改裝 2080 Ti 22G · part 5
[Just for Fun — Advanced] llama.cpp won't persist KV cache to disk — so I put a 60-line proxy in front of it (7× faster restore)
❯ cat --toc
- In plain terms: it's not answering slowly — it's re-reading from page one
- Where this picks up: Part 3's "why is it slow" thread
- First, the obvious thing: that 10-second wait is re-reading, not thinking
- llama.cpp has a "save to disk" trick — it just won't use it on its own
- Sanity check: the hybrid Qwen saves and restores KV without crashing
- The fix: a 60-line proxy that swaps "re-read" for "load a save file"
- The numbers: a 5K chat goes 9.9s → 1.4s, 7× faster
- The catch: it's 7× faster, but I'm still not running it
- Takeaways
- Where this leaves things
TL;DR
On a long conversation, a local model re-reads the entire chat (re-prefill) before every reply — and that wait spikes right after a restart or after another job evicts your cache. That's the real culprit behind Part 3's cliffhanger ("30 tok/s feels slower than 14"): you're waiting on time-to-first-token, not on decode. Stock llama.cpp can save the KV cache to disk (--slot-save-path) but won't do it automatically — the auto-persist feature request is closed as not planned. I wrote a ~60-line, zero-dependency reverse-proxy that restores/saves per request, turning the re-read into a save-file load: 9.9s → 1.4s on a 5K chat, 7× faster (estimated 25–40× on a 28K chat). To be upfront: I've verified this works, but I'm not running it daily yet — I'll explain why at the end.
In plain terms: it's not answering slowly — it's re-reading from page one
You know how a video game has a save file? You play to level 3, quit, come back, hit load — and you're back at level 3. You don't replay levels 1 and 2.
A local AI assistant is missing that save file.
When you've had a long conversation with it (tens of thousands of words), it actually reads that whole thing "into its head" before it starts replying. That read step is called prefill. Normally the result stays in VRAM, the next message reuses it, and it's fast.
The problem is that cached state is fragile: a restart wipes it, another job can evict it, and an idle timeout drops it. Once it's gone, your next message forces the model to re-read the entire conversation from scratch — and the longer the chat, the longer you wait at the start of every turn. In game terms: replaying levels 1 and 2 before you're allowed to continue, every single time.
This article gives it that save file: write the read-in state to disk, then load it back next time (under a second) instead of re-reading the whole thing (10 seconds and up).
Where this picks up: Part 3's "why is it slow" thread
Part 3 was a hunt for where the VRAM went, and it ended on a loose thread: this hybrid Qwen3.6 model "generates at 30 tok/s but feels slower than another box doing 14." Because what you feel isn't decode — it's TTFT (the wait between hitting send and the first token), and TTFT was getting eaten by re-reading the whole conversation.
This post resolves it.
Same setup: one secondhand modded 22GB RTX 2080 Ti, llama.cpp serving a long-lived Qwen3.6-27B as the agent model. A long-lived agent means long conversations plus the occasional restart or interruption — which is exactly the situation that triggers a re-read.
First, the obvious thing: that 10-second wait is re-reading, not thinking
Split "slow" into two parts. A reply has two phases:
- prefill (reading the prompt): load the whole conversation into the KV cache. This scales linearly with conversation length.
- decode (writing the answer): produce one token at a time. This runs at a fixed rate (the "30 tok/s").
On a short chat, prefill is instant and all you feel is decode. But once the conversation grows to tens of thousands of tokens and the cache is gone, prefill balloons to tens of seconds — you stare at the screen and not one token has appeared, because it's busy re-reading the book. That's why "30 tok/s" lies: decode isn't slow, you just haven't reached decode yet.
That read-in state (the KV cache) disappears in three situations, each of which forces a re-read:
- The server restarts — cold start, VRAM has nothing.
- Another job evicts it — this same model also gets used to summarize conversations and run other sibs; the single slot gets overwritten, and your state gets bumped.
