改裝 2080 Ti 22G · part 6
[Just for Fun — Advanced] The Tool-Definition Tax: 17K Tokens Before I Say a Word, Re-Billed on Every Cache Miss
❯ cat --toc
- The short version: an agent pays a cover charge before it speaks
- Why I'm digging in: picking up the disk-KV thread — what exactly gets recomputed?
- Anatomy of the floor: tools are 73% of it
- The fattest manuals
- Why this becomes a *per-round* tax (the whole point)
- To be clear: this tax is bursty, not 16x every round
- The right fix is not cutting tools
- The bottom line: this is context economics, not a tooling problem
- Full disclosure (out in the open, not buried)
TL;DR
I added up the cover charge my home agent brain (Hina, a Qwen3.6-27B on a modded 2080 Ti) pays before it answers anything. Before it reads a single word from me, the prompt already carries about 23K tokens — and 17,434 of them (measured) are just JSON instruction manuals for 39 tools, roughly 73% of the floor. On a normal transformer that's a one-time cost: prefill once, cache it, reuse it. But this is a hybrid model, and llama.cpp can't reuse the prefix cache on hybrid models, so any cache miss forces a full re-prefill — the 17K gets recomputed. And a single user turn routinely runs 6 to 16 tool rounds — measured spikes past 30 — so that 17K can be recomputed a dozen-plus times in one turn. Two takeaways: this is context economics, not a too-many-tools problem; and the fix isn't cutting tools, it's loading them on demand the way skills already do. Up front: the token counts are char/4 estimates, not tokenizer-exact — the trend is solid, the exact values may move a bit.
