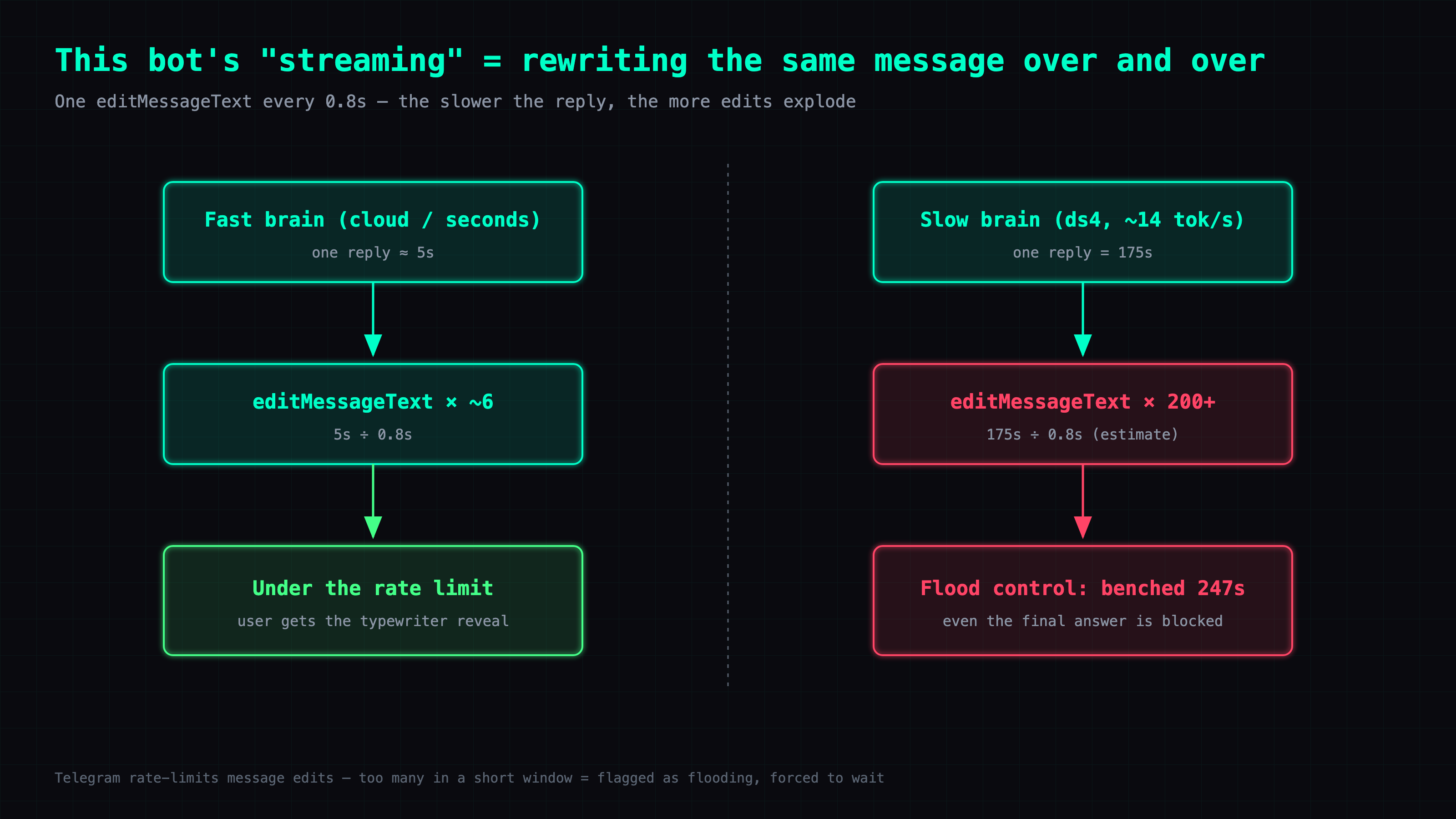
On Telegram, that considerate gesture bites back. The way this bot does it, the typewriter reveal is faked by having the bot rewrite the same message every few hundred milliseconds (editMessageText). A fast brain finishes quickly, edits a few times, no problem. A slow brain rewrites that one message a couple hundred times — and walks straight into Telegram's rate limit on message edits (flood control).
