改裝 2080 Ti 22G · part 4
[Just for Fun — Advanced] Quantizing the Draft Cache Backfired — A Counterintuitive Look at Qwen MTP (f16 ran 34% faster than q4)
❯ cat --toc
- The short version: not every cache saves memory when you quantize it
- Picking up the "runtime scratch eats VRAM" thread
- First, what MTP actually is
- The intuition: quantizing the draft cache "should" be a free win
- The faceplant: the quantized version fails on all three counts
- Unpacking the "triple penalty"
- (a) Memory: the likely cause is dequant scratch > the storage saved
- (b) Acceptance: quantizing makes the draft guess worse
- (c) The two stack into a net loss in decoding speed
- Why this is different from "KV quantization saves memory"
- The conclusion: don't quantize the draft cache
- Rules of thumb to carry over
- Honest disclaimer
TL;DR
This 22G card is packed: ~15.7GB of 27B weights plus 128K of context, so I quantize everything I can. The main KV cache is q4. The MTP draft cache? Sure, quantize that too — it's just a little draft model, surely a free win. It wasn't, and the result ran the whole intuition backwards: q4 draft cache ran 29.6 tok/s, the un-quantized f16 ran 39.7 — the quantized one is the slow one, 25% slower (which is f16 being 34% faster) — and f16 had more free VRAM on top of that. The instinct to "quantize to save memory" backfires here. Unpacked, it's a triple penalty: (1) a quantized cache pays for a dequant scratch buffer, and the storage saved is smaller than the scratch, so free VRAM drops; (2) quantizing lowers acceptance (0.75 → 0.59), so the main model accepts fewer drafted tokens and the speculative win shrinks; (3) those two stack into a net loss in decoding speed. The fix is blunt: don't set -ctkd / -ctvd, leave the f16 default — which is exactly how my current Hina brain runs, with cache_k=f16, cache_v=f16 right there in the llama.cpp log. The draft cache is one of the few places quantizing is a net loss. ⚠️ Up front: this A/B was run at 256K, same-prompt, small N — read it as a measured finding, not a significance test. The mechanism (dequant overhead plus lower acceptance) doesn't depend on the context size, so I expect f16 to win at 128K too — but I didn't re-run the same A/B at 128K, so that's a reasoned inference, not a second measurement.
The short version: not every cache saves memory when you quantize it
To fit a 27B model plus long context on a 22G card you develop a reflex: quantize whatever you can. The weights are already Q4; the main KV cache is squeezed to q4 too — every bit saved helps. That reflex is right almost everywhere.
Then I applied that same instinct to the MTP "draft cache," and it backfired completely.
MTP (speculative decoding) uses a tiny "draft head" baked into the model file to guess several tokens ahead; the main model then verifies them in parallel and keeps the ones that match. That draft head has its own KV cache. My thinking: it's a draft, precision matters less here, so quantizing it should be the safest win of all — and since it takes up memory (it really does, as we'll see), shaving it down has to save something.
The measurement said otherwise: the quantized version was slower, used no less memory, and had lower acceptance. It lost on all three counts to doing nothing — the plain f16 default.
This post is about unpacking that surprise: why "quantizing saves memory" — an intuition that's almost always right — fails precisely here, on the draft cache.
Picking up the "runtime scratch eats VRAM" thread
The last hard-core post was a detective story: I pushed context to the model's max of 256K, it loaded fine with no error, and then it crashed under real load — because the card had a single hair's-width of free VRAM left, not even enough for one context checkpoint. The lesson there was that the real ceiling isn't "do the weights fit," it's "does the runtime scratch fit."
This post follows the same thread. I flagged something in passing last time: besides the context checkpoints, the MTP draft state lives in that hair's-width of headroom too — the logs show lines like total state size = 550.849 MiB (draft: 73.176 MiB), and the draft slice isn't loose change. Since it takes up memory, quantizing it to reclaim headroom sounds obviously correct, right?
This post puts that "obviously" to the test: quantizing the draft cache not only saves nothing, it loses speed and acceptance along the way.
First, what MTP actually is
To read the table below, you need to know what MTP is doing.