The short version: an agent pays a cover charge before it speaks
You walk into a bar and get charged a cover before you order a thing. That's the situation my home agent brain is in every time it answers.
It can do a lot: schedule cron jobs, delegate tasks, open a terminal, search, drive a kanban board. Every one of those abilities is backed by a "tool." And for the model to know how a tool works, you have to put that tool's instruction manual — a JSON blob: what it's called, what parameters it takes, what each one means — into the prompt on every request.
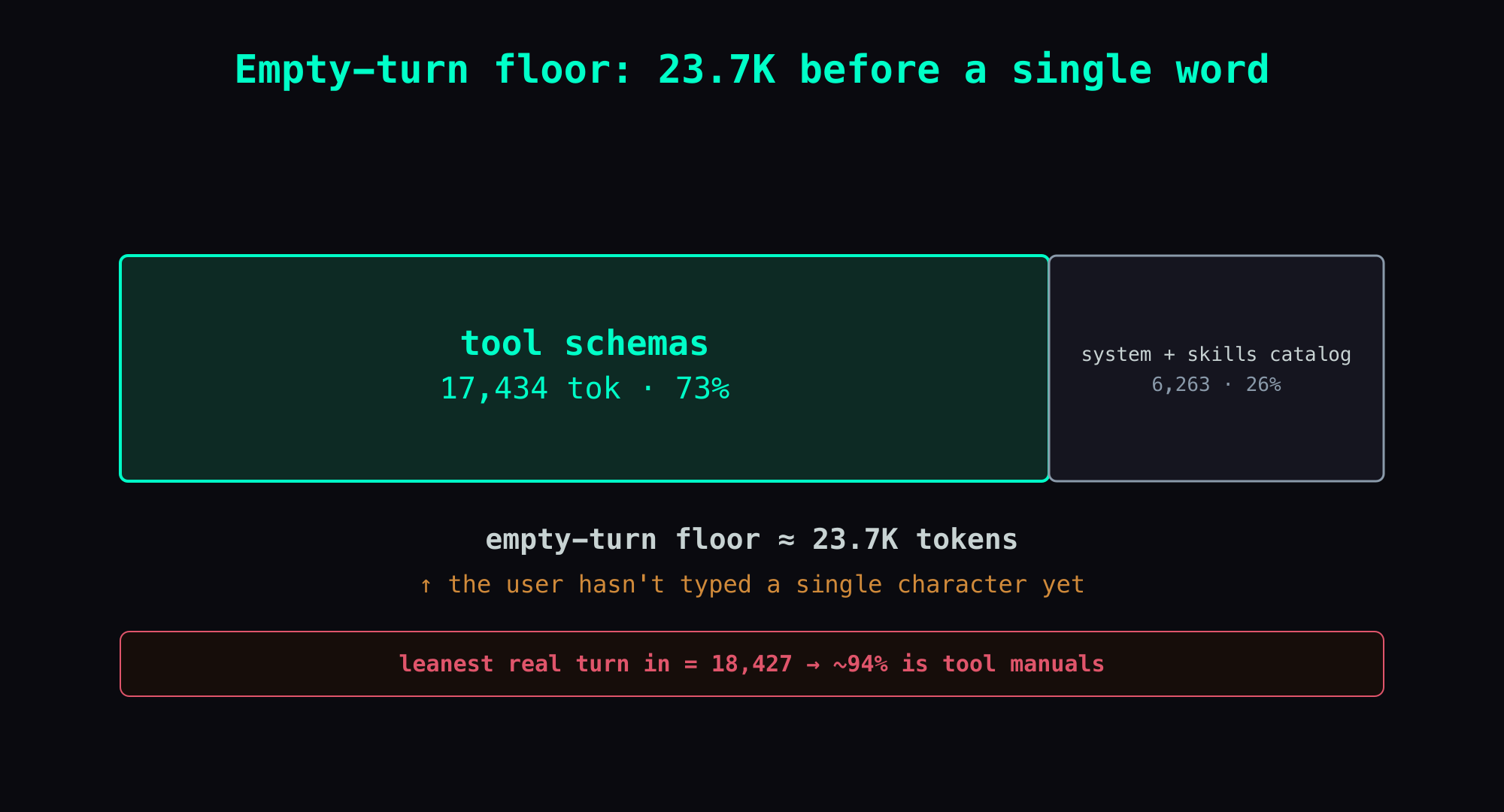
I have 39 tools. Add up all 39 manuals and you get about 17,434 tokens — overhead the brain eats before it has read a single character I typed. Add the system prompt and the whole "empty-turn floor" starts around 23K tokens.
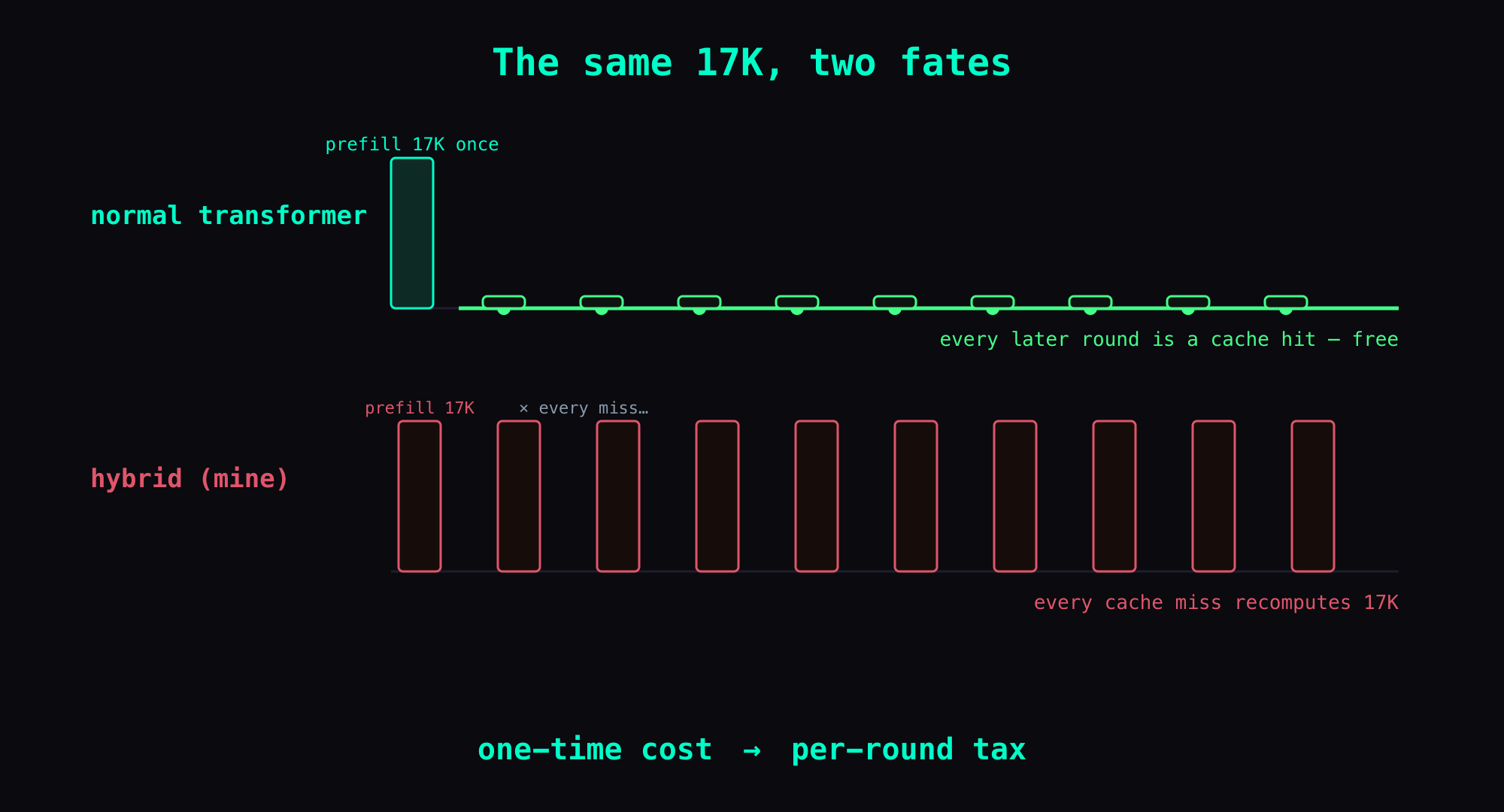
If this were a normal model, you'd pay that bill once: prefill it on the first round, cache it, and reuse the cache every round after. The problem is that this is a hybrid model, and it can't reuse that cache — on any cache miss it re-processes the entire prompt (those 17K tool manuals included) from scratch. So a one-time cover charge becomes a tax you pay again on every miss.
This post is about that tax: where it comes from, why it's so expensive, and why the right fix is not to cut tools.
Why I'm digging in: picking up the disk-KV thread — what exactly gets recomputed?
The previous post (#5, the one about saving the KV cache to disk) covered this: on a cache miss, this hybrid model re-processes the entire prompt from scratch, which blows up TTFT — the wait before the first token — and the fix is to store the computed KV on disk and restore it next time instead of recomputing. That post proved one thing: recomputing is expensive — expensive enough to be worth saving.
That post was about how to avoid recomputing. This one looks at the ledger: if every cache miss re-processes the whole prompt, then what's actually in that prompt, and which part is the expensive one?
The answer is a little surprising. The biggest chunk isn't my conversation, and it isn't the system prompt. It's the tools' instruction manuals.
And I need to state my methodology upfront so nobody mistakes this for exact accounting: every token number below is a char/4 estimate. I pulled a real request dump — the full body sent to the model — and divided the character count of its tools field by 4. Qwen's own tokenizer would land somewhere a little different, but the conclusion is unmistakable. Read these as orders of magnitude, not as decimal-precision accounting.
