DeepSeek-V4-Flash on DGX Spark · part 4
[本地 LLM] 養了一個月,我的 284B agent 悄悄不再快取——ds4 的 evict 風暴,跟每輪重付的 prefill
❯ cat --toc
- 白話版:記性超好的助理,一個月後開始每次都從第一頁重讀
- 前言
- Part 2 誇的 hot path,一個月後悄悄爛掉:不是 crash,是「該命中卻沒命中」
- 兩條 log 指紋:預算滿的 evict 風暴,加上 tool-call 那輪沒存進度
- Root cause:tool-call 那輪不存 checkpoint,而 agent 一天到晚以工具收尾
- 修法:兩個重啟窗各約 2.5 分鐘——128G→256G 加換 #489 binary
- 驗收:第二個 tool 輪的 common= 從 1.9% 變 81%
- 誠實天花板:吐字是頻寬牆調不動,prefill 才是唯一槓桿
- 收穫
- 最花時間的地方
- 可搬走的診斷方法
- 通用原則
- 結論 checklist
TL;DR
Part 2 誇的那條「快取命中就順」的 hot path,一個月重度 agent 用下來悄悄失效——不是 crash,是明明該命中卻沒命中,連續對話、沒重啟、沒換話題,每輪還是幾十秒乾等。ds4 server log 直接寫出兩個兇手:disk-cache-full hits=0(預算填滿,踢掉的還是沒人用過的 prefix = 快取在 thrash)+ common=268 / prompt=14209(一段 14K 的對話只認得 1.9%,剩下整段重 prefill)。難查的那半是 root cause:以呼叫工具結束的那輪不存 checkpoint,而 agent 一天到晚以呼叫工具結束。修法=--kv-disk-space-mb 128G→256G + 換上上游 PR #489 的 binary。A/B 驗收很直接:第二個 tool 輪的 common= 從 1.9% 變 81%、evict 風暴歸零、吐字維持 ~15.7 tok/s 沒變慢。誠實天花板:吐字本身一個字都快不了(頻寬牆),真正省的全在「不用重讀」。
白話版:記性超好的助理,一個月後開始每次都從第一頁重讀
想像你雇了一個記性超好的助理。你們每天用同一份長長的工作紀錄溝通,理想的樣子是:你回來繼續講,他記得你們剛講到哪、接著就回你、很快。這就是我在 Part 2 誇過的東西——ds4 這套引擎會把算過的對話開頭存到硬碟,下次同一段開頭直接撈回來用,不用重想。
養了一個月,他變了。每次你一開口,他都像第一次看到這份紀錄,非得從第一頁重讀整本才肯回你。一萬四千字的對話,他只認得開頭兩百多字,剩下全部重讀——於是又變慢,每講一句話,你都要在他開口前乾等幾十秒。
拆開來看,是兩個兇手。一,存放「算過內容」的硬碟空間滿了,他為了騰位子,把還沒用到的先丟掉——等於白存。二(這個更陰):只要那一輪他在動手查東西、跑指令(呼叫工具),他就忘了把進度存檔;而 agent 這種助理一天到晚都在動手,結果進度幾乎沒存到。
