從 0 開始的 AI Agent 生活 · part 16
[Agent 進階 #16] 同一份規格,丟給三隻分身各寫一個俄羅斯方塊:Hermes 看板派工實測
❯ cat --toc
TL;DR
白話導讀:養了一群分身,乾脆讓它們同場比一次
前面幾篇,你已經把 Hermes 養起來、還分了好幾隻分身(同一套 Hermes 分出來的多隻助理,Part 10 講過),各有各的腦、各忙各的;Part 15 又讓你出門也能在手機上看它們在幹嘛。
養著養著,我就冒出一個有點皮的念頭:
如果我把同一件事同時丟給它們三隻,各做一份,會長什麼樣?
於是有了這篇。而且我故意「偷懶」——規格只給一句話:「做一個能玩的網頁俄羅斯方塊,放在單一個 HTML 檔裡」。計分、ghost、wall-kick 這些細節?一個字都沒提。就這麼一句話,丟給三隻腦完全不同的分身,看它們各自會自己補出什麼。

成品我已經發出來了,三個分頁、每個都標了是哪顆模型做的、花了多久:
👉 web-tetris-showcase.vercel.app(原始碼丟在 GitHub)
怎麼丟的:一句話規格,三張卡,各自關在自己的房間
這就是 Hermes 看板派工最典型的用法,流程其實很單純:
- 把那句話寫成一張卡,指定給一隻分身;同一張卡複製三份,一隻發一張。
- 每張卡會自己拿到一個獨立的資料夾(技術名詞叫 git worktree,你只要知道「三隻各寫各的、不會互相蓋到檔案」就夠了)。
- 按下去派工,然後就放著。它們做完,各自把結果回報到板上;我有空再回來看。
- 我還設了「失敗一次就停、不重試」,免得某隻卡死在那邊無限重來,把時間跟錢都燒光。
這次出場的三隻,腦各不相同:
- 小唯(預設)= GPT-5.5:雲端的強模型,當基準線。
- 雛羽(hina)= Qwen3.6-27B:我自己在家架起來、調過部署的 abliterated 版本,跑在那張改裝 2080Ti 22G 上(這張卡的故事在這篇)。
