AI Agent Life, from Zero · part 14
[Agent 101 #14] One spec, three assistants, three Tetris games: a Hermes Kanban dispatch test
❯ cat --toc
- The plain version: you've got a fleet — let them all do the same thing once
- How I sent it out: one line, three cards, each in its own room
- What each one turned in
- default / GPT-5.5 — a clean baseline
- hina / Qwen3.6-27B (on the modded 2080 Ti) — the surprise
- hikari / DeepSeek V4 Flash — it tested itself in a browser
- The three side by side
- Honestly: is this "one-shot"? Two ways to look at it
- Why this little experiment was worth it
- Go play with it
TL;DR
After raising a fleet of assistants (Part 8) and being able to watch them work from my phone (Part 13), I got curious and ran a small experiment: the same "make a Tetris game" spec — one line, no details — one card per assistant, each writing its own version in a single shot. I touched zero lines of game code and only handled publishing. Then came a surprise: from that one line, the Hermes harness plus a local model I tuned myself, on a six-year-old card (a modded 2080 Ti), filled in things I never asked for — a ghost piece and wall-kick — in one shot. Not a "win" (the few seconds are within the noise, and I didn't compare quality), but a stack that pulls this off is interesting on its own. Play all three here.
The plain version: you've got a fleet — let them all do the same thing once
By now Hermes is up and running, split into several sibs (multiple assistants from one Hermes setup, covered in Part 8) — each with its own brain, doing its own thing. Part 13 then added a way to watch them from your phone.
After a while, a slightly mischievous thought hit me:
What if I hand the same task to all three at once and let each do its own version — what comes out?
So here we are. And I deliberately got lazy with the spec — just one line: "make a playable web Tetris in a single HTML file." Scoring, ghost piece, wall-kick? Not a word. One line, three assistants with completely different brains, and I waited to see what each would fill in on its own.

The result is already live — three tabs, each labeled with the model that made it and how long it took:
👉 web-tetris-showcase.vercel.app (source on GitHub)
How I sent it out: one line, three cards, each in its own room
This is the standard way to dispatch work on the Hermes board, and the flow is simple:
- Write that one line as a card and assign it to a sib; make three copies, one per sib.
- Each card gets its own separate folder (it's a git worktree under the hood — all you need to know is "all three write in their own space and never clobber each other's files").
- Hit dispatch, then walk away. When they finish, each one reports back to the board, and I check in whenever I get to it.
- I also set each card to stop on its first failure (no retries), so no card can get stuck retrying forever and burn all my time and money.
The three sibs this time, each with a different brain:
- default = GPT-5.5: the strong cloud model, my baseline.
- hina = Qwen3.6-27B: an abliterated build I set up and tuned the deployment for myself, running on that modded 2080 Ti 22GB (the story of that card is here).
- hikari = DeepSeek V4 Flash: an inference brain running locally on a DGX Spark via the ds4 engine.
One detail here is worth pausing on, and Hermes does it on purpose: a sib can't reach your GitHub credentials inside its little sandbox — Hermes actively strips those keys out of its environment. So a sib only writes code; pushing to GitHub and deploying to Vercel is done by me, the main process that holds the keys. The key never enters the sandbox. That split — the sib does the work, the parent process publishes — is deliberate. It's not me being paranoid; GitHub keys just shouldn't end up in the hands of an agent running loose on its own.