修法不難:硬碟空間從 128G 開到 256G,再換上一版把「動手那輪也記得存檔」補好的引擎。修完,同一段對話第二輪就認得八成開頭,不用重讀。收尾要誠實:他吐字的速度本身一個字都快不了,那卡在硬體的物理天花板,調什麼都動不了。真正省下來的時間,全在「不用重讀」這一件事上。
前言
一個效能問題最難查的,不是它爆給你看,是它安靜地爛掉。ds4 沒 crash、沒噴 error,只是一個月後每輪都慢——慢到我以為 disk cache 被誰關掉了。
這是 DeepSeek-V4-Flash on DGX Spark 系列 Part 4。Part 1 讓這顆 284B 跑上單顆 128GB 的 GB10;Part 2 靠 ds4 的 disk-KV cache 把體感做成雙峰——命中就 5–15 秒、沒命中才 60–160 秒,單日 48% 的回覆落在快的那條。這篇是一個月後的續集:那條被我誇過的 hot path,悄悄爛掉了,而且爛得沒有一聲警告。
Part 2 誇的 hot path,一個月後悄悄爛掉:不是 crash,是「該命中卻沒命中」
先講症狀,因為它騙了我一陣子。
連續對話、沒重啟、沒換話題——照 Part 2 的邏輯,這種情況該一路命中、一路 5–15 秒回完。實際是:每一輪還是幾十秒乾等,像有人把 disk cache 整個關掉,退回 Part 2 之前那種冷啟等待。沒有 crash、沒有 error log、沒有任何東西跳出來說「我壞了」。就是慢。
為什麼一失效就這麼痛?因為在 GB10 上,這顆 81GB 的 Q2 model 重 prefill 大約 14K token,等於第一個字冒出來之前 60–90 秒純等。快取無聲失效不是「稍微變慢」的緩降,是直接掉懸崖——命中的 5 秒,跟沒命中的 90 秒,中間沒有中間值。
兩條 log 指紋:預算滿的 evict 風暴,加上 tool-call 那輪沒存進度
好消息是不用猜。ds4 server log 把兩個兇手直接寫出來了。
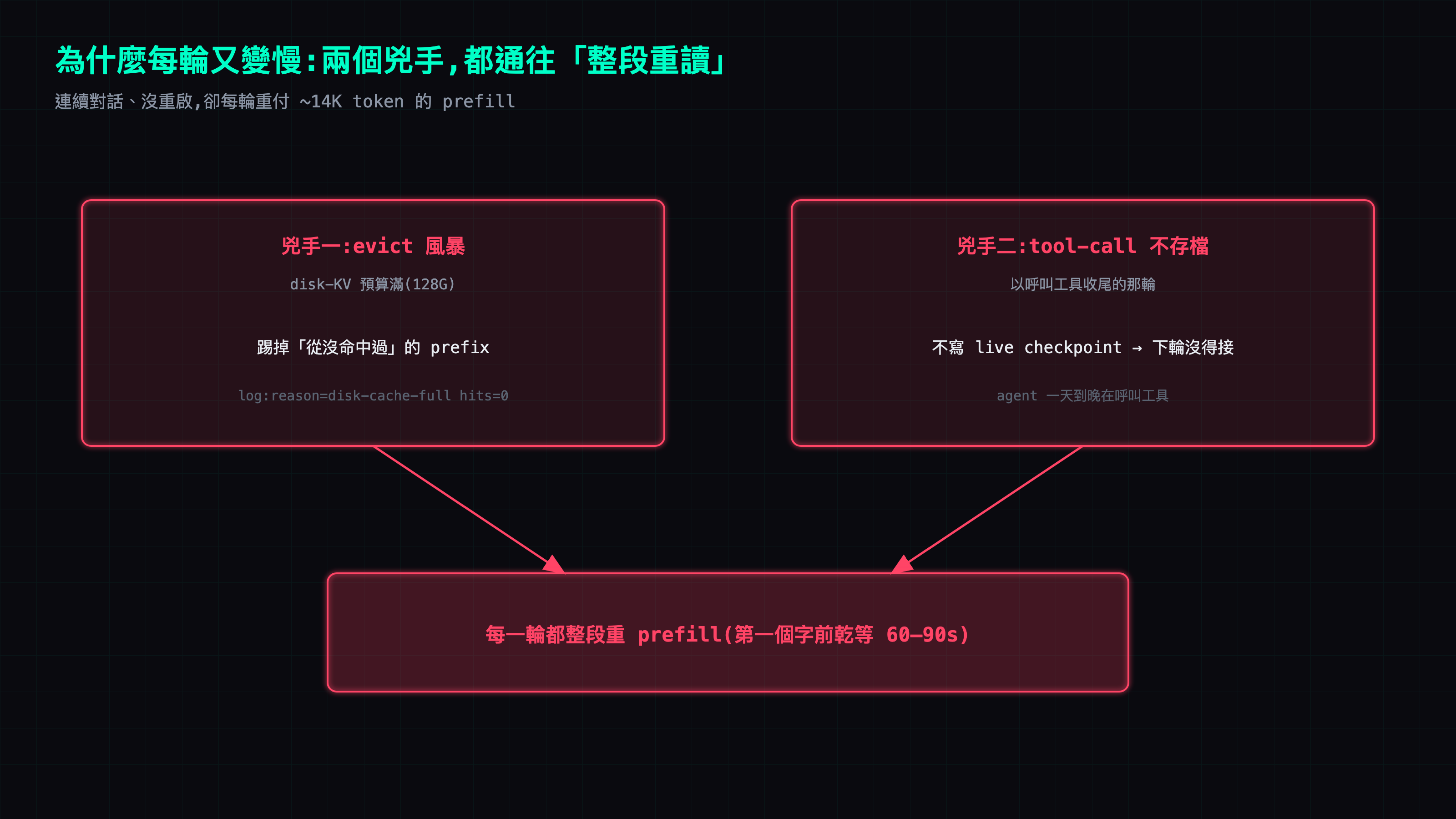
指紋一:evict 風暴。
kv cache evicted reason=disk-cache-full hits=0
disk-cache-full 是 disk-KV 預算滿了(Part 2 我設 128G),ds4 為了挪空間,踢掉一個舊 checkpoint。關鍵在 hits=0——它踢掉的那個 prefix 從沒被命中過。這不是「太冷所以淘汰」,是快取在 thrash:寫進去→下一輪還沒來得及命中→就被下一次寫入擠掉了。一個月的重度用把預算填滿之後,每一次新寫入都在擠掉一個其實還有用的 prefix。
指紋二:寫了卻幾乎沒命中。
live kv cache miss ... prompt=14209 common=268 reason=token-mismatch