- It ages out — the RAM cache layer is bounded and evicts least-recently-used.
A long-lived agent hits all three routinely. So the re-read isn't an edge case — it's a daily tax.
llama.cpp has a "save to disk" trick — it just won't use it on its own
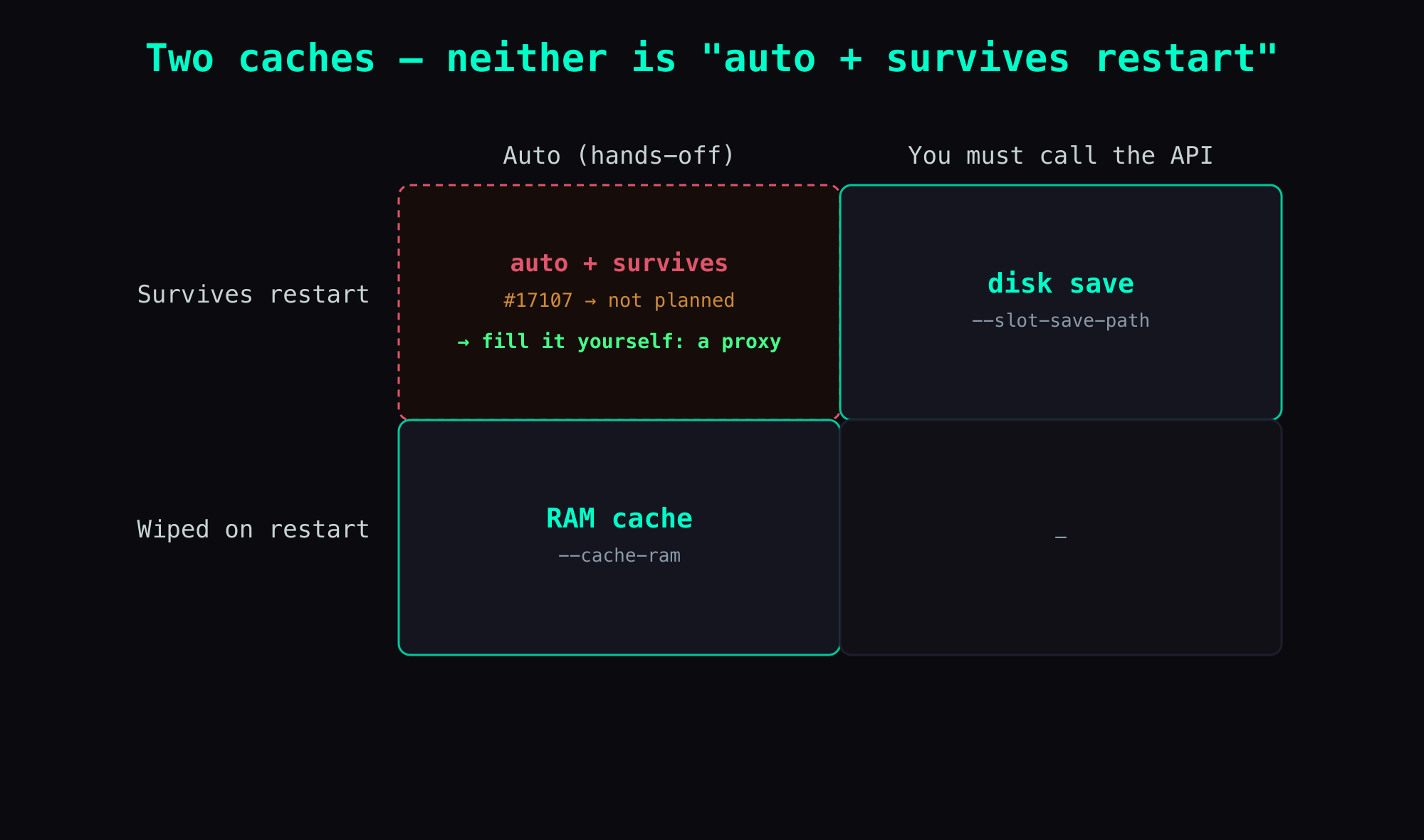
Good news: llama.cpp ships a mechanism to save a KV slot to disk. Bad news: it's off by default, and you have to ask for it explicitly.