- 光羽(hikari)= DeepSeek V4 Flash:透過 ds4 引擎、跑在自己的 DGX Spark 上的地端推理腦。
這裡有個小細節值得停一下,而且是 Hermes 故意這樣設計的:分身在它自己的小沙箱裡,是碰不到 GitHub 金鑰的——Hermes 會主動把這類密鑰從它的環境裡拔掉。所以分身只負責寫程式,最後上傳 GitHub、部署到 Vercel,是由我這個握著金鑰的主程序動手。金鑰從頭到尾不進沙箱。換句話說「動手做的」跟「負責發布的」是兩個人——這不是龜毛,是金鑰本來就不該交到一隻自動亂跑的 agent 手上。
三隻各交了什麼
小唯 / GPT-5.5 — 乾乾淨淨的基本款
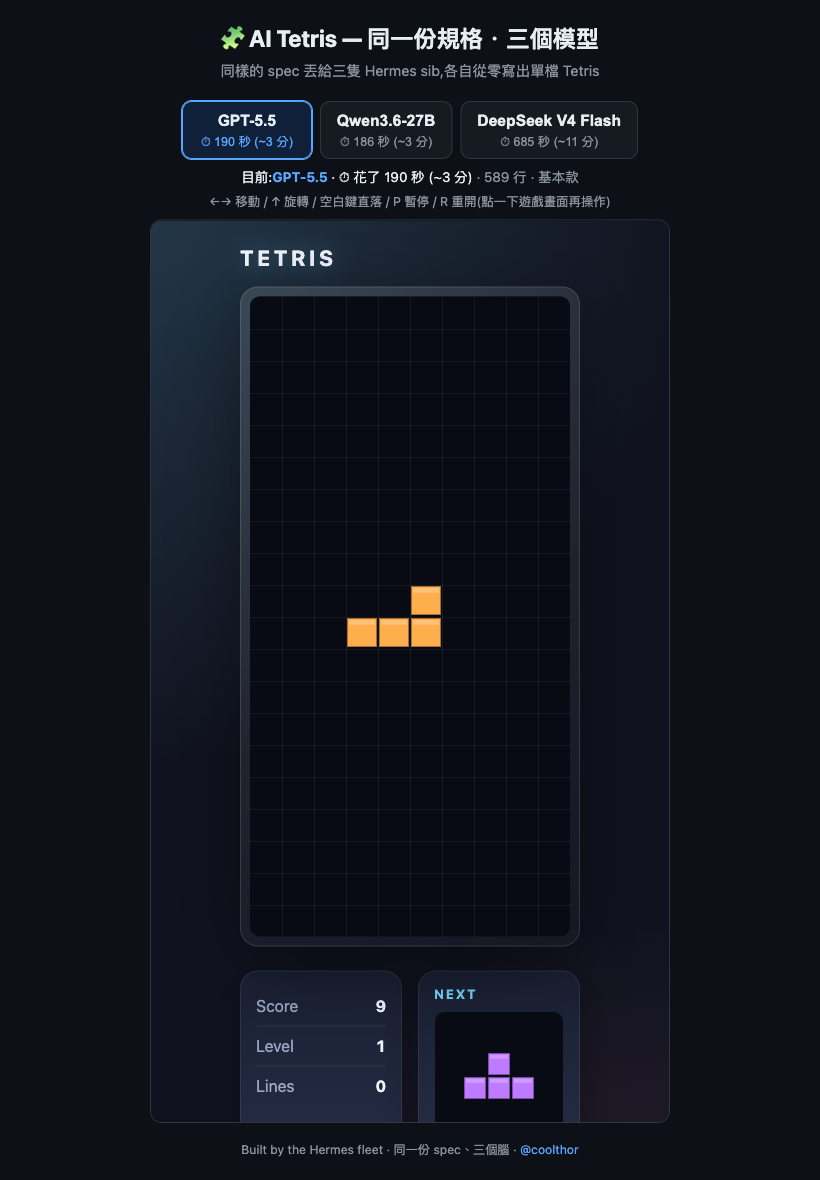
大概 190 秒、589 行。該有的都有:落子、旋轉、計分、下一顆預覽。穩,沒花樣,當基準線剛剛好。
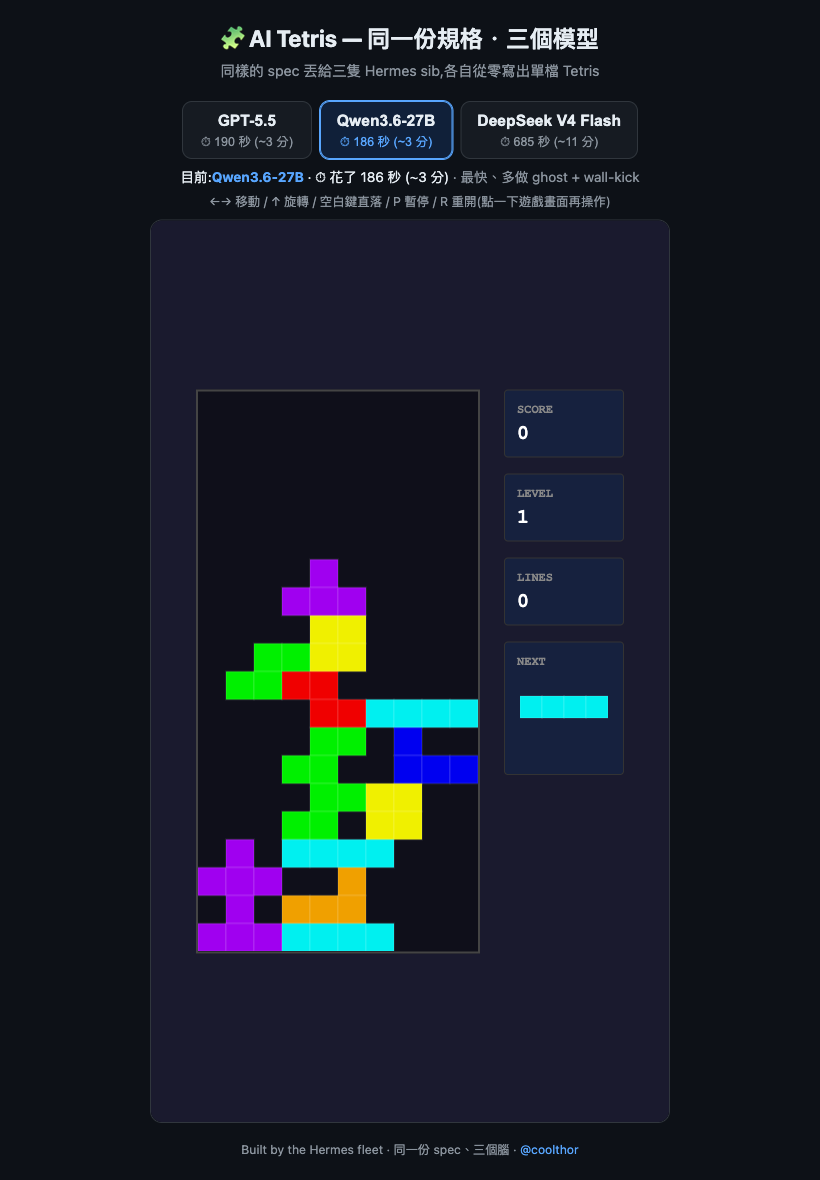
雛羽 / Qwen3.6-27B(跑在改裝 2080Ti 上)— 意外的驚喜

大概 186 秒。別忘了我那句話什麼細節都沒講——結果它自己加了 ghost piece(半透明的落點預覽)跟 wall-kick(貼著牆轉會自動推開)。這兩個是讓現代俄羅斯方塊「手感」對的小地方,沒人叫它做。
老實說,讓我意外的不是它快——186 對 190 秒,這點差距根本在誤差裡,談不上「贏」。讓我意外的是這個「組合」:一句話的規格 + Hermes 這套外框幫它把任務框好 + 一顆我自己在家調、跑在六年老卡上的小模型,合起來居然能一次就把這些沒被要求的細節補出來。功勞不在模型一個人身上,是整套東西跑出了超過我預期的成績。
光羽 / DeepSeek V4 Flash — 自己開瀏覽器驗過
