Gemma 4 on a GTX 970 · part 3
[Just for Fun] On a GTX 970, Flash Attention nearly doubles long-context decode (24.3 → 42.5 tok/s)
❯ cat --toc
- The short version
- Picking up where we left off
- The setup: one long prompt, two knobs
- Flash Attention nearly doubled long-context decode
- Why FA wins at decode on a card that has no tensor cores
- FA also saved ~430MB — without it, 16K context barely fits
- q8 KV cache: saved ~15MB, cost 24% of decode
- Takeaways
- Where the time went
- Reusable diagnostics
- The general principle
- What to actually run
TL;DR
On a 2014 GTX 970 — Maxwell, no tensor cores — running Gemma 4 E2B with a 7719-token prompt at -c 16384, the standard KV-cache playbook inverts. Turning on Flash Attention nearly doubled long-context decode: 24.3 → 42.5 tok/s (+75%, KV held at f16), against the common assumption that FA is pointless or harmful on old cards. FA also saved ~430MB of VRAM (3856 → 3427 MiB) — without it, the 4GB card barely holds 16K context (175MB free). And the move everyone reaches for to save memory — q8 KV cache — was a bad trade here: it saved only ~15MB (because sliding-window attention already keeps KV tiny) and slowed decode to 32.3 tok/s, since Maxwell has no fast int8. I reverted production back to f16 KV. Decode numbers reproduced across two runs; I didn't get clean prefill numbers, so I'm not reporting them.
The short version
Everybody "knows" two things about running LLMs on a small old card: turn Flash Attention off (it's a tensor-core feature, useless on Maxwell), and turn KV-cache quantization on (small VRAM, so squeeze the cache). On a 2014 GTX 970 with a current Gemma model, both turned out backwards. Flash Attention made long answers nearly twice as fast and freed up memory. Quantizing the cache saved almost nothing and made the card slower. This post is about why the old rules of thumb point the wrong way on this particular card.
Picking up where we left off
Part 1 found that a no-tensor-core card is dequant-bound, so the simplest quant format wins. Part 2 bolted on vision, audio, and TTS to make the thing a full offline assistant. Both lived in short context. This one stretches it: a 7719-token prompt, 16K context window, and the two knobs you'd expect to reach for to make that fit and run fast — Flash Attention and KV-cache quantization.
I went in carrying the common assumption that Flash Attention is a tensor-core trick and does nothing — or worse, hurts — on a Maxwell card from 2014. That assumption was wrong — and how it's wrong is the whole article.
The setup: one long prompt, two knobs
Same box as the rest of the series: a GTX 970 (Maxwell, compute capability 5.2, no tensor cores, ~3.5GB usable), Gemma 4 E2B QAT Q4_0 (~3.2GB), llama.cpp built for sm_52. The model uses sliding-window attention (SWA) with n_swa=512 — remember that number, it's the reason half the conventional wisdom breaks.
I fed the same 7719-token prompt with a 16K context window, and toggled two things: Flash Attention (-fa), and the KV-cache precision (--cache-type-k/--cache-type-v).
# FA off, f16 KV (the "old card → FA off" default)
./build/bin/llama-server \
-m ~/models/gemma-4-E2B-QAT-Q4_0.gguf \
-ngl 99 -c 16384 --port 8080
# FA on, f16 KV
./build/bin/llama-server \
-m ~/models/gemma-4-E2B-QAT-Q4_0.gguf \
-ngl 99 -c 16384 -fa --port 8080
# FA on, q8 KV (the "small VRAM → quantize the cache" reflex)
./build/bin/llama-server \
-m ~/models/gemma-4-E2B-QAT-Q4_0.gguf \
-ngl 99 -c 16384 -fa \
--cache-type-k q8_0 --cache-type-v q8_0 --port 8080
Three configurations, one long prompt. I measured decode twice per config to make sure it held.