The result isn't "streaming gets choppy." It's the whole bot benched for 200-plus seconds, with the final answer stuck behind the ban. I tried to please the user and locked myself out. Here are the logs, plus the short, ugly lesson.
Why I wanted streaming in the first place
The brain here is Hikari (ds4, a DeepSeek-family model), decoding at just ~14 tok/s — slower even than this series' other brain, Hina (Qwen 27B, ~30-40 tok/s). (To be clear: those two figures are observed agent speeds on different boxes — ds4 on another machine, Hina on this modded 2080 Ti — so read them as real-world feel, not a same-hardware benchmark.) The painful part of a slow brain isn't the math; it's the wait on the user's side: you send a message on Telegram, then stare at a blank chat for over a minute with no idea whether it's thinking or dead.
Progressive streaming is aimed squarely at that. Let the reply appear token by token, so even if the whole thing takes ages, the user sees movement immediately and knows the brain is alive. Every cloud chat UI does this, and it genuinely feels better.
So I turned Telegram streaming on. On paper it's win-win: the slow brain is still slow, but at least it's no longer "send → blank → suddenly a wall of text."
In practice, I tripped a wire that only goes off on a slow brain.
The mechanism: this bot's "streaming" is just rewriting the same message
Here's the root of it: this bot fakes streaming by rewriting the message over and over.
One note before the mechanism: Telegram does have native streaming —
sendMessageDraft, a draft bubble that keeps updating as tokens arrive (added in Bot API 9.3, opened to all bots in 9.5). I wired it up for openclaw a while back. But that's not what this Hermes gateway was running when I hit the wall. It used the older, more broadly compatible trick: repeatedly edit the same message. Everything below is what that edit-based fake-streaming does to a slow brain; migrating to the native draft streaming is a separate project (the openclaw post is that project).
With the edit-based approach, a bot has exactly two moves: send a message and edit an existing one. So to produce a typewriter reveal, the path is:
- send a message (maybe just the opening few characters);
- then, every short interval, rewrite that whole message in place, packing in the newly generated text;
- keep rewriting until the full reply is done.
My setting was one rewrite every 0.8 seconds (edit_interval: 0.8 in the config). For a fast reply that wraps in a few seconds, that's a handful of edits — completely fine.
