改裝 2080 Ti 22G · part 2
[Just for Fun — Advanced] I Gave Up 100 tok/s for 30 — Fast Isn't the Same as Useful
❯ cat --toc
- The short version: throughput is reply speed, not discipline
- Why I picked the 27B brain
- The bait: Gemma 12B at 90-100 tok/s really is great
- Where it fell apart: it finishes the work and walks away
- The core insight: the failures you can see are the tip of the iceberg — the omissions are invisible
- The other visible half: more failure signals from the logs
- Swapping the brain: Qwen 27B is slow, but it closes the loop
- The reality check: both brains went 2-for-3 — the difference is *clean wins*
- First-hand evidence: the checklist Hina wrote herself
- The bottom line: throughput isn't usefulness
- Side by side: the same kanban test on both brains
- Full disclosure
TL;DR
Picking a local model, I did what everyone does and looked at tok/s first. Gemma 12B QAT runs 90-100 tok/s — great. But once I put it on a kanban board as an agent brain, it would finish the body of a task and just stop — write the file, run the cleanup, and leave the card stuck in-progress, never calling kanban_complete. Swap in a Qwen3.6-27B at ~30 tok/s — three times slower — and the board starts behaving. Two insights here. First, a model that forgets to call a tool leaves no error line — omissions are invisible, so the success counts in your logs lie to you (the visible failures grep can find are just the tip of the iceberg, and I almost reported them as the whole story). Second, this is not "27B fixes everything": both brains went 2-for-3 on the same kanban test; the difference is that Qwen's wins were clean one-pass runs while Gemma's needed retries — and Qwen's one failure went green after a prompt fix, so even the miss points at the harness, not the engine. Up front: this is a case study, not a benchmark. Gemma's worst stretch is largely gone from the logs; what I have is lived experience plus the artifacts I could recover.
The short version: throughput is reply speed, not discipline
Everyone picks a local model by tok/s first — how many tokens a second it spits out. I did too. So I started my home agent brain on Gemma 12B: 90 to 100 tok/s, text pouring out. Who doesn't want the fast one.
The catch is that this brain isn't a chatbot. It's an agent — it sits on a kanban board, picks up a task, does it, and then has to report back to the "manager" (the board): call kanban_complete to mark it done, or kanban_block to flag where it's stuck. Gemma flew through the first part. It kept forgetting that last report — it never said "I'm done," and never said "I'm stuck" either. So nobody on the board knew what had happened, and the card sat stuck in-progress forever.
The three-times-slower Qwen 27B behaved better. That's the counterintuitive call this post is about: when a model has to stick to a workflow across a long session — do the work, close it out, update the state — instead of just returning a nice paragraph, tok/s is not the number to watch.
One bonus: when I went back to the logs to prove this, grep nearly led me astray — it counts only the failures it can see, and "forgetting" is completely invisible in a log.
Why I picked the 27B brain
Last post was about how that 27B brain got there: a second-hand 22GB-modded 2080 Ti, just enough to keep a resident agent alive on a cheap old desktop. But I skipped a question — why 27B? The box only fits one model, Gemma 12B is much faster, so why did I land on the slow one?
This post is about that decision. And I have to front-load a caveat, because it's the easiest place to mislead:
This is not a benchmark. I didn't run a controlled paired eval, and I have no clean success rate. The agent.log from Gemma's worst stretch (around June 20) was largely rotated out, and in what I can still pull, Gemma actually looks mostly fine at the aggregate level. So I can't tell you "Gemma failed X times, succeeded Y% of the time."
Then why write it? Because why the logs look that clean is itself the central insight — the worst failure mode leaves no trace at all, and I'll get to it. What I'm giving you is two days of lived experience with this agent, plus the on-disk artifacts I could recover (a checklist Hina wrote to disk herself), plus one set of screenshots running the same kanban test on both brains. Read it as a case study, not as data.
The bait: Gemma 12B at 90-100 tok/s really is great
First, why I started on Gemma at all.
The retired brain was Gemma 4 12B QAT (Huihui abliterated q4_0), at 262K context, decoding 90-100 tok/s, with vision and audio built in. On this modded 2080 Ti a 12B fits with plenty of room, and the text comes out fast and smooth. As a chat helper, as a quick ask-it-anything sidekick, it genuinely is great.
