改裝 2080 Ti 22G · part 5
[趣味競賽 進階 #5] 別讓助理每次都重讀整本對話:KV cache 存硬碟,回神快 7 倍
❯ cat --toc
TL;DR
對話一長,本地模型每傳一句都要先把整段「重讀」一遍(re-prefill)才回你——重開、或被別的工作擠掉快取之後特別痛,這正是 Part 3 結尾說的「30 tok/s 體感比 14 還慢」的真兇:你等的是開頭(TTFT),不是吐字。stock llama.cpp 有「把 KV cache 存硬碟」的機制(--slot-save-path),但不會自動做(內建自動化的 feature 被官方標 not planned)。我寫了一支 ~60 行、零依賴的 reverse-proxy,每個請求自動 restore/save,讓重讀變成讀存檔:5K 對話 9.9 秒 → 1.4 秒,快 7 倍(28K 對話推估 25–40×)。先把話講在前面:這招我驗證過能跑,但目前 daily 還沒切過去——原因最後講。
白話導讀:它不是回得慢,是每次都從第一頁重讀
打電動存過檔吧?打到第三關,關掉遊戲;下次打開,讀檔,直接回第三關——不會叫你從第一關重打。
本地 AI 助理少了這個存檔。
你跟它聊了很長一段(幾萬字的對話),它其實是把這整段話「讀進腦袋」後才開始回你的。這個「讀進去」的步驟叫 prefill。正常情況下,讀完的狀態會留在 VRAM(顯卡記憶體) 裡,下一句接著用,很快。
問題是這份「讀完的狀態」很容易不見:服務一重開就沒了、被另一個任務擠掉也沒了、太久沒用被清掉也沒了。一旦沒了,你下一句話它就得把整段對話從頭重讀一遍——對話越長,你每一句開頭就等越久。打電動的話,等於每次都從第一關重打到第三關,才讓你繼續玩。
這篇就是幫它補上「存檔/讀檔」:把那份讀完的狀態存到硬碟,下次直接讀檔(不到 1 秒),不用重讀整本(10 秒起跳)。
前言:接著 Part 3 那條「為什麼慢」的線
Part 3 在查 VRAM 去哪了的時候,結尾埋了一條線:這個 hybrid 的 Qwen3.6 模型,「30 tok/s 的吐字速度,體感卻比別台 14 還慢」——因為你看到的不是 decode,是 TTFT(送出去到第一個字之間的等待),而 TTFT 被「整段重讀」吃掉了。
這篇就是那條線的解。
設定一樣:一張二手改裝的 22G RTX 2080 Ti,llama.cpp serve 一個常駐的 Qwen3.6-27B 模型當 agent。常駐 agent 的特性是「很長的對話 + 偶爾重開/被打斷」——剛好是最容易踩到「重讀」的場景。
先搞懂:你等的那 10 秒,是「重讀」不是「想」
先把「慢」拆開。一句話的回覆分兩段:
- prefill(讀題):把整段對話讀進 KV cache。這段隨對話長度線性變慢。
- decode(吐字):一個字一個字生出來。這段是固定速度(那個「30 tok/s」)。
對話短時,prefill 一下就過,你幾乎只感覺到 decode。但對話養到幾萬字、又碰上快取沒了,prefill 的時間會拉到好幾十秒——你盯著畫面,它一個字都還沒吐,因為它在「重讀整本」。這就是為什麼「30 tok/s」騙人:decode 不慢,慢的是你根本還沒等到 decode 開始。