But Telegram rate-limits the edit action. Send too many edits against one message in a short window and it decides you're flooding, then drops flood control on you: it doesn't just block this edit, it benches you for a stretch before you're allowed to act again.
The original robot clip works better here as the reminder: the fake typewriter effect looks friendly, but this is exactly the pattern that turns into hundreds of message edits on a slow reply.
Hitting the wall: a 175-second reply, a couple hundred edits
Bolt this onto ds4 and the mine goes off.
ds4 runs ~14 tok/s, so a slightly long reply routinely takes a minute or two. In the log, the long streamed replies from that early morning look like this (all streamed=True, so they really did go through progressive streaming):
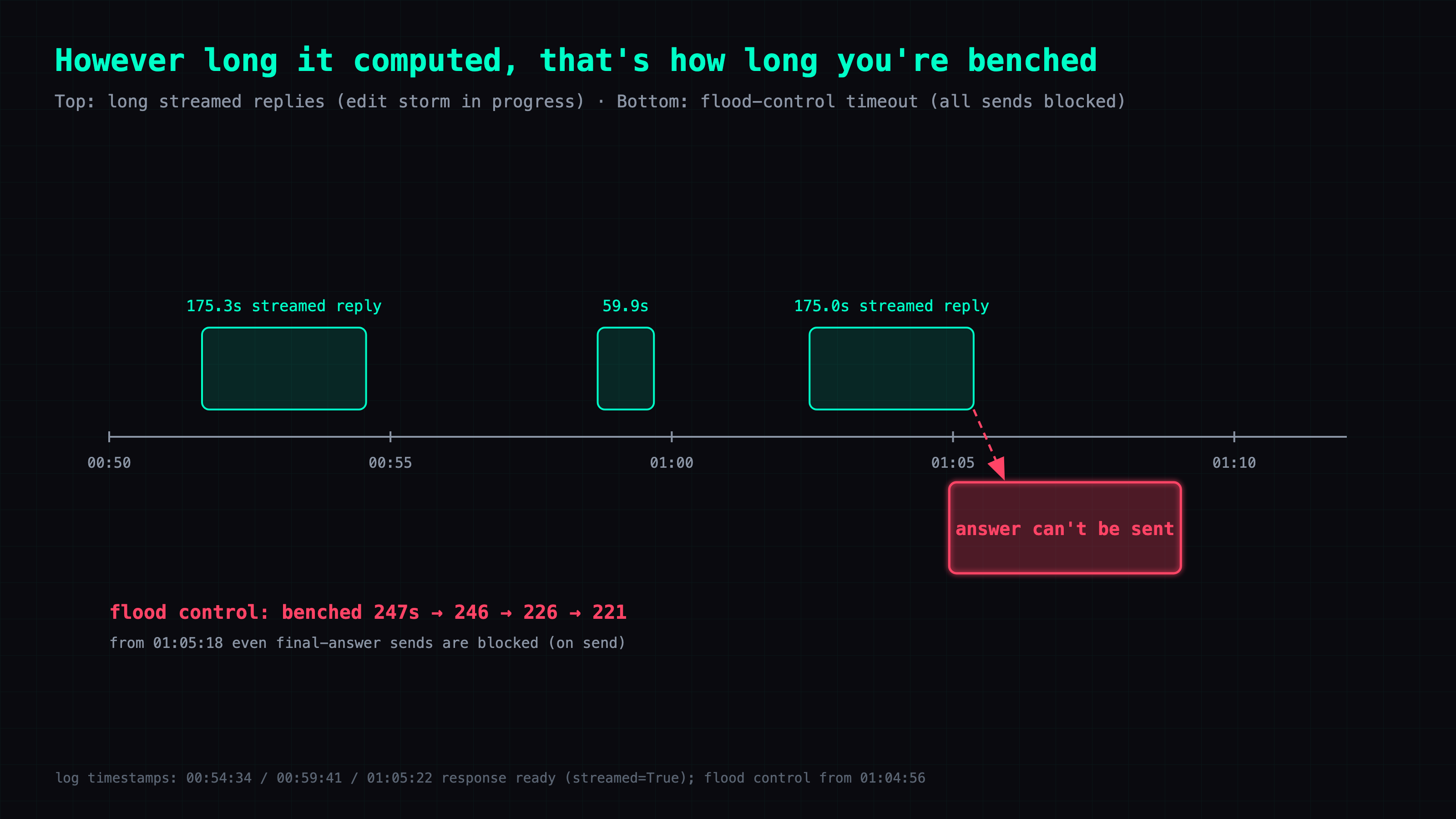
00:54:34 response ready ... time=175.3s api_calls=2 response=2570 chars
Suppressing normal final send ... streamed=True ... content_delivered=True
00:59:41 response ready ... time=59.9s api_calls=1 response=1406 chars (streamed=True)
01:05:22 response ready ... time=175.0s api_calls=2 response=2492 chars (streamed=True)
A 175-second reply, rewritten once every 0.8 seconds, comes out to a couple hundred edit requests against the same message (175 ÷ 0.8 ≈ 200-plus).
⚠️ Full disclosure: the log does not record each individual edit (I checked — the per-edit line count is zero), so "a couple hundred" is an order-of-magnitude estimate from
edit_interval: 0.8times the reply duration, not a per-call tally. What the log proves verbatim is the flood-control timeout seconds below, plus these long streamed replies.
While those long replies were being streamed out during that same window, Telegram turned on me. The flood-control warnings start at 01:04:56, overlapping that batch of 175-second streamed responses:
01:04:56 WARNING [Telegram] Telegram flood control, waiting 247.0s
01:04:56 WARNING [Telegram] Telegram flood control, waiting 247.0s
01:04:57 WARNING [Telegram] Telegram flood control, waiting 246.0s
01:04:57 WARNING [Telegram] Telegram flood control, waiting 246.0s
01:05:18 WARNING [Telegram] Telegram flood control on send (attempt 1/3),
retrying in 226.0s: Flood control exceeded. Retry in 226 seconds
01:05:23 WARNING [Telegram] Telegram flood control on send (attempt 1/3),
retrying in 221.0s: Flood control exceeded. Retry in 221 seconds
Telegram flagged me as flooding and benched me for 247 / 246 / 226 / 221 seconds. Note the on send on the last two lines — by then it isn't just edits getting blocked; the final answer can't go out either.
