改裝 2080 Ti 22G · part 4
[趣味競賽 進階 #4] 量化 draft cache 反而更慢:Qwen MTP 投機解碼的反直覺實測(f16 比 q4 快 34%)
❯ cat --toc
TL;DR
這張 22G 卡塞著 15.7GB 的 27B 權重 + 128K context,能省記憶體的地方我都省:主 KV 量化成 q4。那 MTP 的 draft cache 順手也量一下吧——它只是個小草稿模型,直覺上穩賺。測下去整個打臉:q4 draft cache 跑 29.6 tok/s,不量化的 f16 反而 39.7——慢的是量化版,q4 比 f16 慢 25%(等於 f16 比 q4 快 34%),而且 f16 的 free VRAM 還更多。「省記憶體=量化」這個直覺,在 draft cache 上整個翻盤。拆開來看是三重損失:(1) 量化要付 dequant scratch,省下的儲存還小於 scratch → free VRAM 反而更低;(2) 量化拉低 acceptance(0.75→0.59)→ 主模型接受的 draft token 變少 → 投機效益縮水;(3) 兩者疊加 = 速度淨虧。結論很乾脆:-ctkd / -ctvd 別設,留 f16 預設——我這顆 Hina 現在的 launch 就是這樣,llama.cpp log 裡 cache_k=f16, cache_v=f16 白紙黑字。draft cache 是少數「量化淨虧」的地方。⚠️ 先標清楚:這組 A/B 是在 256K context 下跑的 same-prompt 對照,筆數不大,當實測心得讀、不當統計顯著看;機制(dequant overhead + acceptance 下降)跟 context 大小無關,所以我預期 128K 同樣是 f16 最佳——我這顆現在的 Hina 在 128K 也維持 f16(但 128K 我沒重跑同一組 A/B,這是照機制的合理推斷,不是另一組實測)。
白話導讀:不是所有 cache 量化都省記憶體
要在一張 22G 卡上塞 27B 模型 + 長 context,你會養成一個直覺:能量化的就量化。權重已經是 Q4 了,主 KV cache(模型記住對話用的那塊顯卡記憶體)也壓成 q4——少吃一點是一點。這套直覺在大多數地方都對。
然後我把同一套直覺,套到 MTP 的「draft cache」上,結果整個翻車。
MTP(投機解碼)會用一顆藏在同一個模型檔裡的「草稿頭」,一次先猜好幾個 token,主模型再回頭平行驗證、接受對的。這個草稿頭也有自己的一份 KV cache。我心想:草稿嘛,精度要求不高,量化它應該最穩賺——既然它佔記憶體(後面會看到它真的佔不少),量掉它一定省。
測下去:量化版又慢、又沒省到記憶體、acceptance 還更低。三項全輸給「什麼都不做」的 f16 預設。
這篇就是拆這個反直覺:為什麼「量化省記憶體」這個幾乎永遠對的直覺,偏偏在 draft cache 上失靈。
前言:接著上一篇那條「runtime 暫存吃 VRAM」的線
上一篇硬核篇講的是一個偵探故事:我把 context 拉到模型上限 256K,載入成功、沒報錯,然後它在真實負載下 crash——因為那張卡只剩一條髮絲般的 free VRAM,連一個 context checkpoint 都放不下。那篇的結論是:真正的天花板不是「權重塞不塞得下」,是「runtime 暫存塞不塞得下」。
這篇是同一條線往下走。上一篇我點到一個東西:除了 context checkpoint,MTP 的 draft state 也住在那條髮絲 headroom 裡——log 撈得到 total state size = 550.849 MiB (draft: 73.176 MiB) 這種行,draft 那塊不是零頭。既然它佔記憶體,那量化它來省 headroom,聽起來理所當然對吧?