Anatomy of the floor: tools are 73% of it
Here's the bill. The dump I pulled is the full body of one real request from the evening of June 21 ([log]). Broken down:
| Component | Tokens (est.) | Share of floor |
|---|---|---|
| Tool schemas (39 tools) | ~17,434 | ~73% |
| System prompt (already includes the skills catalog) | ~6,263 | ~26% |
| Empty-turn floor, total | ~23.7K | — |
⚠️ One measurement detail worth being precise about: the dump's system message is a single 25,052-character block (~6,263 tokens), and it already contains the skills catalog inside it ([log]:
skill_viewshows up at character 2,184 and a## Skillssection at character 10,664). So don't add "system ~6,263" and "skills ~3,700" as two separate line items — the skills catalog lives inside the system block. The clean, defensible numbers are just two: tools = 17,434 tokens (measured) and system+skills block = 6,263 tokens (measured), floor ≈ 23.7K.
There's no getting under this floor. I went through the whole agent log, and the leanest real turn this brain ever logged had in= 18,427 tokens ([log]). That was a turn where the user sent a one-liner and the system block was squeezed about as small as it gets — and it still ate 18K, with the tool schemas alone (~17.4K) accounting for over 90% (~94%) of even that leanest turn. In other words: even if I type nothing, even if I trim everything else to the bone, this brain still has to chew through all 17K of tool manuals first. (The ~23.7K in the table above is a snapshot of this particular dump — the system block flexes with conversation state and which skills are loaded, so "leanest turn 18,427" coming in below "snapshot floor 23.7K" isn't a contradiction: both point to the same thing: the tool schemas are the part doing the damage.)
The fattest manuals
Those 39 manuals aren't evenly sized; a handful are unusually fat. Measured from the same dump, the top 12 ([log]):
| Tool | Tokens (est.) |
|---|---|
| cronjob | 1,802 |
| delegate_task | 1,734 |
| terminal | 1,349 |
| session_search | 1,268 |
| kanban_create | 1,077 |
| skill_manage | 1,036 |
| kanban_complete | 846 |
| execute_code | 676 |
| memory | 544 |
| patch | 482 |
| search_files | 446 |
| send_message | 412 |
Just the two fattest (cronjob + delegate_task) come to ~3,500 tokens — longer than a lot of people's entire conversations. And every one of these gets fed back through the model on every cache-miss round (the next section explains why).
One small correction, for the record: these are a few tokens higher than what my earlier handoff notes recorded (cronjob 1,791, delegate_task 1,732, …). That's because I re-pulled the dump and re-counted, and the character count came out a touch more complete this time. The trend and the ranking are identical — I'm using this session's measured numbers.
Why this becomes a per-round tax (the whole point)
This is the core of it, and it's the easiest part to wave off as "obvious — isn't that just a one-time cost?"
- On a normal transformer: the 17K of tool manuals sits at the front of the prompt (the prefix), gets prefilled on the first round, and every round after reuses that cached prefix. One-time cost; later rounds are essentially free.
- On my hybrid model: llama.cpp can't reuse the prefix cache on hybrid models (hybrid attention + Mamba2/SSM recurrent state). Any cache miss forces it to re-process the entire prompt from scratch — and the 17K of tool manuals gets recomputed right along with it.
I'm not guessing at this. It's the exact llama.cpp server log line the previous post (the disk-KV one) was built around:
slot update_slots: forcing full prompt re-processing due to lack of cache data
(likely due to SWA or hybrid/recurrent memory, ...)
And the limitation has a paper trail:
- PR #13194 ("kv-cache : add SWA support", merged): this one is the source for the SWA half of the trade-off — it introduces the limitation that SWA models can't do context caching (prefix caching, context shift, context reuse) "because token information becomes lost when the window slides." The log line above lists SWA and hybrid/recurrent; this PR covers the SWA half.
- Issue #22746 ("Eval bug: Qwen 3.6 27B forcing full prompt re-processing due to lack of cache data", status: Open): this is the one that hits my exact brain — Qwen 3.6 27B (the same model forge runs), with a log line word-for-word identical to mine, showing it checks every checkpoint, finds none usable, erases all 15 invalidated ones, and re-processes the whole 53,564-token prompt from scratch. Multiple quants (Q3_K_M / Q4_K_M / IQ4_XS…) all hit it.