What each one turned in
default / GPT-5.5 — a clean baseline
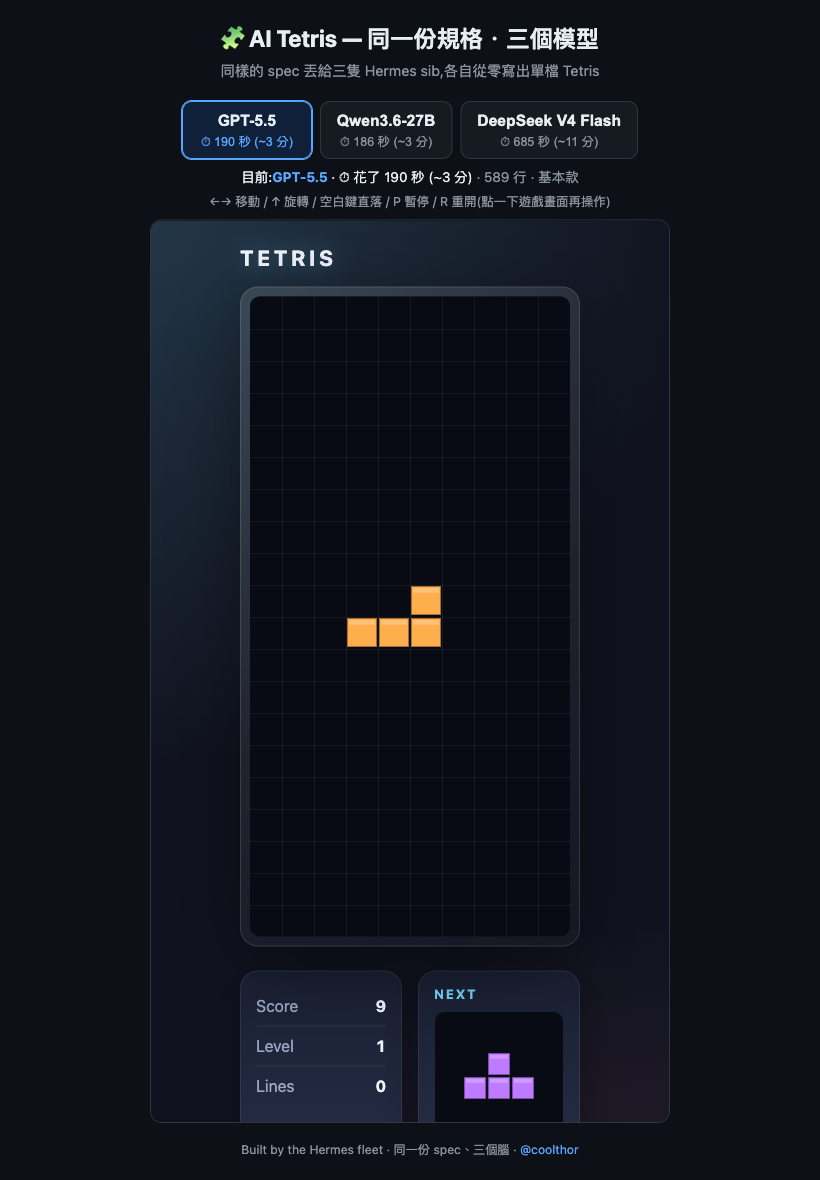
About 190 seconds, 589 lines. Everything you'd expect: drops, rotation, scoring, a next-piece preview. Solid, no frills — exactly what a baseline should be.
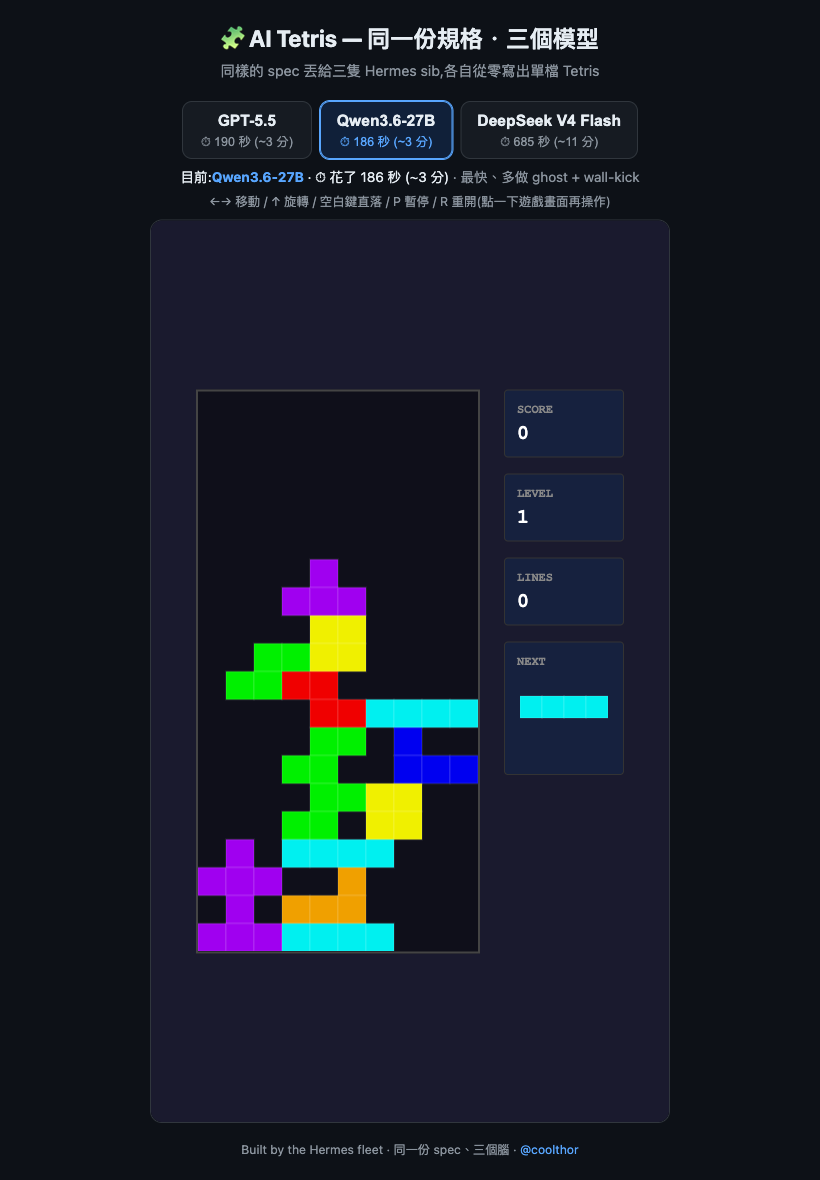
hina / Qwen3.6-27B (on the modded 2080 Ti) — the surprise

About 186 seconds. Remember, my one line said nothing about details — yet it added a ghost piece (the translucent landing preview) and wall-kick (auto-nudging off a wall when you rotate into it) on its own. Those are the little game-feel touches that make modern Tetris feel right, and nobody asked for them.