這篇就是回答那個「理所當然」:量化 draft cache,不只沒省到,還連速度跟 acceptance 一起賠掉。
先講清楚 MTP 是什麼
要看懂後面那張打臉表,得先知道 MTP 在做什麼。
MTP = Multi-Token Prediction,是 Qwen3.6 內建的投機解碼機制。一般的投機解碼(speculative decoding)要你另外載一顆小的「draft 模型」來猜 token;MTP 不用——它的 draft head 就藏在同一個 GGUF 檔裡,從同一份權重長出來,不用另外一個 draft 模型檔(它仍是獨立的 draft context,只是從同一個 GGUF 載出來)。
運作方式:
- draft head 一次先猜 N 個 token(我這顆設 N=3)。
- 主模型把這 N 個 token 平行驗證(一次 forward 驗完,不用一個一個跑)。
- 猜對的就接受,猜錯的從錯的那個往後丟掉、由主模型接手。
- 接受率(acceptance)越高,等於「用一次主模型的成本,白賺好幾個 token」→ decode 加速。
llama.cpp 這邊,MTP 是 2026-05-16 隨 PR#22673「llama + spec: MTP Support」 進 mainline 的,在 Qwen3.6(官方附了 27B 與 35BA3B 兩個變體)上測試,理論上有 MTP head 的 model 都能用。開法是 --spec-type draft-mtp,猜幾個由 --spec-draft-n-max 控制。⚠️ 一個實務注意:我這顆 Hina 的 launch 一直帶 --parallel 1(一次服務一個請求)——PR 明說 MTP 的 parallel decoding「支援、但還沒最佳化」,所以我保守起見只開單請求,不是 MTP 硬性禁止多請求。
我這顆腦的 launch 大致長這樣:
--spec-type draft-mtp --spec-draft-n-max 3
-fa on -ctk q4_0 -ctv q4_0
-c 131072 --parallel 1 ...
注意:-ctk / -ctv(主 KV)我設了 q4_0;但 -ctkd / -ctvd(draft KV)我沒設——這正是這篇要解釋的:draft cache 留 f16 是刻意的,不是忘了設。llama.cpp 啟動時的 log 也會把這件事印出來(這次 forge live [log]):
common_speculative_impl_draft_mtp:
- n_max=3, n_min=0, p_min=0.00, n_embd=5120, backend_sampling=1
- gpu_layers=-1, cache_k=f16, cache_v=f16, ctx_tgt=yes, ctx_dft=yes
cache_k=f16, cache_v=f16 就是 draft cache 維持 f16 預設的證據——這顆現在的腦,draft cache 沒被量化,而下面整篇就是解釋為什麼這是對的。
直覺:量化 draft cache「應該」穩賺
先說為什麼我會去動它——這個直覺其實很合理,合理到差點騙過我。
draft cache 不是零頭。它真的佔記憶體,而且隨 prompt 長度漲。這次 forge live [log] 抓到的 prompt_save 行,draft 那欄會跟著 prompt 長度走:
| prompt 長度(token) | total state | 其中 draft |
|---|---|---|
| ~1,300 | 177 MiB | ~5 MiB |
| 3,942 | 234 MiB | 15.5 MiB |
| 18,642 | 551 MiB | 73.2 MiB |