那份讀完的狀態(KV cache)會在三種情況下消失,逼它重讀:
- 服務重開——冷啟動,VRAM 裡什麼都沒有。
- 被別的工作擠掉——我這個模型同時被拿來壓縮對話、跑別的 sib,單一 slot 被換內容,你原本那份就被擠掉了。
- 太久沒碰被清掉——RAM 那層快取有上限,LRU 淘汰。
常駐 agent 這三種天天遇到。所以「重讀」不是偶發,是日常稅。
llama.cpp 有「存硬碟」這招,但它不會自己用
好消息:llama.cpp 其實內建了把 KV slot 存到硬碟的機制。壞消息:預設關著,而且要你自己開口叫它做。
它有兩種快取,但「自動 + 撐得過重開」這個組合是空的:
| 快取 | 開法 | 自動? | 撐過重開? |
|---|---|---|---|
| RAM 快取 | --cache-ram N(預設開) | ✅ 自動 | ❌ 重開就清空 |
| 硬碟存檔 | --slot-save-path DIR | ❌ 要 client 自己呼叫 API | ✅ 存在硬碟 |
開了 --slot-save-path DIR,它會開放一支 API:
POST /slots/<id>?action=save {"filename":"x.bin"} # 把目前 slot 存成檔
POST /slots/<id>?action=restore {"filename":"x.bin"} # 從檔還原 slot
(沒開那個 flag 就呼叫 → 回 501。)
那為什麼不乾脆內建「自動存硬碟、撐過重開」?有人提過這個 feature request(#17107),官方標成 not planned(不打算做)。這不是偷懶,是設計取捨:llama-server 只負責存跟讀;什麼時候存、用哪個 key,client 自己決定。
意思是:stock llama.cpp 想要「自動 disk-KV」,只能從外部自己驅動。那就來驅動它。
機制驗證:hybrid Qwen 存得起來、讀得回來、不 crash
在動手寫自動化之前,先確認這個 hybrid 模型存/讀 KV 不會壞(hybrid 模型的 recurrent 狀態,以前 restore 就有人踩過雷)。
forge 上實測(約 4K token 的暖 slot):
save → 211ms,檔案 219MB
restore → 87ms,還原後 /health = ok,沒 crash
87 毫秒讀回一份 4K 的對話狀態。對照冷重算動輒幾十秒,這個差距就是整篇的重點。幾個限制先誠實講清楚:
- 只能 text-only:載了 vision(mmproj)會擋住 slot-save(#21133)。我這個模型沒掛 vision,過。
- 檔案隨長度線性長大:4K≈219MB → 50K 對話約 2.7GB。1TB 碟放得下,但要定期清。
- SWA 類模型若要把完整 context 的 KV 存下來,要加
--swa-full(否則 SWA 的 KV 是滑動視窗,存回來不完整)。
機制 GO。剩下的是:怎麼讓它「自動」在對的時機存/讀,而我不用改 agent。