Flash Attention nearly doubled long-context decode
Here are the three runs. The column that matters is long-prompt decode:
| Setting | KV | Long-prompt decode | VRAM used (free) |
|---|---|---|---|
| FA off | f16 | 24.3 tok/s | 3856 MiB (175 free) |
| FA on | f16 | 42.5 tok/s | 3427 MiB (605 free) |
| FA on | q8_0 | 32.3 tok/s | 3412 MiB (620 free) |
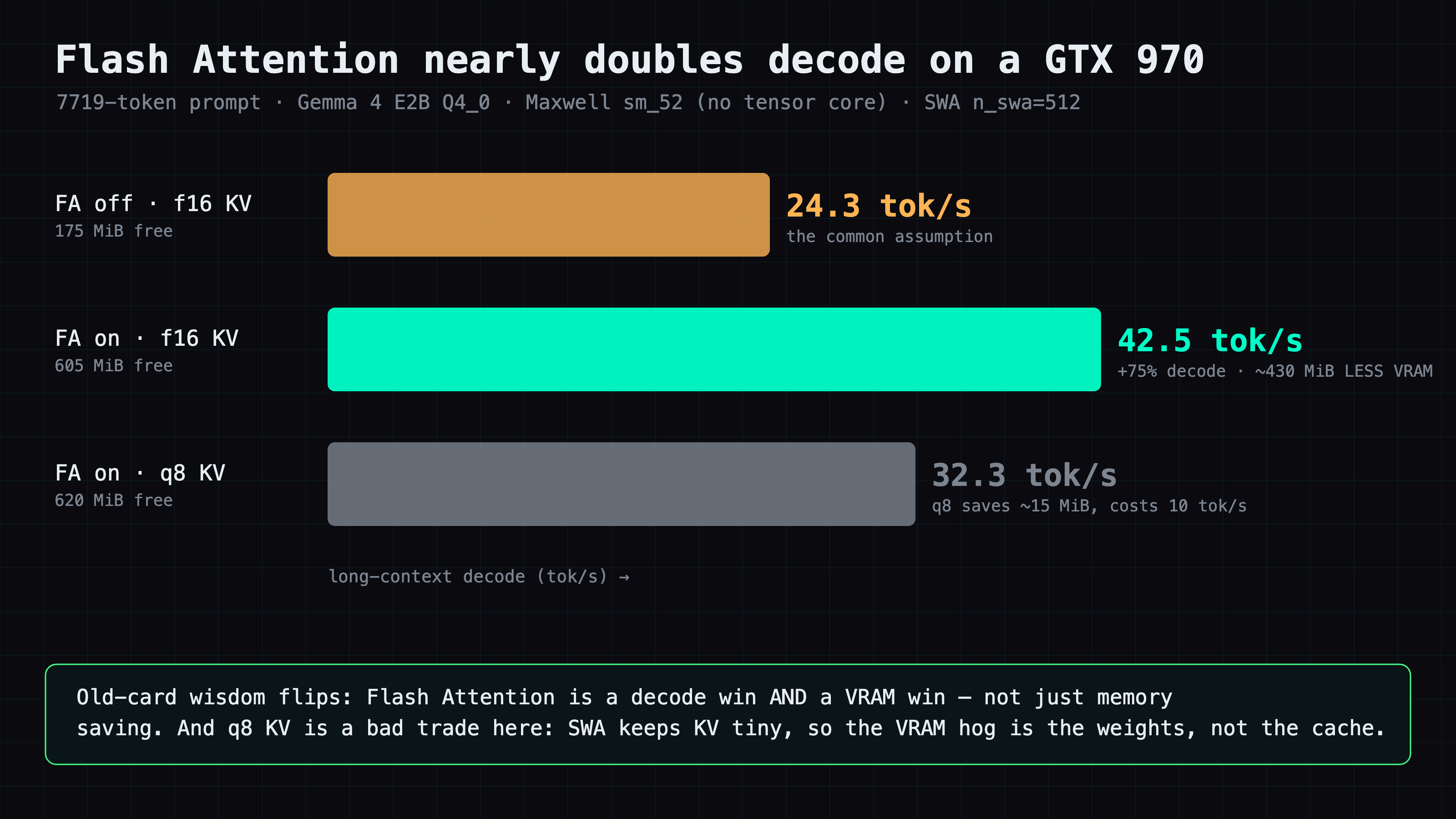
With KV held at f16, flipping Flash Attention on took decode from 24.3 to 42.5 tok/s — a 75% jump, nearly double. Short-context decode sat around 42–47 tok/s across all three settings, so the gap only opens up once the prompt is long. The decode numbers reproduced: two runs of the f16 config landed at 42.86 and 42.48, two runs of q8 at 32.37 and 32.34. This isn't noise.