common= 是這個 prompt 的開頭有幾個 token 對得上硬碟上的 checkpoint。268 / 14209 = 1.9% 重用。對話幾乎沒變,它卻只認得開頭幾百個 token,剩下 ~14K 整段重 prefill。reason=token-mismatch 說得更白:硬碟上那個 checkpoint,幾乎從一開頭就跟現在這段 live 對話分岔了。
到這裡 evict 是簡單那半——預算滿,調高就好。難查的是為什麼「幾乎沒變的對話」會一開頭就跟 checkpoint 對不上。
Root cause:tool-call 那輪不存 checkpoint,而 agent 一天到晚以工具收尾
ds4 每輪結束時會存一個「live checkpoint」,把這輪算過的前綴記下來,讓下一輪能接上去。但有個洞:以呼叫工具結束的那一輪,不會存那個 checkpoint。
問題就在這——agent 幾乎每輪都以呼叫工具收尾。讀檔、跑指令、打 API,一輪接一輪都是工具。我在 Part 8 那篇拆 log 的文章裡算過:一次真實的 user 回合會帶著 2–13 次 tool round-trip,最多我看到 39 次。這代表你的對話大半活在「沒留 checkpoint 的 tool 輪」裡,下一輪要接的時候,近處根本沒有存檔可接,common= 就一路崩到「上一個非 tool 輪」存下的那點量——也就是那 268。
這也解釋了 Part 2 為什麼單日看起來沒事、一個月重度 tool 用卻把快取餓死:輕用會夾雜夠多「純聊天輪」,每一輪都順手幫前綴保溫;用到後來幾乎每輪都在跑工具,純聊天輪被擠光,前綴就這樣被餓死。
兩個 failure mode 疊在一起才是真正的殺傷力:evict 風暴把好的 prefix 踢掉,checkpoint gap 讓好的 prefix 根本沒寫進去。單獨一個就夠掉命中率,合起來把命中率打到近乎零。
修法在上游。antirez/ds4 的 PR #489(作者 elkaix,標題 "Server: fix agent-loop cache misses…",目前 OPEN 未 merge)裡有個 commit 標題就是 "Remember a visible live checkpoint for chat/Anthropic tool-call turns"——讓 tool-call 那輪也存 checkpoint。方向剛好對上我看到的病。
修法:兩個重啟窗各約 2.5 分鐘——128G→256G 加換 #489 binary
分兩步,兩次重啟,每次大概 2.5 分鐘 downtime。
P1:在正在跑的 binary 上調一個 flag。 --kv-disk-space-mb 從 131072(128G)改成 262144(256G;NVMe 還餘 384G,空間夠)。
./ds4-server --cuda -m ./ds4flash.gguf \
--ctx 262144 --kv-disk-dir ./ds4-kv-cache \
--kv-disk-space-mb 262144 --no-mmap --power 100 ...