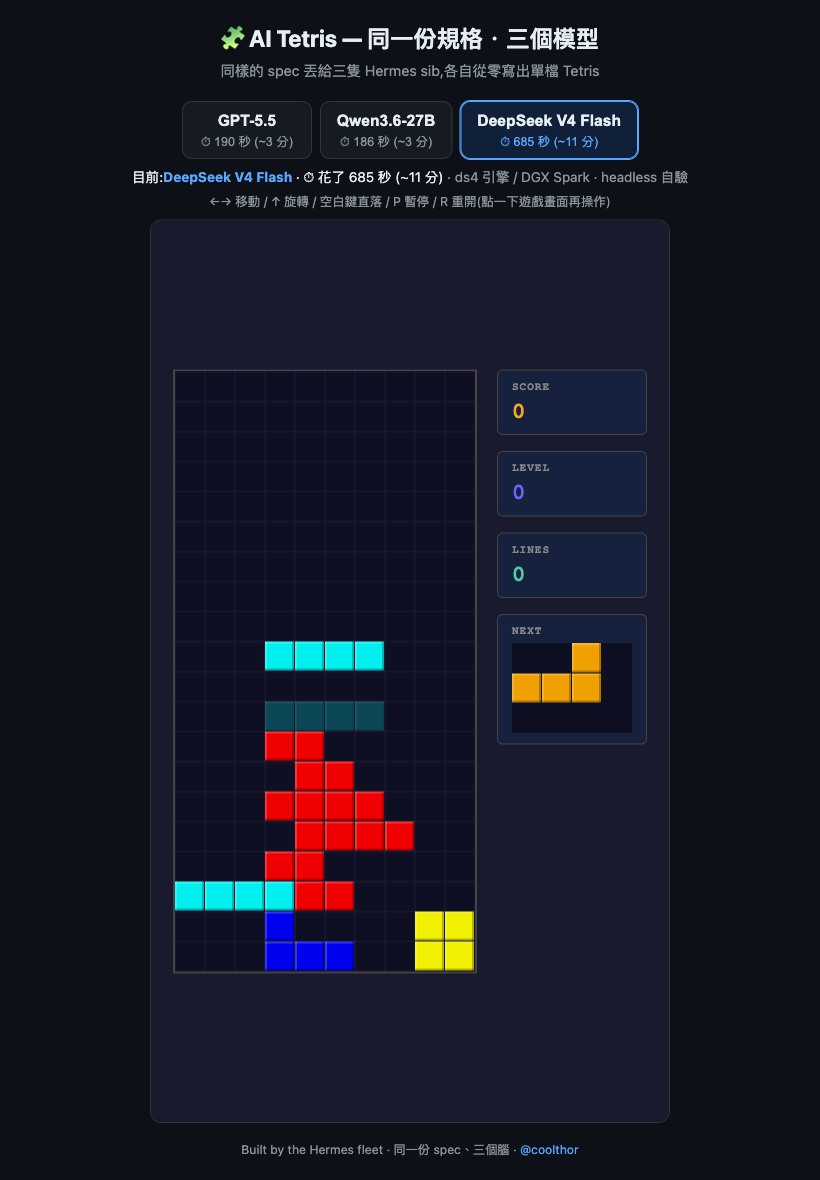
大概 685 秒,最久的一隻。但它在那一輪裡自己開了一個沒畫面的瀏覽器(headless Chrome),把遊戲跑起來測過——這正好帶到下一段:所謂「一次到位」其實要分兩層看。
三隻擺一起看
| 分身 | 腦 | 花多久 | 特別之處 |
|---|---|---|---|
| 小唯 default | GPT-5.5(雲端) | ~190 秒 | 乾淨基本款,589 行 |
| 雛羽 hina | Qwen3.6-27B(地端 / 改裝 2080Ti) | ~186 秒 | 自己多補了 ghost + wall-kick |
| 光羽 hikari | DeepSeek V4 Flash(DGX Spark) | ~685 秒 | 自己開了沒畫面的瀏覽器驗過 |
老實說,這算「一次到位」嗎?分兩層
「一次到位(one-shot)」這個詞很容易講過頭,我拆開講:
- 派工這層,算一次到位:一隻一張卡、只跑一次、失敗就停不重試、沒有人回頭叫它改,我也一行遊戲碼沒動,只是把檔案搬進 showcase。
- 但分身內部不是純一次:每張卡其實是一個 agent 自己跑一輪——會自己寫、自己看、自己修。光羽那隻甚至自己開了瀏覽器把遊戲跑起來測。所以它不是「模型吐一次就定生死」那種純粹的單次輸出。
兩層都講清楚,才不會把這件事說得比實際更神。
為什麼這個小實驗值得玩
它不是要證明「地端小模型贏雲端」——沒有,前面講過了。真正讓我覺得有價值的是兩件事:
- 派工這套真的能「丟著不管」。 一句話規格、三顆不一樣的腦、三個各自獨立的資料夾,丟出去我就去忙別的,回來收三份成果。我全程的注意力只花在「寫那句規格」跟「最後發布」,中間完全沒在盯。這就是看板派工想要的:對人來說,顧多少隻都差不多累。