- Issue #20225 ("Eval bug: Qwen 3.5 Full prompt re-processing on every conversation turn", status: Closed): the prior-generation corroboration — Qwen 3.5 (hybrid attention + Mamba2/SSM) forced into full re-processing every turn, with a 15K-token conversation taking ~8 minutes per turn instead of seconds. (⚠️ Its title says "3.5" and it's marked Closed; the one that actually hits 3.6 is the open #22746 above, so don't read the 3.5 issue's "Closed" as "3.6 is fixed too.")
Apply that to the 17K and the tax appears. Within a single user turn, the agent usually has to fire several tools in a row — do a step, look at the result, do another step, each one a fresh request with a slightly longer prompt. I counted the real log: the number of tool rounds in one user turn is commonly 6 to 16, with measured spikes to 30 and 34 ([log]). If 9 of those rounds miss the cache, that's the 17K of tool manuals recomputed 9 times in one user turn.
How long is one recompute? Cold prefill runs roughly 360-624 tok/s ([memory]), so 17,434 tokens works out to about 28 to 48 seconds per miss just to re-prefill the tool manuals.
To be clear: this tax is bursty, not 16x every round
Let me be precise so you don't walk away with the wrong conclusion: "recomputed 16 times" is the worst case, not the norm.
Cache-hit rounds (warm, 98-100% hit) pay almost none of this — the conversation lines up, the prefix is still in cache, the tool manuals don't get re-read. What blows up is the cache-miss rounds: the conversation jumped, or the model just crash-reloaded and cleared the RAM cache. So the tax is bursty — quiet most of the time, then exploding on the cold/miss rounds.
Don't read it as "every round recomputes 16x of tool manuals." The real shape is: most warm rounds pay almost nothing, and a few miss rounds pay one big chunk all at once. But because a miss round's TTFT is long and painful (the cold-recompute waits from the disk-KV post — tens of seconds, minutes on a long chat), this bursty tax hurts perceived performance far more than its average would suggest.
The right fix is not cutting tools
The reflex when you see "73% is tools" is "so cut half the tools." That's wrong.
Those 39 tools — cron, delegation, terminal, search, kanban, skills management — nearly all earn their place. Cutting them is cutting the agent's capability. Making the agent dumber to save prefill is backwards.
The real fix already has a working template inside this very system: the way skills work.
- The system prompt carries only a small catalog of skill names, not the full bodies.
- The full skill instructions load only the moment the model actually decides to use one and fires the call (via
skill_view; in this dump,skill_viewappears at character 2,184 of the system prompt [log]).
If tools worked the same way — load a tool's schema on first call instead of stuffing all 39 in upfront — that 17K floor would mostly collapse. Day to day, the model only needs to know which tools exist (a list of names); it can look up the details of a given tool when it actually wants to use it.
That's the same philosophy I leaned on with the old card in the previous series. In the GTX 970 series RAG bot post I deliberately skipped the heavy dependencies (no torch, no vector database, no LangChain) — keep it lean. On the 2080 Ti brain, the bloat that bites is the tool schema instead, but the fix is the same instinct: load only what you'll actually use.
The other path is to fix that upstream hybrid cache-reuse limitation so the 17K caches once like a normal model. But that's llama.cpp upstream work, not something I can solve by editing a prompt on a home box. Either path — "load tools on demand" or "fix the hybrid cache" — is a more sound approach than "delete capability."
The bottom line: this is context economics, not a tooling problem
This post in one line:
An agent's bottleneck is often not how smart it is, but how big a cover charge it pays before each thought. That 17K of tool manuals is a one-time investment on a model that caches; on a hybrid model that can't, it becomes a tax due on every miss round. Same schema, different cache architecture, wildly different bill.