解法:一支 60 行的 proxy,把「重讀」換成「讀存檔」
核心想法很笨但有效:在 agent 跟 llama-server 中間夾一支 reverse-proxy,每個請求進來時自己判斷要不要 restore、回完再 save。agent 完全無感,不用改它一行。
你的 agent →(proxy :8080)→ llama-server :8081
每個 /v1/chat/completions 進來,proxy 做四件事:
- 從請求算出一把 key(這是哪一段對話,例如 session id)。
- 如果記憶體裡現在那份不是這段對話、而硬碟上
<key>.bin存在 → 先action=restore把它讀回來。 - 轉發請求給
llama-server、把回應串回去。 - 回完 →
action=save把這份存成<key>.bin。
我寫成 kvproxy.py——Python 標準庫、零依賴(ThreadingHTTPServer,一把 threading.Lock 讓單一 slot 的請求排隊)。forge 本來就有 Python 3.13,丟上去就跑。
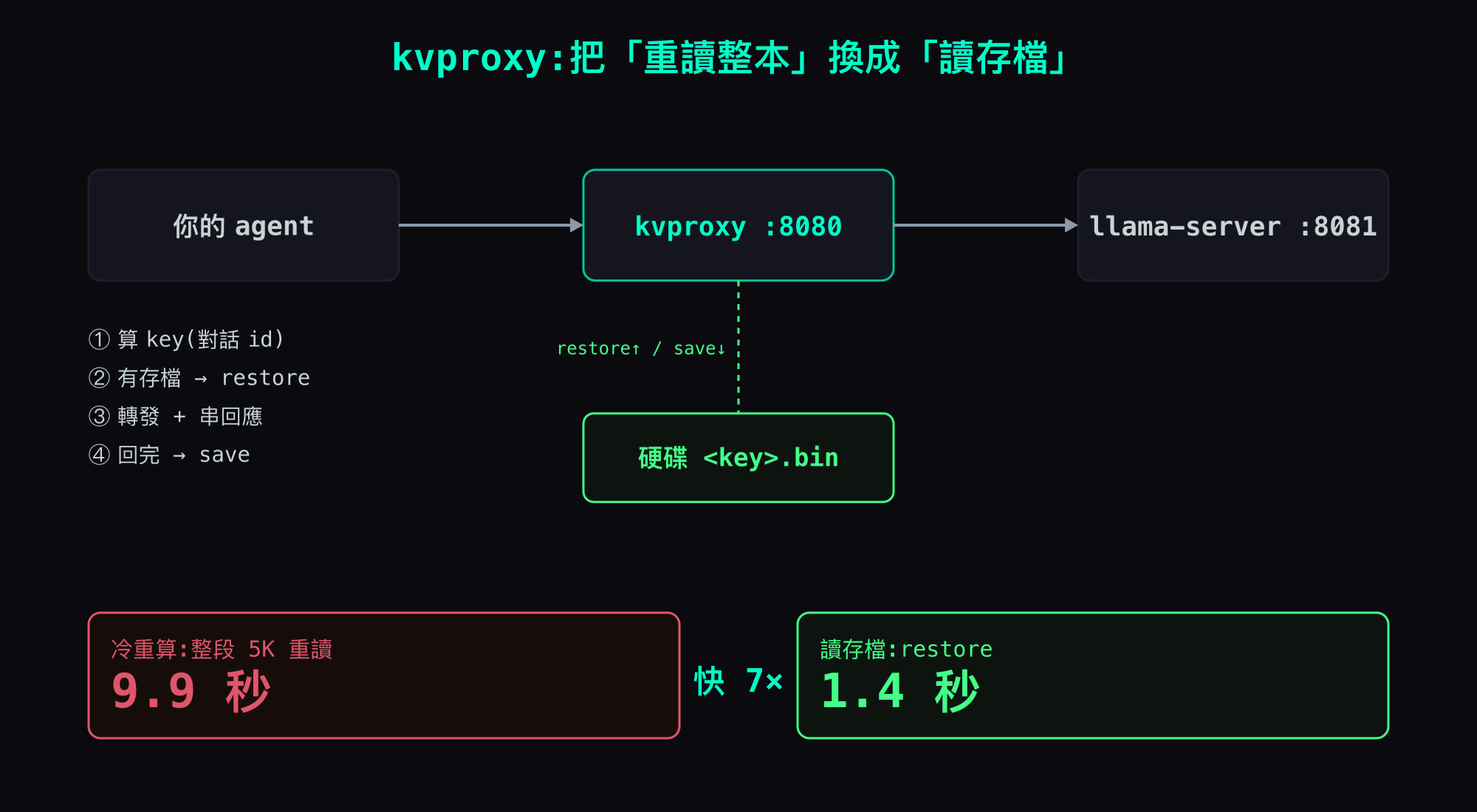
數字:5K 對話 9.9 秒 → 1.4 秒,快 7 倍
拿一段 5K token 的對話,在不影響線上的 side-port 實測:
| 情況 | 第一個字之前的等待 | 怎麼來的 |
|---|---|---|
| 冷重算(沒存檔) | 9.9 秒 | 整段 5K 從頭 prefill |
| 讀存檔(proxy restore) | 1.4 秒 | restore 0.8s + 後續 |
快 7 倍。 而且這還只是 5K——對話越長,重算越虧、讀存檔越划算:28K 的看板對話,re-prefill 量到 ~46 秒,推估讀存檔會落在 1–2 秒,約 25–40×(這條是推估,還沒在 28K 上完整復測,先標清楚)。
社群的數字也對得上:有人在 RTX 3090 上量到 restore ~0.2 秒 vs 冷 prefill 一分鐘以上(#20572)。
順帶一提,我沒從零硬幹——先去翻了現成的(neshat73/proxycache,一個實驗性的 FastAPI 版,跟我的 pattern 幾乎一樣)。它非 production、README 連結還壞著,但streaming 的接法、cache_prompt:true + n_keep:-1 要塞進轉發的 body、只對大請求才存/讀這些細節值得抄進我自己那支。
誠實轉折:驗過 7×,但我目前還沒切過去
如果寫到這裡收尾,故事太漂亮了。但其實有個但書,而且我覺得它比「快 7 倍」更該寫。
我 daily 還是跑 RAM 快取,沒切到這支 proxy。 原因兩個:
- 這個模型平常不太重開——RAM 快取暖著的時候,接話就 4–7 秒,夠用。disk-KV 的最大價值在「跨重開」,而我重開不頻繁。
- 還有些尾巴沒收完:單 slot 多段對話會互搶(
--parallel 1)、存檔每份 244MB 要做 LRU 清理、key 到底用prompt_cache_key還是前綴 hash 要在 production log 裡再確認。proxy prototype 驗證了核心,但要 24/7 掛上去還差這些。