⚠️ One caveat up front: the 90-100 here and the 30-40 for Qwen below are both numbers from memory — not a fresh same-hardware paired re-run. Take them as a marketing-spec comparison, not as the axis of a controlled benchmark.
So my reasoning was simple: on the same GPU, the 12B is fast and fits. Why pick the slow one?
Where it fell apart: it finishes the work and walks away
Once Gemma was on the kanban board, the problem surfaced.
The flow is straightforward. Hina (this agent's name) picks up a card, does the task, and as the last step calls kanban_complete with a one- or two-line summary to mark it done — or calls kanban_block to explain what's missing. The "do the task" part was fine. It kept skipping the "close it out" part.
What it looked like: a long block of text, the task content all spelled out neatly, and then — it stopped. No closing report — it neither called kanban_complete to say "done" nor kanban_block to say "stuck." The card stayed in-progress forever. The board looked like nobody was working, when in fact the work was done; nobody had flipped the card or said a word.
This isn't a memory I reconstructed after the fact. Hina left a dispatch checklist on disk herself, spelling out the history in black and white (quoted below).
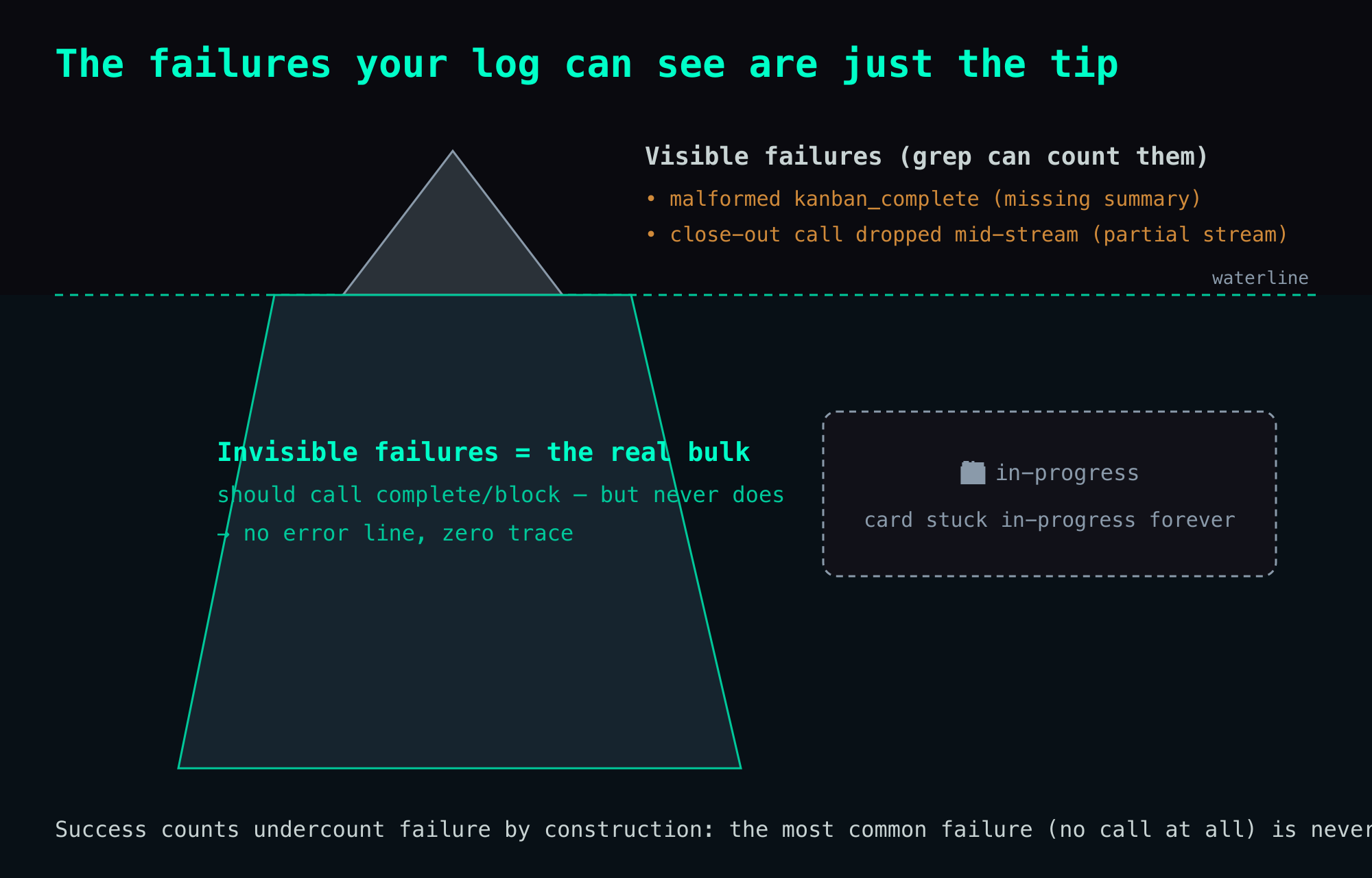
The core insight: the failures you can see are the tip of the iceberg — the omissions are invisible
This is what the post is really about — and I tripped on it once while verifying, so even this section comes with an honest correction.