Honestly, what surprised me wasn't the speed — 186 vs 190 seconds is well within the noise, so it's nowhere near a "win." What surprised me was the combination: a one-line spec, run through the Hermes harness, on a local model I tuned at home on a six-year-old card, filling in those un-asked-for details in a single shot. The model alone doesn't get the credit — it's the whole stack (the harness framing the task plus a model tuned for local use) performing beyond what I expected.
hikari / DeepSeek V4 Flash — it tested itself in a browser
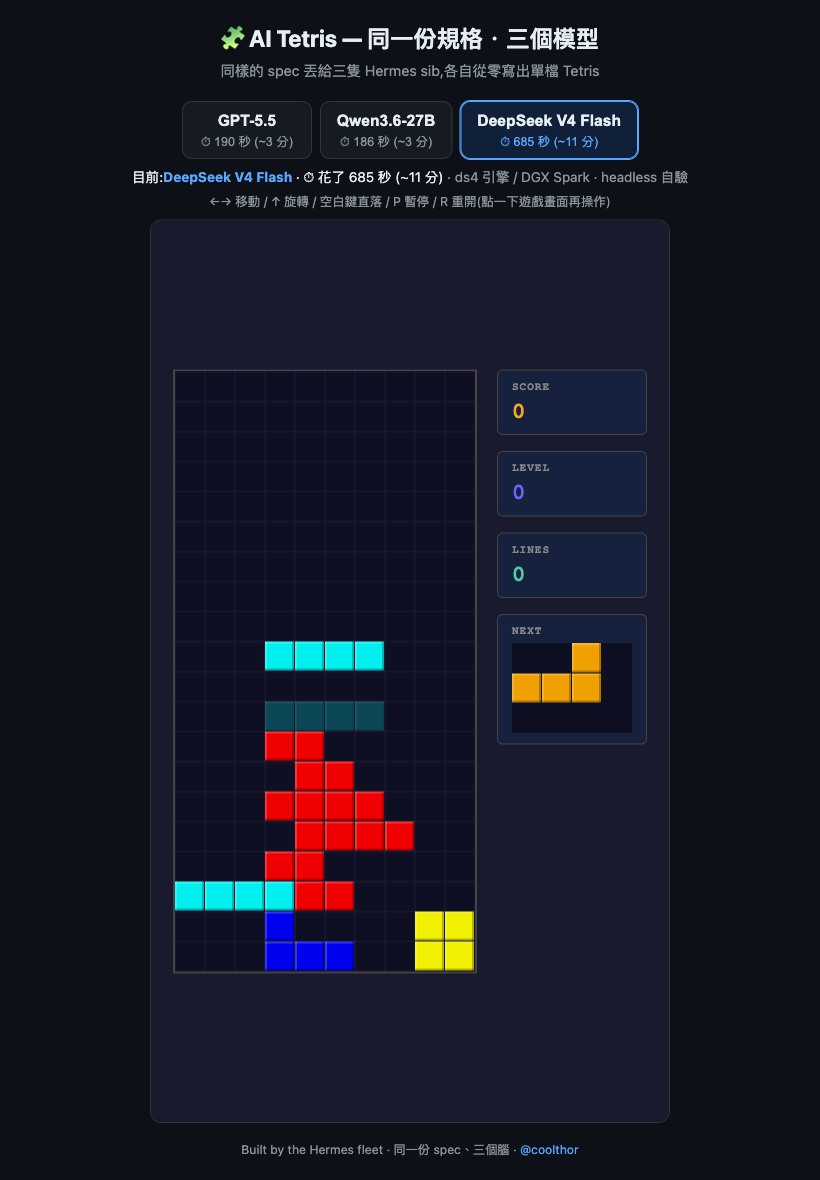
About 685 seconds, the slowest. But in that one run it opened a headless browser (headless Chrome) and actually played the game to test it — which leads straight into the next bit: "one-shot" really has two levels.