- 這成績是「外框 + 特化模型」合力跑出來的,不是模型單打。 我只丟一句話、細節都沒給,是 Hermes 的外框幫忙把任務框好,加上一顆為地端特化調過的小模型,兩邊湊起來,才在一張六年老卡上一次補出這些。它不會每次都這樣,但這種組合「偶爾給你超出預期的東西」,就足以讓「家裡那台到底能幹嘛」的答案,再往前挪一點。
自己玩玩看
三個版本都在這,點分頁切換,標籤上有各自是哪顆模型、花了多久:
👉 web-tetris-showcase.vercel.app
原始碼(三個單檔 + 一頁 showcase)在 github.com/coolthor/ai-tetris-showcase。
這篇是「養了一群分身之後,拿它們來做點事」的延伸。前置篇:
常見問題
- 「一份規格丟給三隻分身」到底怎麼丟?
- 用 Hermes 內建的看板(Kanban)。你把要做的事寫成一張卡片、指定給某一隻分身;同樣的卡複製三張,一隻一張。每張卡會自己拿到一個獨立的資料夾(技術上叫 git worktree),三隻各寫各的、檔案不會打架。丟出去之後你就去忙別的,它們做完會回報到板上,你再回來看。
- 這算「一次到位(one-shot)」嗎?
- 看你問哪一層。派工這層算:一隻一張卡、只跑一次、沒有人回頭叫它改、我也一行遊戲碼沒動。但每張卡其實是一個 agent 自己跑一輪——它會自己寫、自己看、自己修,其中 DeepSeek V4 Flash 那隻還自己開了一個沒畫面的瀏覽器把遊戲跑起來測。所以它不是「模型吐一次就算數」那種純 one-shot。
- 地端小模型真的「贏」雲端模型了嗎?
- 沒有,別這樣講。186 秒對 190 秒落在誤差範圍內,而且我根本沒比三個遊戲的品質。正確的說法是:我只丟了一句話(就「做個俄羅斯方塊」、沒講細節),是 Hermes 的外框加上一顆為地端特化調過的小模型,兩邊合起來,才一次就把沒人要求的細節(ghost、wall-kick)補了出來。這是意料外的驚喜,功勞在整套組合,不是哪顆模型打趴了誰。