It has two caches, but the "automatic and survives a restart" combination is empty:
| Cache | How | Automatic? | Survives restart? |
|---|---|---|---|
| RAM cache | --cache-ram N (on by default) | ✅ automatic | ❌ wiped on restart |
| disk save | --slot-save-path DIR | ❌ client must call the API | ✅ on disk |
Pass --slot-save-path DIR and it exposes an endpoint:
POST /slots/<id>?action=save {"filename":"x.bin"} # save the current slot to a file
POST /slots/<id>?action=restore {"filename":"x.bin"} # restore the slot from a file
(Call it without that flag and you get a 501.)
So why not just build in "auto-save to disk, survives restart"? Someone filed exactly that feature request (#17107), and the maintainers closed it as not planned. That's not laziness — it's a design call: the server provides the mechanism (the ability to save/restore); the policy (when to save, which key to use) is left to the client.
Which means: getting "automatic disk-KV" out of stock llama.cpp means driving it from outside. So let's drive it.
Sanity check: the hybrid Qwen saves and restores KV without crashing
Before automating anything, I confirmed this hybrid model can save/restore KV without breaking — hybrid models have a history of crashing on recurrent-state restore.
Measured on forge (a warm ~4K-token slot):
save → 211ms, 219MB file
restore → 87ms, /health = ok afterward, no crash
87 milliseconds to load back a 4K conversation's worth of state. Against a cold re-prefill of tens of seconds, that gap is the whole point. A few caveats worth calling out honestly:
- Text-only: loading vision (mmproj) blocks slot-save (#21133). This model has no vision attached — fine.
- File size grows linearly: 4K ≈ 219MB → a 50K chat is ~2.7GB. A 1TB disk holds plenty, but you have to prune.
- SWA-style models need
--swa-fullif you want the full-context KV preserved (otherwise the SWA cache is windowed and the save is incomplete).
The mechanism works. The remaining piece: make it save/restore automatically, at the right moment, without changing the agent.
The fix: a 60-line proxy that swaps "re-read" for "load a save file"
The idea is dumb but it works: drop a reverse-proxy between the agent and llama-server. On each incoming request it decides whether to restore, then saves after replying. The agent is none the wiser — not one line changes.
your agent →(proxy :8080)→ llama-server :8081
For each /v1/chat/completions, the proxy does four things:
- Derive a key from the request (this conversation's identity, e.g. a session id).
- If the slot in memory isn't this conversation and
<key>.binexists on disk →action=restoreto load it back. - Forward the request to
llama-serverand stream the response back. - On finish →
action=saveto write it out as<key>.bin.
I wrote it as kvproxy.py — Python standard library, zero dependencies (a ThreadingHTTPServer, one threading.Lock to serialize the single slot). forge already had Python 3.13, so it just runs.