MTP = Multi-Token Prediction, Qwen3.6's built-in speculative decoding. Ordinary speculative decoding makes you load a separate small "draft model" to guess tokens; MTP doesn't — its draft head lives inside the same GGUF file, trained alongside the main weights, so there's no separate draft-model file to load (it still runs its own draft context, just sourced from that one GGUF).
How it runs:
- The draft head guesses N tokens at once (I set N=3).
- The main model verifies all N in parallel (one forward pass, not one token at a time).
- Correct guesses are accepted; from the first wrong one onward, the main model takes over.
- Higher acceptance means "for the cost of one main-model pass, you get several tokens for free" → faster decode.
In llama.cpp, MTP landed in mainline on 2026-05-16 with PR#22673, "llama + spec: MTP Support", tested on Qwen3.6 (the PR ships 27B and 35BA3B variants), though it should work for any model with MTP heads. You enable it with --spec-type draft-mtp, and --spec-draft-n-max controls how many tokens it guesses. ⚠️ One practical note: my Hina launch carries --parallel 1 (one request at a time) — the PR says parallel decoding with MTP is supported but not fully optimized yet, so I keep it to a single slot here. It's a conservative choice, not a hard requirement.
The launch for this brain looks roughly like this:
--spec-type draft-mtp --spec-draft-n-max 3
-fa on -ctk q4_0 -ctv q4_0
-c 131072 --parallel 1 ...
Note: I set -ctk / -ctv (the main KV) to q4_0, but I did not set -ctkd / -ctvd (the draft KV) — which is the whole point of this post. Leaving the draft cache at f16 is deliberate, not an oversight. llama.cpp prints this at startup (live [log] from forge):
common_speculative_impl_draft_mtp:
- n_max=3, n_min=0, p_min=0.00, n_embd=5120, backend_sampling=1
- gpu_layers=-1, cache_k=f16, cache_v=f16, ctx_tgt=yes, ctx_dft=yes
cache_k=f16, cache_v=f16 proves the draft cache stays at the f16 default — this production brain isn't quantizing it, and the rest of the post is why that's correct.
The intuition: quantizing the draft cache "should" be a free win
First, why I went and touched it — the intuition is reasonable, reasonable enough that it nearly fooled me.
The draft cache isn't loose change. It genuinely takes up memory, and it grows with prompt length. The prompt_save lines from forge's live [log] show the draft slice tracking prompt size:
| prompt length (tokens) | total state | draft portion |
|---|---|---|
| ~1,300 | 177 MiB | ~5 MiB |
| 3,942 | 234 MiB | 15.5 MiB |
| 18,642 | 551 MiB | 73.2 MiB |
⚠️ These are separate live samples at different prompt lengths (not an A/B of one fixed prompt) — they only establish that the draft state is real and scales with the prompt. My notes have a longer one:
total state size = 980 MiB (draft: 151 MiB)at a 38591-token prompt, with the draft slice reaching about 15% of the total state. At long prompts, the draft cache is anything but small.
So the calculation was simple. The main KV quantization had already saved a chunk, and the draft cache could reach into the hundreds of MiB, so why not quantize it to save more? Especially since it's just a draft — its precision needs are, in theory, lower than the main model's.
That intuition is half right: the draft cache is worth doing the memory math on. But the answer is counterintuitive — do the math and quantizing it turns out to be a net loss.