這一條就是 evict 風暴的整個修法。有了餘裕,寫進去的 prefix 就能活到被命中,而不是下一次寫入時就被踢掉。
順帶兩個誠實交代:
DS4_CUDA_KEEP_MODEL_PAGES=1在 GB10 上是 no-op,A/B 只有 ±2%。GB10 的統一記憶體本來就把 expert 權重常駐,沒有「會被換出去的 model page」給它 pin——這個開關要 discrete GPU 的機器才有意義。留著無害,但這台硬體上沒作用。- ctx 維持 256K,沒往上拉。384K 是 ds4 "Think Max" 模式的門檻,但 384K 下 KV buffer 會吃到只剩約 10G RAM 餘裕,太緊,沒法再共跑別的東西。256K 是保守的 daily 設定。
P2:換 binary。 換上 PR #489。我在隔離的 worktree 裡編,零警告:
make cuda-spark -j4 CUDA_HOME=/usr/local/cuda-13.2
線上那顆 binary 指到 ~/ds4-pr489/ds4-server,舊的留一行可回滾(ds4-server-main-80ebbc3.bak)。上游現況值得提一句:6/17 之後 antirez 暫停 merge,所以重編 main 沒幫助,只能在隔離 worktree 裡把 #489 編起來。
驗收:第二個 tool 輪的 common= 從 1.9% 變 81%
修完不能憑感覺說「好像快了」。我要一個一眼看得出有沒有修好的測試——壞版跟修好版的數字必須拉得開。
判別點很明確:一次多工具交換裡,「第二輪」的 common=。壞的會崩到幾百;修好的話,大部分前綴都該對得上。

| 訊號 | 修之前 | 修之後 |
|---|---|---|
common= 第二個 tool-call 輪 | 268 / 14209(1.9%) | 379 / 470(81%) |
disk-cache-full hits=0 驅逐 | 連環風暴 | 0 |
| decode 短測 | ~15.7 tok/s | ~15.7 tok/s(沒變慢) |
decode 沒變慢是重點:這修法不會拖到吐字,只是擋住同一段 prefill 一直重算,decode 那條路完全沒碰。
⚠️ 誠實提醒:這張表是拉得開差距的 A/B,它證的是「機制」修好了——tool 輪會存 checkpoint 了、prefix 活得夠久被重用了。還在觀察的是真實流量:我的 agent hikari 跑在這台,它日常的 common= 會不會從幾百爬到接近全前綴,那才是 80 秒掉到幾秒、真正省到時間的地方。機制已經確認;整天跑下來到底省多少,還在記 log。
誠實天花板:吐字是頻寬牆調不動,prefill 才是唯一槓桿
別把這篇讀成「然後就變快了」。
decode 在真實 ~14K context 流量下是 ~13.7 tok/s,而且我確認過:沒有任何 server flag 動得了。這是 81GB Q2 model 在 128GB GB10 上的記憶體頻寬天花板。每個 decode token 都得把 active 權重從統一記憶體 stream 出來,頻寬是固定的,參數擋不了物理。
所以唯一的槓桿是 prefill——就是吐第一個字之前、把整段對話讀進去那幾十秒。decode 你認了,prefill 你可以拒絕重付。這就是為什麼一個「會命中的 disk-KV cache」比任何吐字端的調優都值錢,也是它無聲失效這麼痛的原因:修法沒讓 model 變快,是止住「每一輪都重付同一段 14K token」。
收穫
最花時間的地方
不在修——修其實很快,兩個設定加換 binary。真正花時間的,是我信了一個過期的 Part 2 量測。「48% 回覆 5–15 秒完成」對單日輕用是真的,但隨著工作變 agent、disk 預算被填滿,它悄悄失真,而我一直拿它當現況在用。教訓:快取命中率不是量一次就定的屬性,是隨用量衰減的變數,而且會無聲衰減到你去讀 eviction log 才知道。過期的量測比沒有量測更危險,因為你信它。
可搬走的診斷方法
cache-miss log 裡的 common= 對 prompt=,是「前綴快取到底有沒有在運作」的單一數字。連續對話該 common ≈ 整個 prompt 長;如果五位數的 prompt 只 common 幾百,代表有寫沒命中,就去查為什麼——disk 預算滿、加上有某種輪型沒存 checkpoint,是兩大嫌犯。另一個:eviction 行裡的 hits=0 是快取在 thrash 的指紋——它踢掉的是沒人用過的東西,代表快取太小,不是太冷。這兩個判斷放到任何有 prefix cache 的 serving 引擎上都成立。
通用原則
在卡頻寬的本地 model 上,decode 是你調不動的常數,prefill 是你可以拒絕重付的成本。我花在讓 DSv4 體感變快的每一小時,都在後半句、從不在前半句。重點幾乎全在 disk-KV cache;讓它真的命中,是沒人會事先提醒你的維護工作——它會安靜地衰減,而你只有主動去讀 log 才會發現。
結論 checklist
- 盯 cache-miss log 的
common=vsprompt=。 連續對話近全長 = 健康;幾百對上 14K = 根本沒在命中,去查。 - 看到
disk-cache-full hits=0= 預算太小、快取在 thrash。 調高--kv-disk-space-mb,讓寫進去的 prefix 活得夠久被重用(我這裡 128G → 256G)。 - tool-call 輪一定要存 checkpoint。 ds4 若早於 PR #489,agent 工作會無聲餓死前綴快取——隔離 worktree 編修法、換 binary。
- 別追 decode。 ~14 tok/s 是 GB10 的頻寬牆,參數動不了,力氣全花在 prefill 重用。
- 用一眼看得出差別的測試驗證,別憑感覺。 第二個 tool-call 輪的
common=從幾百變成大部分前綴——那個數字不會像「感覺變快」那樣騙你。
本系列其他篇:Part 1 — 在 128GB 小盒子上跑 284B,然後錯怪了 2-bit · Part 2 — 把 15 tok/s 的 284B 當每天的 agent 大腦 · Part 3 — 權重就是正義:284B 砍到 2-bit 還是強 · Part 8 — 為什麼 30 tok/s 體感比 14 還慢 · 上游修法 PR #489
常見問題
- ds4 的 KV disk cache 用久了會越來越不命中嗎?