And the counterintuitive part: the costs you'd watch for (how big the model is, how fast it runs) aren't the main driver here. The real culprit is the prefix you never look at, silently recomputed on every cache miss. Stare at decode tok/s and you'll never notice the money draining out.
As for where that cacheable prefix should actually live (RAM, automatic but volatile, or disk, durable across restarts) — the disk-KV post already answered that. This post fills in the other half: of everything getting recomputed, the fattest slice, the one to fix first, is this 17K of tool manuals.
Full disclosure (out in the open, not buried)
- Token counts are char/4 estimates, not Qwen-tokenizer exact. The magnitude and the ranking are solid; the exact values may move a bit.
- System and skills catalog overlap: the dump's system block already contains the skills catalog, so don't add 17,434 (tools) + 6,263 (system) + skills as three line items. The clean accounting is tools 17,434 + system (incl. skills) 6,263 ≈ 23.7K floor.
- "Recomputed 16 times" is the worst case: warm rounds (98-100% hit) pay almost nothing, so the tax is bursty and concentrated on cold/miss rounds — not 16x every round.
- The tool_turns numbers are a snapshot: 6-16 common, with spikes to 30/34, is the measured distribution over one slice of the agent log; it shifts across time windows.
- 39 tools is this sib's (Hina's) config; other sibs have different tool counts.
- Cold prefill 360-624 tok/s is a [memory] number, and "27-47s per miss" is the magnitude derived from it, not a per-call stopwatch reading.
What I can present with full confidence is this: the tool ledger pulled and re-measured from one real request dump, the leanest-turn floor and the tool_turns distribution mined from the full agent log, and the upstream GitHub sources that explain why hybrid can't cache. Read it as one case study in context economics, not as an accounting report.
Also in this series:
- (previous · #5) llama.cpp won't persist the KV cache to disk — a proxy makes restore 7× faster (this 17K is the fattest slice of the "recomputed prefix" that post is fixing)
- (#3) I maxed context to 256K, it loaded — then crashed: a VRAM whodunit on a 22GB card (the other side of context economics: it eats VRAM)
Prequel:
- GTX 970 series: a blog RAG helpdesk on one old card (no torch, no vector database) (the same "load only what you'll actually use" instinct)
FAQ
- What is the 'tool-definition tax,' and why is it a tax rather than a one-time cost?
- Every tool an agent can call has to include a JSON schema in the prompt — its name, parameters, and descriptions — so the model knows how to use it. My home brain has 39 tools, and those schemas alone come to about 17,434 tokens (measured this session). On a normal transformer the 17K sits at the front of the prompt, gets prefilled once, and is reused from cache every round after — a one-time cost. But this brain is a hybrid model, and llama.cpp can't reuse the prefix cache on hybrid models, so any cache miss forces a full re-prefill — and the 17K gets recomputed. That turns a one-time cost into a tax you pay again on every cache-miss round.
- So why not just cut some tools?
- That's the wrong takeaway. The 39 tools — cron, delegation, terminal, search, kanban, skills — are nearly all genuinely useful, and cutting them just makes the agent dumber. The real fix is on-demand loading, which is exactly what skills already do: the system prompt carries only a small catalog of skill names, and the full skill body loads only when the model actually calls one. If tools worked the same way — load the schema on first call instead of stuffing all 39 in upfront — the baseline overhead would plummet. The other path is to fix the hybrid cache-reuse limitation upstream so the floor caches once like a normal model. Either approach beats crippling the agent.
- Are these token numbers exact?
- They're estimates, and I'll state the method: I pulled a real request dump — the full JSON sent to the model at the moment of a request — and divided the character count of the tools field by 4 as a token estimate. Qwen's own tokenizer would shift this a little, but the trend is clear: tool schemas are the overwhelming majority of the base context floor. Separately, the agent log shows that the leanest real turn this brain ever logged had in= 18,427 tokens — and tools alone are ~17.4K, which means a turn where I've said almost nothing is over 90% tool manuals.