Start with the failures the logs can see. The log does have the classic 12B-era malformed close-out — a kanban_complete that dropped its required summary argument and got rejected at the tool layer:
2026-06-21 11:20:46 WARNING agent.tool_executor:
Tool kanban_complete returned error (0.00s):
{"error": "provide at least one of: summary (preferred), result"}
That line (and one identical to it later in the same log) is a [live] verbatim pull from a model=gemma-4-12b session. It's exactly the failure mode this post is about, caught at the tool layer: the brain tried to mark the card done, but the call was missing a required field, so the tool refused it.
⚠️ Self-correction: I'd assumed this error line had been rotated out and I could only paraphrase it from [memory]. Re-checking the source log (on the box that hosts the agent) turned it up — still there. So that's a real live quote, not an impression. The "grep almost fooled me" story below changes too, and I'm writing it as it actually went.
There's an even more direct one — the moment a close-out call gets dropped mid-stream, caught at the transport layer:
2026-06-21 16:01:40 WARNING agent.chat_completion_helpers:
Partial stream dropped tool call(s) ['kanban_complete']
after 156 chars of text; surfaced warning to user
Read that: the model emitted 156 characters of text, then the kanban_complete call fell off mid-stream. That's about as close as the infrastructure gets to catching "finished the content, dropped the close-out" red-handed.
But here's the crux, and the easiest place to be misled: these visible failures are only the tip of the iceberg. The bulk of the failure mode is the brain never calling kanban_complete at all — it outputs a block of text and stops, and the tool layer never even sees an error. A call that should have fired and didn't leaves no line in the log.
In other words: the omissions are invisible. Count the successful calls in your log and you see a tidy run of completed, plus a handful of malformed error lines — and none of that reflects the calls that never fired. The more close-outs it drops, the cleaner the log looks. It's a metric that lies by construction: the success count undercounts failure, because the most common failure mode (just forgetting, never even starting the call) is never written down.
And that trap nearly caught me. Re-running the logs this time to dig up failure evidence, I ran a grep someone had handed me:
grep -iE 'kanban_(complete|show|block)' agent.log \
| grep -oiE 'kanban_[a-z]+|returned error' | sort | uniq -c
It returned 2 returned error. I was about to write "kanban only failed twice" and move on — which is walking straight into the trap above: taking the two visible malformed failures in the log and reporting them as the failure total. The "2" isn't a phantom — those two lines are real malformed close-out calls. The problem is that grep can only count the two it can see, and it completely misses every invisible omission where the call was never started. The visible failures are greppable; the real ones aren't in the log at all — which is the whole point: when you mine logs to measure agent discipline, what you count is the tip of the iceberg, and the omissions sit below the waterline.