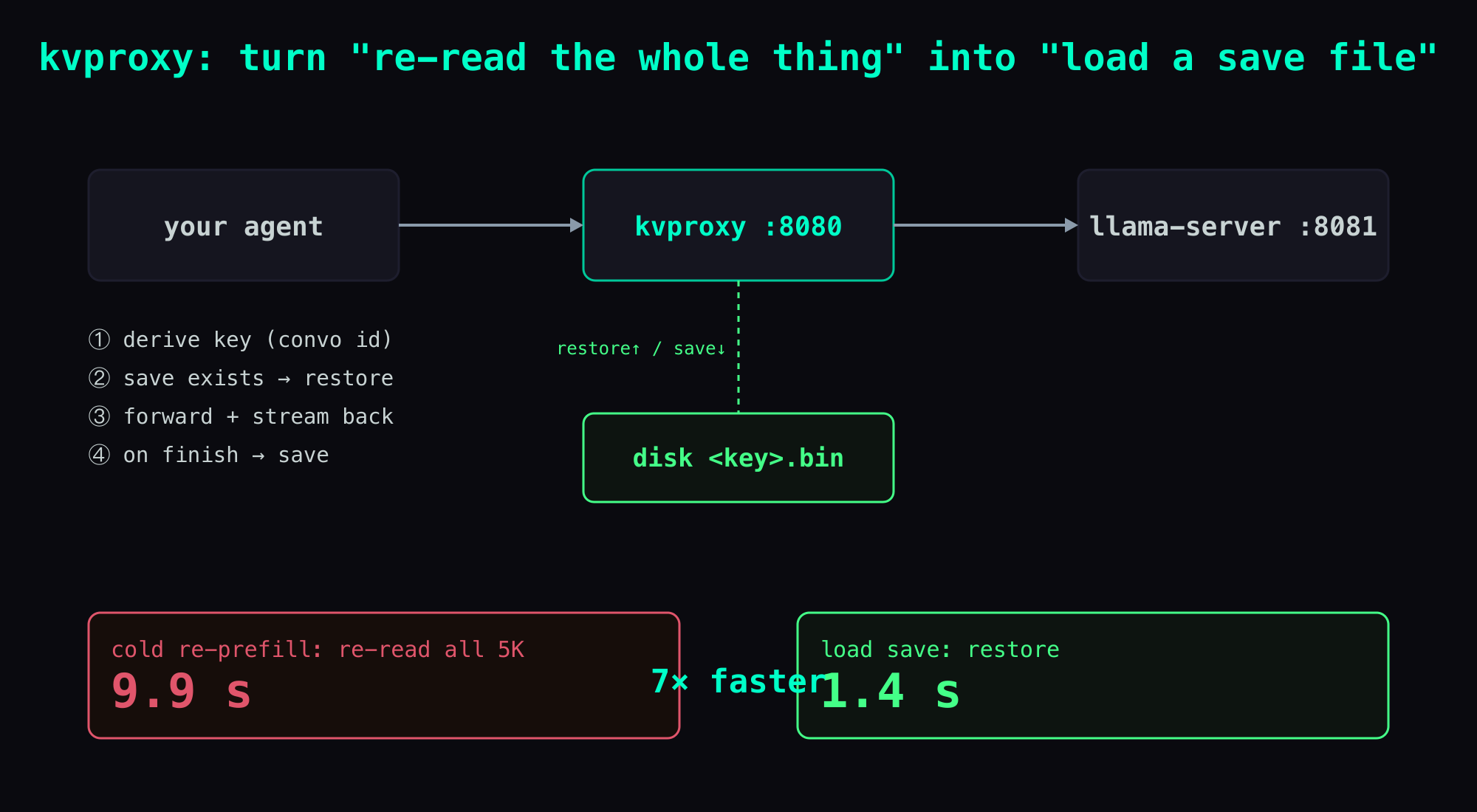
The numbers: a 5K chat goes 9.9s → 1.4s, 7× faster
I took a 5K-token conversation and measured on a side port so nothing live was affected:
| Case | Wait before first token | What happened |
|---|---|---|
| Cold re-prefill (no save file) | 9.9s | re-read all 5K from scratch |
| Load save file (proxy restore) | 1.4s | restore 0.8s + the rest |
7× faster. And that's only 5K — the longer the chat, the worse the re-read penalty and the bigger the win from loading a save file. On a 28K-token kanban conversation, re-prefill measured ~46s, so restore should land around 1–2s — roughly 25–40× (that one's an estimate; I haven't re-run the full measurement at 28K, flagging it as such).
The community numbers line up: someone on an RTX 3090 measured restore at ~0.2s vs a cold prefill of over a minute (#20572).