That directly contradicts the assumption I walked in with. Flash Attention is associated with tensor cores, so the folk wisdom is that on a Maxwell card it does nothing useful, and you should leave it off. On this card, leaving it off cost me 43% of my decode speed on long prompts.
One honesty note: I also logged prefill/TTFT numbers, but they were single-shot and jumped around in ways that don't make sense across configs. I didn't get clean prefill numbers across runs, so I'm not reporting them — this article is about decode, which is the part that reproduced.
Why FA wins at decode on a card that has no tensor cores
It comes down to what decode actually does. Generating one token is a single-token forward pass, and the expensive part isn't matrix math — it's moving the entire KV cache through memory to compute attention against it. The longer the context, the more KV you scan per token.
Plain attention materializes the full attention-score matrix in memory, then reads it back. Flash Attention fuses the whole attention computation into one pass and never writes that score matrix out — it streams over the KV in tiles and accumulates. On a long prompt, that's far less memory traffic per generated token, which is exactly the bottleneck during decode. So FA wins, and it wins more the longer the context — which is why short prompts looked the same and the 7719-token prompt didn't.
The tensor-core association is a red herring here. FA's decode win on this card isn't about faster matmul; it's about not shoving a big score matrix in and out of memory every step. A card with no tensor cores still benefits from moving less data.
FA also saved ~430MB — without it, 16K context barely fits
Look at the VRAM column again. FA on (f16) used 3427 MiB versus 3856 MiB with FA off — about 430MB saved, same KV precision. That fits the mechanism: if you never materialize the score matrix, you never allocate it.
And that 430MB matters on a 4GB card. With FA off, the 16K-context run left only 175MB free. That's the kind of margin where a desktop redraw or a stray allocation tips you into OOM. On this card, Flash Attention isn't a nice-to-have for speed — it's what lets a 4GB card hold 16K context at all. So FA is a decode win and a VRAM win, not just a memory-saving trick.
q8 KV cache: saved ~15MB, cost 24% of decode
Now the other instinct. Small card, so quantize the KV cache to q8 to save VRAM, right? Look at what it actually bought: 3412 MiB with q8 versus 3427 MiB with f16. That's ~15MB. Fifteen.
The reason is n_swa=512. With sliding-window attention, most layers only keep the last 512 tokens of KV, so even at a 16K context window the KV cache is already tiny. There's almost nothing to compress. The thing eating VRAM on this card is the model weights — the Q4_0 file is ~3.2GB, roughly 94% of what's resident. Quantizing the KV cache is optimizing the 6% that wasn't the problem.
And it isn't free. q8 KV dropped decode from 42.5 to 32.3 tok/s — a 24% loss — because Maxwell has no fast int8 path, so every decode step pays to dequantize the KV it just read. You give up a quarter of your speed to save fifteen megabytes. I reverted production back to f16 KV.
Takeaways
Where the time went
Not the benchmark — the assumption. I almost didn't test Flash Attention on, because "it's a tensor-core feature, it won't help a Maxwell card" is the kind of belief that feels settled enough to skip. Testing it was a few minutes; not testing it would have left 43% of my long-prompt decode on the floor and a 16K context I couldn't safely hold. The most expensive thing here was the rule of thumb I nearly trusted.
Reusable diagnostics
Two checks before you reach for the obvious knob. First: on a no-tensor-core card, turn Flash Attention on and measure decode on a long prompt — it can nearly double, because decode is bound by KV memory traffic, not by tensor-core matmul. Second, before quantizing the KV cache, check whether the model is sliding-window: if it is, KV is probably already tiny, so measure the q8-vs-f16 VRAM delta (here it was 15MB) before paying the decode tax. The lever for VRAM on a small card is usually the weights, not the cache.
The general principle
The conventional KV-cache advice — "FA is a tensor-core thing, quantize the cache to save memory" — assumes a modern, bandwidth-bound, non-SWA setup. Flip any of those and the advice flips with it. On a tensor-core-less SWA model, FA is a decode and VRAM win, and KV quantization is mostly a decode tax for a memory saving that the sliding window already gave you for free. Measure on the card you have; the rule of thumb was written for a different one.