The other visible half: more failure signals from the logs
Beyond those two kanban close-out failures, the slow-brain stretch left some client-facing signals too. All [live] verbatim:
- Tool loop stuck:
[Tool loop warning: repeated_exact_failure_warning; count=2; terminal has failed— the same call slamming into the same wall (this one is theterminaltool, not kanban, but it's the same kind of stall, in a 12B-eramodel=gemma-4-12bsession). - Connection reset:
Streaming failed before delivery: [Errno 54] Connection reset by peer. - Brain reloading, client eats a 503:
Streaming failed before delivery: Error code: 503 - {'error': {'message': 'Loading model', ...}}— this maps to context blowing up and the brain crash-reloading. (That 256K-OOM detective story is a later hard-core post; I'm just planting the thread here.) ⚠️ To be honest about it: the 503 isn't Gemma-specific — the Qwen 27B stretch ate plenty too. Crash-reload is a trait of this brain, not a knock on either model.
Swapping the brain: Qwen 27B is slow, but it closes the loop
Switching to the current Qwen3.6-27B Q4_K (~30-40 tok/s, MTP acceptance 0.5-0.75) made it roughly three times slower. But the board started behaving.
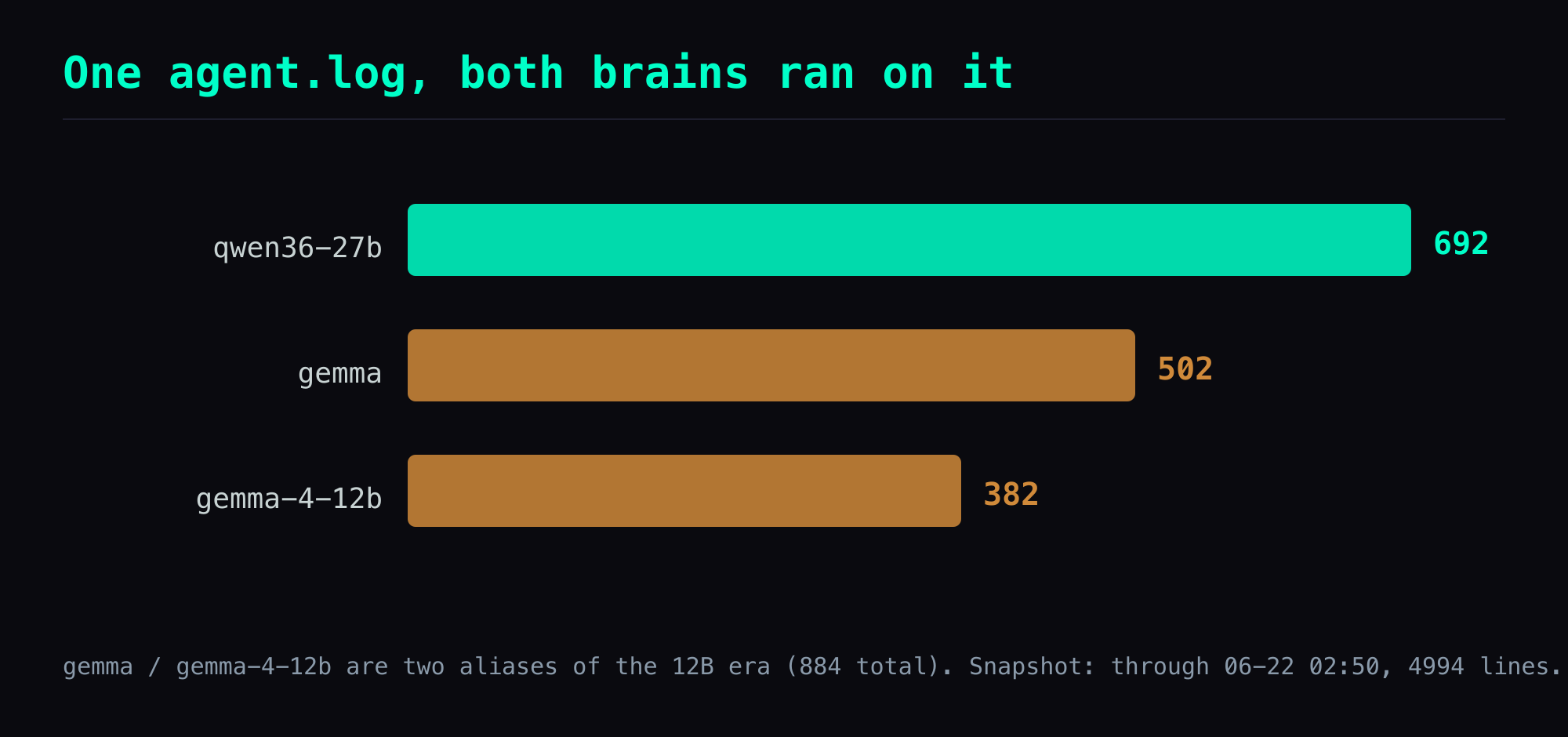
In the 27B stretch the log has a run of back-to-back kanban_complete completed, each closing in 0.01-0.02s. Same board, same prompts, both models in play — the model-name distribution in the log backs that up (the one agent.log carries all three of qwen36-27b, gemma, and gemma-4-12b).