⚠️ 這幾筆是不同時刻、不同 prompt 長度的 live 樣本(不是同一個 prompt 的 A/B),只用來證明「draft state 真實存在、且隨 prompt 變大」。我筆記裡另有一筆更長的:
total state size = 980 MiB (draft: 151 MiB),prompt 長到 38591——draft 佔到 ~15% 的 state。長 prompt 下,draft cache 一點都不小。
所以盤算很單純:既然主 KV 量化省了一截,draft cache 也佔到上百 MiB,量掉它再省一截,有什麼理由不做? 何況它只是個草稿,精度要求理論上比主模型低。
這個直覺對了一半:draft cache 確實值得算它的記憶體帳。但答案是反直覺的——算完帳你會發現,量化它是淨虧。
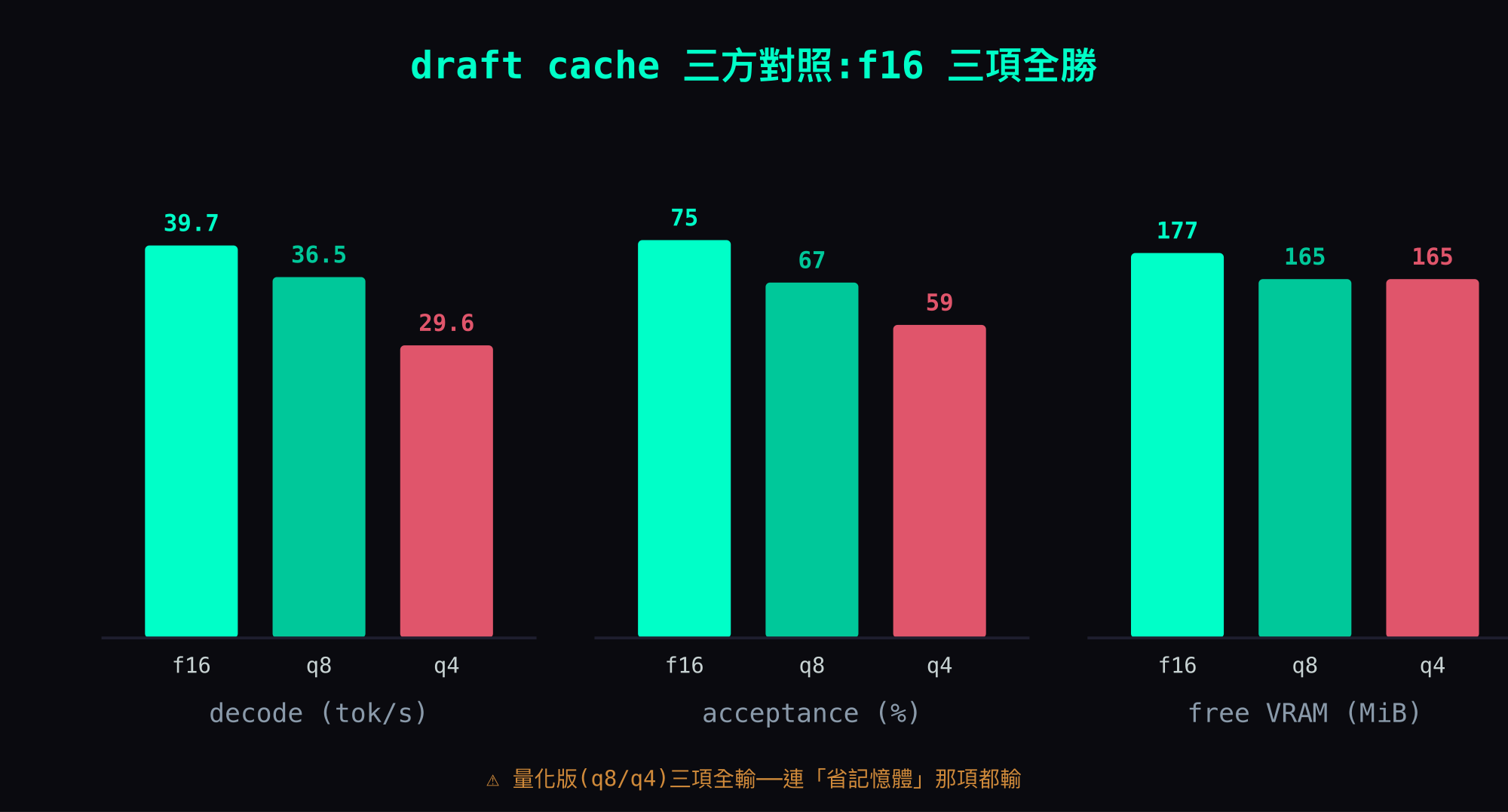
打臉:量化版三項全輸
實測下去(same-prompt 對照,全程 @256K,主 KV 固定 q4/q4,只動 draft cache 的型別):
| draft cache | decode | vs f16 | acceptance | free VRAM |
|---|---|---|---|---|
| f16(預設) | 39.7 tok/s | — | 0.75 | 177 MiB |
| q8 | 36.5 tok/s | −8% | 0.67 | 165 MiB |
| q4 | 29.6 tok/s | −25% | 0.59 | 165 MiB |
(若以最慢的 q4 為基準回看,f16 比 q4 快 34%。)
一眼就看完了:f16 三項全勝——速度最快、acceptance 最高、free VRAM 也最多(或至少持平)。
最反直覺的就是最後那欄:量化 draft cache 不但沒省記憶體,free VRAM 還比 f16 更低(177 → 165)。我本來預期量化版至少在「省記憶體」這項會贏,結果連這項都輸。「省記憶體=量化」這個幾乎永遠成立的等式,在這裡整個反過來。
拆解:為什麼會「三重損失」
打臉表很有戲,但得拆開講清楚機制,不然就只是個奇聞。量化 draft cache 同時踩了三個坑:
(a) 記憶體:dequant scratch > 省下的儲存
量化的本意是「存得小」。但量化的 KV cache 不是存著就好——每一步 decode 都要把它 dequant 回去算,這需要一塊 scratch buffer。當 cache 本身就小(draft cache 比主 KV 小很多)時,「量化省下的儲存」可能還小於「dequant 要的 scratch」,淨帳就是虧。
這也是為什麼量化版的 free VRAM 反而更低(177 → 165):省下的那點儲存,被 scratch 連本帶利吃回去。我筆記裡甚至看到 llama.cpp 的記憶體 estimate 呈現 f16 < q4 < q8——量化版的估計值反而更大,跟「量化一定省」的直覺完全相反。
⚠️ 「estimate f16 < q4 < q8」是我筆記的觀察(
[memory]),不是這次 live 復抓的截圖。當旁證看——它跟 free VRAM 那欄(量化版更低)是同一個故事的兩面;要釘死數字的話得補一張 estimate log。
(b) acceptance:量化讓 draft 猜得更差
這是更致命的一刀。draft cache 量化 → draft head 拿到的歷史精度下降 → 它猜得更差 → 主模型平均接受的 draft token 變少。表上看得很清楚:acceptance 從 f16 的 0.75,一路掉到 q8 的 0.67、q4 的 0.59。
投機解碼的整個收益,就建立在 acceptance 上:接受率高 = 一次主模型成本白賺好幾個 token;接受率低 = 猜了一堆被打回,白費功。把 acceptance 從 0.75 砍到 0.59,等於把 MTP 的加速比直接打折。