The faceplant: the quantized version fails on all three counts
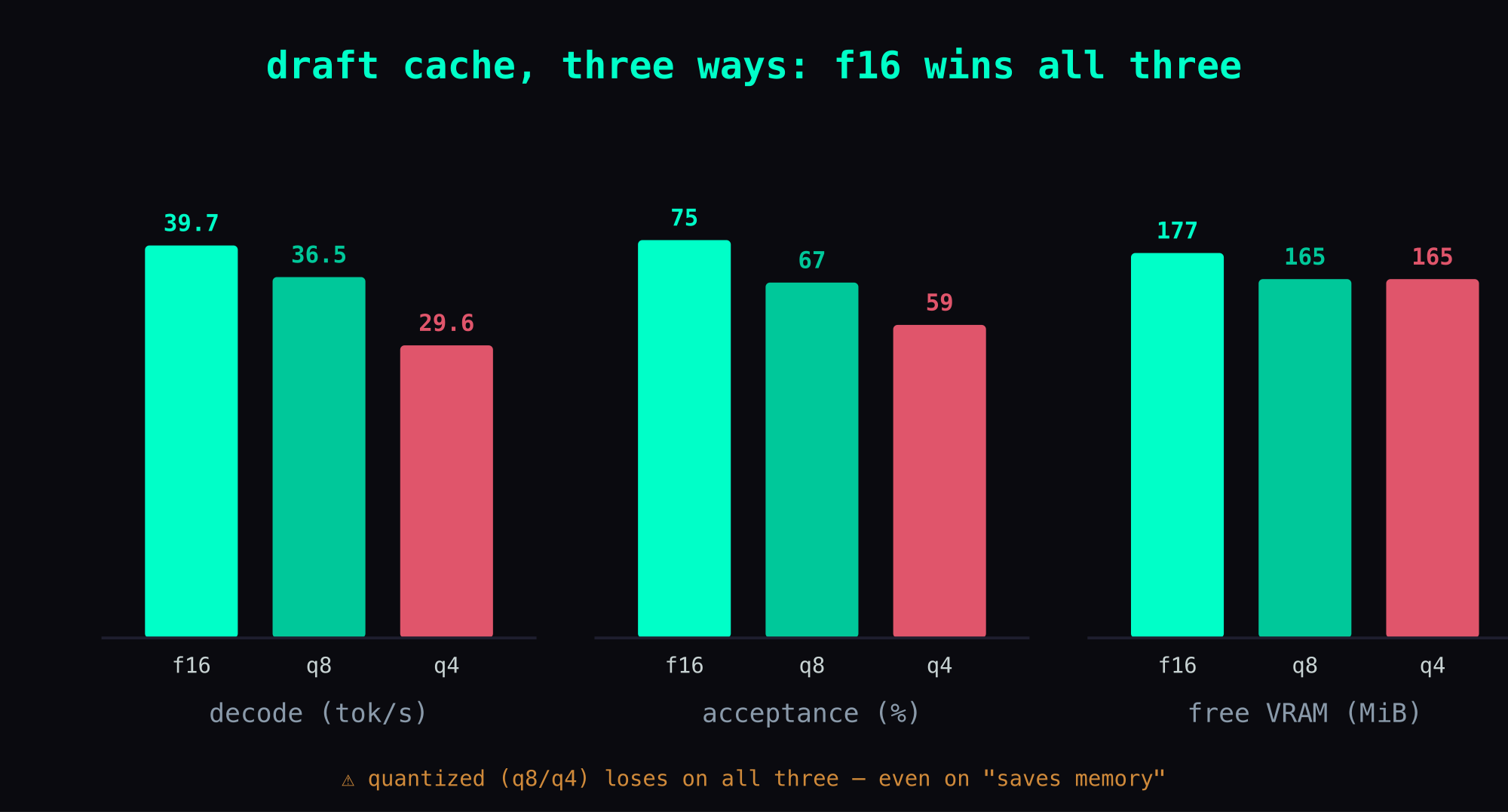
Here's the measurement (same-prompt, all at 256K, main KV fixed at q4/q4, only the draft cache type changed):
| draft cache | decode | vs f16 | acceptance | free VRAM |
|---|---|---|---|---|
| f16 (default) | 39.7 tok/s | — | 0.75 | 177 MiB |
| q8 | 36.5 tok/s | −8% | 0.67 | 165 MiB |
| q4 | 29.6 tok/s | −25% | 0.59 | 165 MiB |
(Flip the baseline to the slowest q4 and f16 is 34% faster.)
It's obvious at a glance: f16 sweeps all three metrics — fastest decode, highest acceptance, and the most free VRAM (or at worst a tie).
The most counterintuitive column is the last one: quantizing the draft cache didn't save memory — f16 actually had more free VRAM than q4 (177 → 165). I'd expected the quantized version to at least win on "saves memory," and it lost even there. The near-universal equation "save memory = quantize" runs backwards here.