But here's the part most likely to mislead, so I'll state it flatly: switching to 27B is not "drop it in and everything's fixed."
The reality check: both brains went 2-for-3 — the difference is clean wins
On June 22, my default yui agent (running gpt-5.5) took the same kanban dispatch test and ran it once against the Gemma-era Hina and once against the Qwen-26B Hina. Verbatim results below (screenshots at the end).
Gemma-era Hina (the operator's own note: "not great, but a little better") — 2 of 3 passed, but all three hit a protocol violation on the first pass and only got through on retry:
- ✅
t_e5d03aafkanban workload summary card: 1st pass protocol violation → 2nd pass done - ✅
t_40650250research handoff checklist: 1st pass protocol violation → 2nd pass done (producedresearch_handoff_checklist.md) - ⛔
t_4d52ea69post-mortem of a failed task: 1st and 2nd pass both protocol violation → blocked
Qwen-26B Hina (operator note: "2 pass / 1 fail") — 2 of 3 passed, and the two wins were clean, no protocol violation:
- ✅
t_c7fd541aworkload summary: done, ~5 min,kanban_completesucceeded, no protocol violation - ✅
t_5466770dincident write-up from a given cause: done, ~4-5 min — operator note: "this one matters: incident-style used to choke Gemma, and Qwen got it this time" — no invented causes, no off-the-rails reasoning - ⛔
t_cc59d407short complete/block checklist: 1st pass 6 min protocol violation, 2nd pass 1 min protocol violation → blocked
Read those two side by side and the real difference isn't the score (both 2-of-3) — it's how clean the wins are:
- Qwen's two wins were one pass, zero violations; Gemma's two only scraped through on retry.
- Qwen held the incident-style task that used to choke Gemma.
And Qwen's one miss — that short checklist (t_cc59d407) — the operator noted that the card passed once the prompt was updated (⚠️ this rests on the operator's note alone; that task's own log doesn't record a post-prompt-fix pass, so take it as an operator account, not log evidence). So the one surviving failure probably isn't "Qwen's dumb too," it's a badly written prompt on that card.
Which lands right on the thesis of this whole series, and it's a clean ending, not a black mark: the problem is usually the harness (the car), not the engine. A steadier brain just lowers the bar for staying disciplined; what actually holds it together is the dispatch method — "short cards, pull the source material out first, force complete/block at the end."
First-hand evidence: the checklist Hina wrote herself
That side-by-side was a test someone else (my default agent) ran. But this post's single hardest piece of evidence is a dispatch checklist Hina wrote to disk herself — first-hand, on-disk, in her own words. The file is hina_new_model_kanban_checklist.md in the t_cc59d407 workspace (author tagged "雛羽 / Hina," 2026-06-21):
Known history — In the Gemma 12B era, protocol violations were common: it would output text and then not call kanban_complete / kanban_block.
Improvement strategy — Use a combination of short cards, pulling source material out first, and forcing complete/block at the end of the card.
That upgrades "finishes the body, drops the close-out" from my [memory] impression to "there's a first-hand document that says so in black and white" — and it lines up with the two [live] malformed kanban_complete errors above: the "known history" Hina wrote down isn't a complaint, it's something the log actually recorded. The improvement strategy also neatly completes the previous section's point: a 27B alone isn't enough — you also have to change the dispatch method so the agent stays on track. The same file also notes the new brain as "Qwen ~26B, ~36 tok/s" — a different approximation of the same Qwen3.6 I call "27B / 30-40 tok/s" elsewhere; pick one and label it, don't fake precision on the number.