So the streaming I turned on to let users "see text sooner" meant the brain ground away for 175 seconds and then had its answer locked outside the door by flood control. What the user got wasn't a considerate typewriter reveal — it was a bot that finished thinking, couldn't spit it out, and hung for several minutes. A perfect own goal.
Adding insult to injury: Message is not modified
There's a more embarrassing side effect, too. Sometimes the slow brain hadn't produced any new text in the 0.8 seconds since the last edit — but the timer fired anyway, so it dutifully rewrote the same message with identical content. Telegram has an opinion about that as well:
telegram.error.BadRequest: Message is not modified: specified new message
content and reply markup are exactly the same as a current content and
reply markup of the message
"You asked me to edit, and the edit is byte-for-byte what was already there." That error got logged too, and it's the other symptom of slow-brain-plus-fixed-edit-interval: the edit interval is fixed (0.8s), but the rate of new text is slow and uneven. When the two fall out of sync, you fire off a string of no-op edits — burning request attempts and cluttering the log, and probably adding to the rate-limit pressure too (whether Telegram counts these rejected no-op edits toward flood control, the log doesn't say, so I won't claim it).
The fix: slow brains, kill progressive streaming
The fix is simple, almost anticlimactically so: turn off top-level streaming on the slow brain and go back to "compute the whole thing, then send the final answer once."
Both brains' configs now read:
streaming:
enabled: false # ← flipped from true; that's the line
transport: auto
edit_interval: 0.8
One easy trap: each config actually has two different
streamingkeys. One is the top-level block above — that governs Telegram-style progressive edit-streaming, and that's the one to disable. The other lives in the CLI / local-terminal section (streaming: true) and governs token-by-token output when you run the TUI on your own machine — that's a different path: it never hits Telegram flood control, and you shouldn't touch it. Don't flip that one by accident.
Once it's off, the cost is plain: the user waits for the whole reply before any text appears (a slow brain is still slow — no cure for that). But in exchange: no timeout, no hang, and the answer always goes out once it's computed. For a ~14 tok/s brain, "wait it out, then deliver the complete answer" beats "typewriter reveal that can lock itself out at any moment" by a mile.
Streaming is now off on both slow brains: Hikari (ds4) and Hina (Qwen 27B).
⚠️ Full disclosure: flood control was actually hit on Hikari (ds4) — the log run above is conclusive. Hina's (Qwen 27B) log has no record of it hitting flood control itself. I'm not claiming Hina hit the wall; it's the same kind of slow brain with the same failure mode, so I disabled it there preemptively. Don't put Hina in the "we saw it crash" column.
The one-line lesson
Progressive streaming isn't the villain — it's built for fast models. A cloud brain that answers in seconds only needs a few edits to get through a reply, and the typewriter reveal is genuinely nice.
But it carries a precondition nobody writes in the manual: the reply has to be fast enough that the edit count stays under the platform's rate limit. A slow local brain breaks that precondition wholesale — the slower the reply, the more the faked-streaming edits balloon, the harder you slam into flood control. And the nastiest part is how it fails: not "streaming gets slow," but "the final answer can't be sent at all." The harder you try to show users text sooner, the more likely they are to get nothing at all.
So the rule is clean: fast models stream; slow models send once. The slower your brain replies, the less business it has pretending to be fast by rewriting a message over and over.
One last contrast: the same fleet's other slow pipeline — Hina's creative-studio runs (generate an image, turn it into a video; that post is coming) — handles even longer jobs and never hit flood control. It delivers with send_message: the finished artifact goes back in one shot — an image file, a video file — instead of a stream faked with hundreds of text edits. The difference isn't speed; it's how many requests it takes to deliver the result.