Unpacking the "triple penalty"
The faceplant table is satisfying, but it's just an anecdote until you explain the mechanism. Quantizing the draft cache steps on three landmines at once:
(a) Memory: the likely cause is dequant scratch > the storage saved
The point of quantizing is to store the cache in a smaller format. But a quantized KV cache isn't just stored — every decode step has to dequantize it to compute, which needs a scratch buffer. When the cache itself is small (the draft cache is much smaller than the main KV), the storage you save can be smaller than the extra scratch buffer it requires, and the net is a loss.
That's why the quantized versions had less free VRAM (177 → 165): the scratch buffer more than ate up the small storage saving. My notes even show llama.cpp's memory estimate coming out f16 < q4 < q8 — the quantized estimates are larger, the exact opposite of "quantizing always saves."
⚠️ "estimate f16 < q4 < q8" is an observation from my notes (
[memory]), not a screenshot re-pulled this round. Take it as directional support — it's the same story as the free-VRAM column (quantized is lower), two sides of one coin; pinning the numbers down would need an estimate-log capture.
(b) Acceptance: quantizing makes the draft guess worse
This is the more damaging cut. In this run, quantizing the draft cache lowered the precision of the history the draft head sees → it guessed worse → the main model accepted fewer of its drafted tokens. The table makes it plain: acceptance falls from f16's 0.75 to q8's 0.67 to q4's 0.59.
The entire payoff of speculative decoding rides on acceptance: high acceptance = several free tokens per main-model pass; low acceptance = a pile of guesses bounced back, work wasted. Cutting acceptance from 0.75 to 0.59 directly cuts into MTP's speedup.
Acceptance fluctuates with content anyway — the same f16 brain, in forge's live [log], measured anywhere from 0.42 to 0.95 across tasks (mean acceptance length 2.27 to 3.84), and per-position acceptance tapers off in the samples I saw (e.g. (0.865, 0.757, 0.595) — the further out it guesses, the less accurate). Precisely because it swings this much, the A/B has to be same-prompt — comparing acceptance across different prompts is comparing scores on different exams.
(c) The two stack into a net loss in decoding speed
(a) hands you extra dequant overhead; (b) hands you lower acceptance (fewer free tokens). Together, decoding speed takes a double hit. f16 → q4 being 25% slower (q4 → f16 being 34% faster) is those two cuts compounding.

Why this is different from "KV quantization saves memory"
Normally, quantizing the main KV cache pays off — the main KV is large (several GB at 128K context), the storage saved dwarfs the dequant scratch, and quantizing it doesn't directly lower acceptance (it is the ground truth). That's exactly why the main KV on my card must be q4: without it, 128K of context simply won't fit in 22G.
The draft cache is a different animal:
- It's small — small enough that "storage saved" can lose to "dequant scratch."
- It feeds acceptance directly — quantizing it degrades draft quality, and the speculative win shrinks with it.
So the same action (quantize the KV) is a net win on the main KV and a net loss on the draft cache. The difference isn't whether "quantizing" is good or bad — it's how big this cache is and whether it affects acceptance.
This matches a related conclusion from the GTX 970 series, Part 3: there I found that "quantizing the main KV on an SWA model saves almost nothing and slows decode"; here it's "quantizing the draft cache is a net loss." Both are counterintuitive cases of "quantizing KV isn't always worth it" — the lesson is always to do the math first instead of acting on instinct.
The conclusion: don't quantize the draft cache
The bottom line:
Don't set -ctkd / -ctvd — leave the f16 default. The draft cache is one of the few places quantizing is a net loss: it's small enough that the storage saved loses to the dequant scratch, and it feeds acceptance directly, so quantizing it reduces the speculative speedup. Trading a few dozen MiB for both of those is false economy.
The mechanism behind this doesn't depend on the context size. My A/B ran at 256K (the daily context at the time, since dialed back to 128K — see the last post); the two causes — dequant overhead and lower acceptance — are just as present at 128K, so I expect "f16 wins" to hold there too, which is why my current Hina still runs the draft cache at f16 (the cache_k=f16, cache_v=f16 line above). ⚠️ To be straight about it: I didn't re-run the same A/B at 128K, so that's a reasoned inference, not a second measurement.