⚠️ Confidence, stated plainly: this checklist describes a known history plus a test plan — it's still a case study, not a quantified failure rate. But it's the strongest single quotable piece of evidence here: first-hand, on-disk, written by the agent in question.
The bottom line: throughput isn't usefulness
This post in one line:
"Return a nice paragraph" and "stick to a workflow across a long session" are two different abilities. The small model loses on the second one. tok/s measures the first — how fast it gets the words out — but it can't measure the second: whether, after finishing the content, it remembers to go back and flip the card, update the state, and not drop the one last step nobody is there to remind it about.
Agentic discipline isn't about being smart enough. It's about being steady enough to hold a boring but necessary close-out move. And the nastiest part: when it fails, it doesn't throw an error — it just quietly walks away, leaving a card stuck in-progress.
So I traded 100 tok/s for 30. Not because slow is better, but because I was measuring the wrong thing.
Side by side: the same kanban test on both brains
These two are the raw results my default agent (yui) reported back over Telegram after running the two rounds — the verbatim bullets above are transcribed from these shots. First Gemma-era, then Qwen-26B. The operator's notes are in Chinese; the English is in the bullets above.


Full disclosure
This isn't a benchmark. Here are all the limits laid out:
- Not a controlled paired eval — no clean success / failure rate.
- The visible failures are the tip of the iceberg: the log has a few malformed close-out calls (the two
kanban_complete returned errorlines are real), but the bulk of the failure mode — calls that were never started — leaves nothing in the log, so you can't back out "Gemma failed X times" from a success count. - The numbers are frozen at a snapshot: the model-name distribution and kanban tool counts are from the "as of 06-22 02:50, 4994 lines" snapshot; the source log kept growing afterward (qwen36-27b is up to 888), so don't report the old numbers as "current."
- The 90-100 / 30-40 speeds are memory numbers, not a fresh same-hardware paired re-run.
- "Passed after the prompt fix" is the operator's note, not log evidence.
- The side-by-side above is small-n with retry noise — read it as a case study.
What I can hand you with a clear conscience is exactly this: two days of lived experience, the [live] log fragments I could recover (including the two real malformed kanban_complete calls), one on-disk checklist Hina wrote herself, and one set of comparison screenshots. Read it as a story, not a paper.
Also in this series:
- (previous) Han Sheng retires, the prodigy of Tianshui arrives: an NT$11k modded card hosts a 27B agent (how this 27B brain got here)
- (next · hard-core) Pushing context to 256K and crashing: the VRAM-vs-context math (maps to the 503 Loading model above)
Prequel:
- GTX 970 series: the original musing about E2B being too small to carry an agent
FAQ
- Gemma 12B is three times faster than Qwen 27B — why drop it?
- Because this brain runs as an agent on a kanban board, not as a chatbot. Gemma 12B finishes the body of a task and then stops — it never calls kanban_complete to mark the card done. What it drops is the bookkeeping at the end of the procedure. The slower Qwen 27B, when it succeeds, succeeds cleanly: one pass, no protocol violation. tok/s measures how fast it returns a reply, not whether it can hold a procedure across a long session — and those are two different abilities.
- So switching to Qwen 27B fixed everything?
- No — don't read it that way. On the same kanban test, both brains went 2 for 3. The real difference is in the quality of the wins: Qwen's two successes were clean one-pass runs with no violations, while Gemma's two only passed on retry after a first-pass protocol violation. Qwen also held an incident-style task that used to choke Gemma. And Qwen's one failure — a short checklist card — went through fine once I fixed the prompt, so even that miss was a prompt problem, not a dumb model.
- Is this a benchmark? Is there a clean failure rate?
- No, it's a case study. There's no controlled paired eval and no clean success/failure rate. The logs from Gemma's worst stretch got rotated out, and the fragments I can still pull actually show Gemma looking mostly fine — which is exactly the point: a model that forgets to call a tool leaves no error line, so omissions are invisible and the success counts in your logs lie to you. What I'm offering is two days of lived experience plus the on-disk artifacts I could recover.