The three side by side
| Assistant | Brain | Time | Notable |
|---|---|---|---|
| default | GPT-5.5 (cloud) | ~190s | Clean baseline, 589 lines |
| hina | Qwen3.6-27B (local / modded 2080 Ti) | ~186s | Added ghost + wall-kick on its own |
| hikari | DeepSeek V4 Flash (DGX Spark) | ~685s | Opened a headless browser to test itself |
Honestly: is this "one-shot"? Two ways to look at it
"One-shot" is easy to oversell, so let me pull it apart:
- At the dispatch level, yes: one card per sib, one run, no retries (it stops on the first failure), I never went back to ask for changes, and I changed zero lines of game code — I only moved the files into the showcase.
- Inside the sib, it isn't pure one-shot: each card is really an agent running its own loop — writing, checking, fixing. The hikari one even opened a browser to play and test the game. So it's not a single model completion that lives or dies on one pass.
Saying both keeps the story from sounding more magical than it was.
Why this little experiment was worth it
The point wasn't "a small local model beats the cloud" — it doesn't, as I said. What actually made it worthwhile were two things:
- The dispatch really is fire-and-forget. One line, three different brains, three separate folders — send it off, go do other things, come back to three results. My attention went entirely into writing that one line and publishing at the end; zero babysitting in between. That's the point of Kanban dispatch: whether you're running one or ten, the attention it costs you is about the same.
- This result came from the harness plus a tuned model — not the model alone. I gave one line and no details; what filled the gaps was the Hermes harness framing the task plus a model tuned for local use. Together, on a six-year-old card, they filled in things I never asked for in one shot. It won't happen every time, but a stack that occasionally surprises you like this moves the needle on what a box at home can actually do.
Go play with it
All three versions are here; switch tabs, and each label shows which model made it and how long it took:
👉 web-tetris-showcase.vercel.app
Source (three single files plus one showcase page) is at github.com/coolthor/ai-tetris-showcase.
This post is the "now that you have a fleet, put it to work" follow-on. Earlier parts:
FAQ
- How do you actually hand 'one spec to three assistants'?
- Through Hermes's built-in Kanban board. You write the task as a card and assign it to one assistant; make three copies, one per assistant. Each card gets its own folder (a git worktree, technically) so all three work side by side without overwriting each other's files. You send them off and go do something else; they report back to the board when they're done, and you check it later.
- Does this count as 'one-shot'?
- Depends which level you mean. At the dispatch level, yes: one card per assistant, one run, nobody went back to ask for fixes, and I changed zero lines of game code. But each card is really an agent running its own loop — it writes, tests, and fixes its own code — and the DeepSeek V4 Flash one even opened a headless browser to play and test the game. So it isn't 'one-shot' in the pure single-model-completion sense.
- Did the local model actually 'beat' the cloud model?
- No — don't frame it that way. 186 vs 190 seconds is within the noise, and I never compared the three games for quality. The honest version: I gave one line (just 'make a Tetris game,' no details), and the Hermes harness plus a model tuned for local use filled in things I never asked for (ghost piece, wall-kick) in one shot. That's an unexpected surprise — credit to the whole stack, not one model beating another.