Rules of thumb to carry over
- Quantizing KV ≠ always saving memory. When the cache is small and every decode step has to dequantize it, the scratch overhead can eat the storage you saved, or worse. Weigh "storage saved vs scratch overhead" before quantizing on reflex.
- The draft cache especially should not be quantized. It directly sets draft quality → acceptance → speculative speedup. Trading a few dozen MiB for acceptance is the most expensive mistake in this post.
- The bottleneck of speculative decoding is acceptance, not the size of the draft cache. To go faster, spend your effort making the draft guess better, not making the draft cache smaller.
- Always run A/B comparisons on the exact same prompt. Acceptance swings hard with content (live 0.42–0.95), so a comparison across different prompts is meaningless.
Honest disclaimer
This is a measured finding, not a controlled benchmark — limits on the table:
- This A/B ran at 256K (the daily context then; since dialed back to 128K). I expect "f16 wins" to hold at 128K too (the mechanism doesn't depend on context size), but I didn't re-run the same A/B at 128K; and the free-VRAM figures in the table (177/165/165) are from that 256K hair's-width regime — don't mix them with the ~2GB free at 128K from the last post.
- N / repetitions weren't recorded: same-prompt comparison, but not a large sample — don't read significance into it.
- The absolute decode numbers (39.7, etc.) are @256K, same-prompt; they don't conflict with the ~28–40 tok/s elsewhere (128K, different prompts), but the context differs, so only cite the relative result (f16 > q8 > q4), and don't compare absolute numbers across different setups.
- "estimate f16 < q4 < q8" is a
[memory]observation, not a fresh screenshot — directional support; pinning it down needs an estimate-log capture. - The live-backed parts (the draft-mtp config
cache_k=f16, draft acceptance 0.42–0.95,total state size … (draft: N MiB)growing with the prompt) were all re-pulled from forge's live[log]this round and line up with my notes.
Also in this series:
- (previous, hard-core) Pushing context to 256K and crashing: the VRAM-vs-context math (the draft state eats that same hair's-width of headroom)
- (next) Why 30 tok/s feels slower than 14 on another box: TTFT is the culprit (MTP improved decode speed, but what you feel is TTFT)
Prequel:
- GTX 970 series, Part 3: q8 KV is a bad idea (quantizing the main KV on an SWA model saves almost nothing) (a sibling case of "quantizing KV isn't always worth it")
FAQ
- What is MTP, and how is it different from regular speculative decoding?
- MTP is Multi-Token Prediction, Qwen3.6's built-in speculative decoding. Regular speculative decoding needs a separate small draft model to guess tokens; MTP doesn't — its draft head lives inside the same GGUF file, trained alongside the main weights, so there's no separate draft-model file to load. It guesses several tokens at once; the main model verifies them in parallel; then you keep whatever it accepts, which speeds up decoding. In llama.cpp you turn it on with --spec-type draft-mtp; it landed in mainline on 2026-05-16 with PR#22673 and was tested on Qwen3.6 (not Qwen-only — it works for any model with MTP heads).
- Why does quantizing the draft cache make it slower instead of faster?
- Three penalties stack. First, it doesn't actually save memory: a quantized cache needs a dequant scratch buffer, and the storage you save is smaller than the extra scratch buffer it requires, so free VRAM ends up lower. Second, it drops acceptance — a lower-quality draft means the main model accepts fewer of its guesses, so the speculative speedup shrinks. Third, those two combined cause a net loss in decoding speed. Measured: q4 was 25% slower than f16 (equivalently, f16 was 34% faster than q4), acceptance fell from 0.75 to 0.59, and free VRAM was lower too.
- So the takeaway is don't quantize any KV cache?
- No — don't read it that way. This post is only about the draft cache (-ctkd/-ctvd). Quantizing the main KV (-ctk/-ctv) to q4 is a separate matter and on my 22G card it's mandatory — without it, 128K of context doesn't fit. The draft cache is special because it feeds acceptance directly, so trading a few dozen MiB for a worse speculative speedup is the worst kind of false economy. Quantizing the main KV is about fitting context; don't conflate the two.