For what it's worth, I didn't build this from scratch — I first went looking for existing work and found neshat73/proxycache, an experimental FastAPI version doing nearly the same thing. It's not production-grade and the README links are broken, but I'd still borrow three things from it: how it streams, the cache_prompt:true + n_keep:-1 body injection, and saving/restoring only on large requests.
The catch: it's 7× faster, but I'm still not running it
If I stopped here it'd be too clean a story. There's a catch, and it matters more than the 7×.
My daily setup still runs the RAM cache. I haven't cut over to this proxy. Two reasons:
- This model doesn't restart much. When the RAM cache is warm, a turn starts in 4–7s — good enough. Disk-KV's biggest payoff is across restarts, and I don't restart often.
- There are loose ends. Multiple conversations would contend for one slot (
--parallel 1). Each 244MB save file needs LRU pruning. And I'd want production logs before choosing betweenprompt_cache_keyand a prefix hash for the key. The prototype proved the core; running it 24/7 needs these closed.
So the honest version: I've verified this path, it works, and it's 7× faster — but given the loose ends above, I'm staying on the RAM cache for daily use. --slot-save-path is already enabled and waiting; the only missing piece is wiring up a client, the day it's actually worth it.
Takeaways
Where the time went: not the 60 lines of proxy — it was confirming the hybrid model could save/restore KV without crashing (a minefield, historically) plus understanding why mainline doesn't build this in (I assumed it was a gap; reading the issue showed it's a deliberate mechanism/policy split). Getting the problem framed right mattered more than rushing the implementation.
Reusable diagnostics: when it feels slow, don't blame decode speed first — measure prefill and decode separately. If the "before first token" wait explodes with conversation length, your bottleneck is TTFT / re-reading, not a dumb model or slow generation. None of this depends on which card or which model you run.
The general principle: if you're going to repeat an expensive computation, cache it instead of redoing it. A full prefill is a pure function (same conversation prefix → same KV), so it's cacheable by nature. If the framework won't automate it, you can still bolt it on from outside: the server gives the mechanism, you supply the policy.
Where this leaves things
This closes Part 3's "why does it feel slow" thread: the culprit is the re-read (re-prefill), and stock llama.cpp's --slot-save-path plus a small proxy turns it into a save-file load (7×) — I've just chosen to keep it as insurance and run the RAM cache daily for now.
Also in this series:
- (previous · #4) Quantizing the MTP draft cache backfires: a counterintuitive Qwen benchmark
- (#3) I maxed context to 256K, it loaded — then crashed: a VRAM whodunit on a 22GB card (this is where the "why is it slow" thread was planted)
- Series start: an NT$11k modded card running a 27B agent
FAQ
- Why does a local LLM get slower to respond as the conversation gets longer?
- Before it can reply, the model has to load the entire conversation into its KV cache — that step is called prefill, and it scales with conversation length. Normally the cache stays in VRAM and the next turn reuses it, so it's fast. But if the cache is gone (server restart, evicted by another job, or a cold start), it has to re-read the whole conversation from scratch (re-prefill). The longer the chat, the longer that wait. What feels like slow token generation (decode) is usually this startup wait (time-to-first-token).
- Can llama.cpp save its KV cache to disk to avoid re-prefilling?
- The mechanism exists but isn't automatic. With --slot-save-path DIR, llama.cpp exposes POST /slots/<id>?action=save|restore so you can save/restore a KV slot to disk by hand. It won't do it for you — the feature request for automatic disk persistence (#17107) is closed as not planned. So getting disk-KV out of stock llama.cpp means driving it externally (calling that API yourself).
- How big is a saved KV cache and how fast is restore?
- Measured on a hybrid Qwen3.6 slot of ~4K tokens: save was 211ms for a 219MB file, restore was 87ms, and the server stayed healthy after restore — no crash. File size grows linearly with conversation length — a 50K-token chat is about 2.7GB. Restore is far cheaper than a cold re-prefill: I measured a 5K chat at 9.9s to re-prefill vs 1.4s to restore — 7× faster.