所以結論很單純:這招驗過、能跑、也真的快 7×;只是上面那些尾巴還沒收完,平常我還是先跑 RAM 快取。 --slot-save-path 已經開著等,哪天真的值得了,再把 client 接上去就行。
收穫
最花時間的地方:不是寫那 60 行 proxy,是先確認 hybrid 模型存/讀 KV 不會 crash(踩雷史一堆)+ 搞懂 mainline 為什麼不內建(以為是缺漏,讀了才知道是「機制/策略分離」的刻意設計)。題目方向先弄對,比衝實作重要。
可以搬走的診斷:體感慢先別怪 decode 速度——分開量 prefill 跟 decode。如果「第一個字之前」的等待隨對話長度暴增,你的瓶頸是 TTFT/重讀,不是模型笨也不是吐字慢。這跟換哪張卡、哪個模型無關。
通用原則:很吃效能、又會一直重複的計算,存起來別重算。 整段 prefill 是純函數(同樣的對話前綴 → 同樣的 KV),天生可快取。框架沒幫你自動做,不代表你不能從外面把它做掉——server 給你存/讀的 API,什麼時候存、怎麼命名,你自己接。
接下來
這篇把 Part 3 那條「為什麼體感慢」的線收掉:真兇是重讀(re-prefill),而 stock llama.cpp 的 --slot-save-path + 一支 proxy 就能把它變成讀存檔(快 7×),只是我選擇先把它當保險、daily 仍跑 RAM 快取。
同系列其他篇:
常見問題
- 為什麼對話越長,AI 每次回覆前就等越久?
- 因為它回你之前,要先把整段對話「讀進」KV cache(這步叫 prefill)。一般情況下這份 cache 留在 VRAM,下一句接著用、很快。但只要 cache 沒了(服務重開、被別的工作擠掉、或冷啟動),它就得把整段對話從頭重讀一遍(re-prefill)——對話越長,這個「重讀」越久。你以為慢的是「吐字速度(decode)」,其實多半是這個開頭的等待(TTFT)。
- llama.cpp 可以把 KV cache 存到硬碟、避免重讀嗎?
- 機制有、但不自動。開 `--slot-save-path DIR` 後,llama.cpp 會開放 `POST /slots/<id>?action=save|restore` 讓你手動存/讀 KV slot 到硬碟。但它不會自己做——「自動存硬碟、撐過重開」這個功能的 feature request(#17107)被官方標成 not planned。所以 stock llama.cpp 想要 disk-KV,只能從外部驅動(自己呼叫那支 API)。
- 存一份 KV cache 到硬碟多大、restore 多快?
- 實測(hybrid Qwen3.6、約 4K token 的 slot):存檔 219MB、save 211ms、restore 87ms,還原後服務正常不 crash。檔案隨對話長度線性長大——50K token 的對話約 2.7GB。restore 比冷重算快非常多:我量到 5K 對話 9.9 秒重算 vs 1.4 秒讀檔=快 7 倍。