What to actually run
- No-tensor-core card (GTX 9xx/10xx class): turn Flash Attention on (
-fa). It nearly doubled long-context decode here and freed ~430MB. - On a 4GB card running 16K context, FA isn't optional — without it the run left only 175MB free.
- Sliding-window model (Gemma 4's
n_swa=512): keep KV at f16. q8 saved ~15MB and cost 24% of decode. - Only quantize the KV cache when the model is not sliding-window and the context is long enough that KV genuinely dominates VRAM. Otherwise quantize the weights — that's where the memory actually is.
Three articles in, the GTX 970 has run four quants, a full multimodal voice assistant, and now a 16K-context long prompt — and every time, the lesson has been the same: the textbook answer was written for a card that isn't this one. The only number you can trust is the one you measured on the hardware in front of you.
One last thing I find romantic: the same SWA mechanism that makes q8 KV pointless — KV pinned at 512, context nearly free — also means this card holds 64K context for almost no memory (I've since run it at 64K for other jobs; see Part 4). And 64K is big enough that you can half-seriously wonder about pointing a Hermes agent at a 2014 card. An eleven-year-old GPU running a 2026 agent — there's something romantic about that. (Not that I'd recommend it: E2B is small and the sliding window is right there, so it's fine as a lightweight helper but it'll struggle as a real agent brain.)
Also in this series:
FAQ
- Should I turn on Flash Attention on an old card like a GTX 970?
- Yes. On a GTX 970 running Gemma 4 E2B with a 7719-token prompt, Flash Attention took long-context decode from 24.3 to 42.5 tok/s — nearly double — with KV held at f16. It also freed ~430MB of VRAM. The common assumption that FA is useless or hurts on Maxwell didn't hold up.
- Does quantizing the KV cache to q8 save VRAM?
- Not on this model. Gemma 4 E2B uses sliding-window attention, so most layers cap KV at 512 tokens and the cache is already tiny. q8 KV saved only ~15MB versus f16, and it dropped decode from 42.5 to 32.3 tok/s because Maxwell has no fast int8 path. The VRAM hog is the model weights, not the KV cache.
- When is it worth quantizing the KV cache?
- Only when the model is NOT sliding-window and the context is long enough that KV actually dominates VRAM. For a sliding-window model, or a small card, the real VRAM lever is the model weights, not the KV cache — quantize those instead.
Read next
- 2026-06-14[Just for Fun] A blog RAG support bot on a GTX 970: no torch, no vector DB, no LangChain
A retrieval-augmented support bot for my blog, running on a 2014 GTX 970 and a ~600MB embedding model. llama.cpp embeddings on CPU, numpy brute-force cosine over 3,475 chunks, an embedding-score guardrail, and Cloudflare Tunnel.
- 2026-06-09[Just for Fun] Gemma 4 E2B on a GTX 970: the biggest quant runs fastest (47.6 tok/s)
Four Gemma 4 E2B quants on a 2014 GTX 970. The bigger 3.2GB QAT Q4_0 beats the 2.9GB Q2_K — 47.6 vs 32.8 tok/s — because a tensor-core-less Maxwell card is dequant-bound, not bandwidth-bound.
- 2026-06-09[Just for Fun] A GTX 970 as an offline voice assistant: Gemma 4 E2B + Piper TTS (2.8s end-to-end)
A 2014 GTX 970 running Gemma 4 E2B (vision + audio) plus Piper TTS — a full offline voice assistant that sees, listens, talks back, and writes code. ~2.8s end-to-end, ~$15 of hardware.
- 2026-07-03[Just for Fun — Advanced] I Doubled My Agent's Decode Speed and It Got Slower: TTFT Is the Number You Actually Feel
I swapped my home agent's brain for one that decodes 30-40 tok/s instead of 14, and it felt slower. The number I'd stared at for a year — tok/s — only measures how fast tokens come out, not how long before they start. On a hybrid model, a single cache miss re-prefills the entire prompt: same box, same brain, 2.6s warm vs 216s cold. Here's the live log.
Don't miss the next one
Subscribe, and you won't.
One-click unsubscribe anytime.