Also in this series:
- (#1 — how the brain got here) I Scored a 22GB-Modded 2080 Ti for ~$340 All-In — Just Enough to Keep a 27B Agent Running at Home
- (#5 — the other wait-time fix for the same slow brain) llama.cpp won't persist KV cache to disk — so I put a 60-line proxy in front of it (7× faster restore)
Related:
- openclaw Real-Time Streaming via Telegram Bot API 9.5 sendMessageDraft (what the native draft streaming looks like, and how to wire it)
FAQ
- Why does progressive streaming trip Telegram's flood control?
- Because this bot's streaming mode faked the typewriter reveal by calling editMessageText every fraction of a second to rewrite the same message in place — it didn't use Telegram's native draft streaming (sendMessageDraft, added in Bot API 9.3 and opened to all bots in 9.5); it used the older rewrite-it-over-and-over approach. A fast model finishes in seconds and only edits a handful of times — fine. But a slow local brain (my ds4 runs ~14 tok/s) can take well over a minute per reply, and at a 0.8-second edit interval that works out to an estimated couple hundred edits against one message (an estimate, not a per-edit tally). Telegram rate-limits message edits; cross the line and it triggers flood control, benching you for 200-plus seconds — during which even the final answer can't go out. The bot just hangs.
- So fast models can't stream either?
- They can, and progressive streaming was built for them. A fast or cloud model wraps a reply in a few seconds, the edit count stays under the limit, and the user gets a pleasant token-by-token reveal. The failure is specific to the slow-brain-plus-edit-streaming combo: the slower the reply, the more the edit count balloons, the harder you hit the wall. Streaming isn't the villain — faking it with edits on a slow model is.
- How did you fix it?
- I turned off top-level streaming on both slow brains (Hikari on ds4, Hina on Qwen 27B) — enabled: false — and went back to sending the finished answer in one shot once the reply is done. The cost is that the user waits for the whole thing before any text appears, but at least nothing gets flood-banned and nothing hangs. For a slow local brain, one complete send beats a typewriter reveal that locks itself out. Hikari is the one that actually hit flood control; Hina never did — I disabled it there preemptively as a same-class risk.
Read next
- 2026-06-27[Just for Fun — Advanced] The Tool-Definition Tax: 17K Tokens Before I Say a Word, Re-Billed on Every Cache Miss
I added up what my home agent pays before it reads a single word from me: ~23K tokens of overhead, and 17K of that is just the instruction manuals for its tools. Worse, it runs a hybrid model — on a cache miss it re-processes all 17K from scratch, and a single user turn can do that a dozen-plus times. This is context economics, badly underestimated. The fix isn't cutting tools; it's loading them on demand, the way skills already do.
- 2026-06-23[Just for Fun — Advanced] I Gave Up 100 tok/s for 30 — Fast Isn't the Same as Useful
Picking a local model, I looked at tok/s first too. Gemma 12B does 90-100 and it's great — until you put it on a kanban board, where it finishes the work and just walks away, never marking the card done. A Qwen 27B that's three times slower actually closes the loop. Why throughput is the wrong number for an agent — plus how grep almost lied to me about it.
- 2026-06-22[Just for Fun — Advanced] I Scored a 22GB-Modded 2080 Ti for ~$340 All-In — Just Enough to Keep a 27B Agent Running at Home
I dug up a 22GB-modded RTX 2080 Ti for ~$340 all-in (¥2079 sticker + shipping) — just enough to keep a resident 27B agent brain running on the same cheap old desktop. What the mod changes, and the gotchas.
- 2026-06-26[Just for Fun — Advanced] llama.cpp won't persist KV cache to disk — so I put a 60-line proxy in front of it (7× faster restore)
On a long conversation, every message makes the model re-read the whole thing (re-prefill) before it answers — worst right after a restart or a cache eviction. Stock llama.cpp can save the KV cache to disk (--slot-save-path) but won't do it on its own — the auto-persist feature request is closed as not planned. A tiny stdlib reverse-proxy restores instead of re-prefilling: 9.9s → 1.4s on a 5K chat (7×). Mechanism, proxy design, and why I haven't shipped it yet.
Don't miss the next one
Subscribe, and you won't.
One-click unsubscribe anytime.