acceptance 本來就隨內容浮動——這次 forge live [log] 同一顆 f16 腦,不同 task 量到 0.42 到 0.95 都有(mean acceptance length 2.27 到 3.84),per-position 接受率也是一路遞減(例:(0.865, 0.757, 0.595),猜越後面越不準)。正因為它浮動這麼大,A/B 一定要 same-prompt——拿不同 prompt 比 acceptance,等於拿不同考卷比分數,沒意義。
(c) 兩者疊加 = 速度淨虧
(a) 給你額外的 dequant overhead,(b) 給你更低的 acceptance(等於更少的白賺 token)。兩個一起作用,decode 就雙重縮水。f16 → q4 慢 25%(反過來 q4 → f16 快 34%),就是這兩刀疊出來的。

為什麼這跟一般「KV 量化省記憶體」不一樣
正常情況下,量化主 KV cache 是划算的——主 KV 大(128K context 下幾 GB 起跳),省下的儲存遠大於 dequant scratch,而且主 KV 量化不直接拉低 acceptance(它就是 ground truth)。這也是為什麼我這張卡的主 KV 必須量化成 q4:不量化,128K context 根本塞不進 22G。
draft cache 的性質完全不同:
- 它小——小到「省下的儲存」可能輸給「dequant scratch」。
- 它直接餵 acceptance——量化它就是在汙染 draft 品質,投機效益跟著縮。
所以同樣一個動作(量化 KV),套在主 KV 上是淨賺,套在 draft cache 上是淨虧。差別不在「量化」本身好不好,在這塊 cache 大不大、它影不影響 acceptance。
這跟 GTX 970 系列 Part 3 是姊妹結論:那邊我發現「SWA 模型量化主 KV 幾乎沒省、還拖慢 decode」,這邊是「量化 draft cache 淨虧」。兩個都是「量化 KV 不一定划算」的反直覺案例——重點永遠是先算帳,別憑直覺。
結論:draft cache 別量化
一句話帶走:
-ctkd / -ctvd 別設,留 f16 預設。 draft cache 是少數「量化淨虧」的地方——它太小,省下的儲存輸給 dequant scratch;它又直接餵 acceptance,量化等於賠掉投機加速比。為了省幾十 MiB 賠掉這兩樣,賠了夫人又折兵。
這結論跟 context 大小無關。我這組 A/B 是在 256K 下跑的(當時 daily 還在 256K,後來退回 128K——見上一篇);dequant overhead 跟 acceptance 下降這兩個原因在 128K 一樣存在,所以我合理推斷「f16 最佳」在 128K 同樣成立——我這顆現在的 Hina 至今 draft cache 維持 f16(就是上面那行 cache_k=f16, cache_v=f16)。⚠️ 老實說:128K 我沒重跑同一組 A/B,這句是照機制的推斷,不是第二組實測。
下次想量化 cache 前,先想這幾條
- 量化 KV ≠ 一定省記憶體。 當 cache 小、且每步 decode 都要 dequant 時,scratch overhead 可能吃掉省下的儲存,甚至淨虧。先量「省下的儲存 vs scratch overhead」,別憑直覺量化。
- draft cache 特別不該量化。 它直接決定 draft 品質 → acceptance → 投機加速比。為了省幾十 MiB 賠掉 acceptance,是這篇最貴的教訓。
- 投機解碼的瓶頸是 acceptance,不是 draft cache 的大小。 想加速,力氣花在「讓 draft 猜得準」,不是「讓 draft cache 變小」。
- A/B 一定 same-prompt。 acceptance 隨內容浮動很大(live 0.42–0.95),不固定 prompt 的對照沒有意義。
誠實聲明(明擺著,不藏)
這篇是實測心得,不是 controlled benchmark,限制全攤開:
- 這組 A/B 在 256K 跑的(當時 daily context;現已退 128K)。「f16 最佳」我推斷 128K 同樣成立(跟 context 大小無關),但沒在 128K 重跑同一組 A/B;而且表上的 free VRAM(177/165/165)是 256K 那條髮絲區間的數字,別跟上一篇 128K 的 ~2GB free 混用。
- 筆數 / 重複次數沒記:same-prompt 對照,但不是大樣本統計,別當顯著性看。
- decode 絕對值(39.7 等)是 @256K same-prompt;跟別篇 / live 的 ~28-40 tok/s(128K、不同 prompt)不衝突但 context 不同,只引「f16 > q8 > q4 的相對結論」,別交叉引用絕對數字。
- 「estimate f16 < q4 < q8」是
[memory]觀察,不是這次 live 截圖;當旁證看,要釘死得補一張 estimate log。 - live 佐證的部分(draft-mtp config
cache_k=f16、draft acceptance 0.42–0.95、total state size … (draft: N MiB)隨 prompt 漲)都是這次 forge live[log]復抓,跟筆記方向一致。
同系列其他篇:
- (上一篇 · 硬核篇)把 context 拉到 256K 然後 crash:VRAM 跟 context 的數學(draft state 也吃那條髮絲 headroom)
- (下一篇)為什麼 30 tok/s 體感比別台的 14 還慢:TTFT 才是兇手(MTP 把 decode 拉高了,但體感看的是 TTFT)
前傳:
- GTX 970 系列 Part 3:q8 KV 是個壞主意(SWA 模型量化主 KV 幾乎沒省)(「量化 KV 不一定划算」的姊妹案例)
常見問題
- 什麼是 MTP?跟一般投機解碼有什麼不一樣?
- MTP = Multi-Token Prediction,Qwen3.6 內建的投機解碼。一般投機解碼要另外載一顆小的 draft 模型來猜 token,MTP 不用——它的 draft head 就藏在同一個 GGUF 檔裡,從同一份權重長出來。它一次猜好幾個 token,主模型再平行驗證,接受幾個算幾個,decode 就加速。llama.cpp 用 --spec-type draft-mtp 開,2026-05-16 隨 PR#22673 進 mainline,在 Qwen3.6 上測試(不限 Qwen,有 MTP head 的 model 都能用)。
- 為什麼量化 draft cache 反而更慢?
- 三重損失疊加。第一,它根本不省記憶體:量化版要付 dequant scratch buffer,省下的儲存比 scratch 還小,free VRAM 反而更低。第二,它拉低 acceptance——draft 品質下降,主模型平均接受的 token 變少,投機效益縮水。第三,前兩個疊起來就是速度淨虧。實測 q4 比 f16 慢 25%(反過來看 f16 比 q4 快 34%),acceptance 從 0.75 掉到 0.59,free VRAM 還更少。
- 所以結論是 KV cache 都別量化嗎?
- 不是,別這樣讀。這篇只講 draft cache(-ctkd/-ctvd)別量化。主 KV(-ctk/-ctv)量化成 q4 是另一回事,而且在我這張 22G 卡上是必要的——不量化主 KV,128K context 根本塞不下。draft cache 特別不該量化是因為它直接餵 acceptance,為了省幾十 MiB 賠掉投機加速比,賠了夫人又折兵。主 KV 量化是為了塞 context,兩件事別混談。