- 會,而且是無聲衰減。快取命中率不是量一次就定的屬性——它隨用量掉。disk 預算被填滿後,ds4 為了挪空間會踢掉還有用的 prefix(evict 風暴);再加上以呼叫工具結束的那輪不存 checkpoint,agent 越用,命中率就越掉到近乎零。Part 2 量到的『48% 回覆 5–15 秒』對單日輕用是真的,但撐不過一個月重度 agent 用。要去讀 eviction log 才會發現它悄悄爛掉。
- ds4 的 cache-miss log 裡 common= 是什麼意思?
- common= 是這個 prompt 開頭有幾個 token 對得上硬碟上的 checkpoint,也就是這輪真正命中、不用重算的長度。它對 prompt= 的比值,就是『前綴快取到底有沒有在運作』的單一數字。連續對話理論上 common 該接近整個 prompt 長;如果五位數的 prompt 只 common 幾百(例如 268 / 14209 = 1.9%),代表有寫進去但幾乎沒命中,剩下的十幾 K 整段重 prefill。
- DeepSeek-V4-Flash 在 GB10 上的吐字速度能靠調參數變快嗎?
- 不行。真實 ~14K context 流量下 decode ~13.7 tok/s,而且我確認過沒有任何 server flag 動得了——這是 81GB Q2 model 在 128GB GB10 上的記憶體頻寬天花板。每個 decode token 都得把 active 權重從統一記憶體 stream 出來,頻寬是固定的,調參數也突破不了物理限制。唯一能動的槓桿是 prefill:decode 你認了,重付的 prefill 你可以拒絕。
- ds4 拿來當 agent 一直重 prefill 同一段對話,怎麼修?
- 兩件事一起做。一,把 --kv-disk-space-mb 調高(我從 131072 也就是 128G 拉到 262144 也就是 256G),讓寫進去的 prefix 活得夠久被重用,而不是下次寫進來時就被踢掉。二,如果你的 ds4 早於 PR #489,tool-call 那輪不會存 checkpoint,agent 工作會無聲餓死前綴快取——隔離 worktree 編 #489 換 binary,讓 tool-call 輪也存 checkpoint。
接著讀
- 2026-06-12[地端 LLM] 把 15 tok/s 的 284B 當每天的 agent 大腦:DeepSeek-V4-Flash 怎麼設才舒服
一顆 284B、只有 15 tok/s 的模型,要拿來當每天的 agent 大腦,得先做點準備才用得舒服。server 跟 agent 框架兩邊各一組設定:--no-mmap 冷啟砍到 57 秒、KV disk cache 省一半 prefill、context_length 沒設對整個 session 會炸。
- 2026-06-12[地端 LLM] 權重就是正義:284B 砍到 2-bit,還是比塞得下的小模型強
把 DeepSeek-V4-Flash(284B)壓到非對稱 Q2 才塞進 128GB 小盒子。聽起來像自殺式量化,但它只砍 routed experts、把高精度留在該留的層。實際當 agent 跑 280 輪零退化——權重夠大,2-bit 也壓不垮。
- 2026-06-12[地端 LLM] 第一次跑 Q2 就以為模型變笨了 —— 284B DeepSeek-V4-Flash 在 128GB 桌機,真兇是 parser 不認 DSML
DeepSeek-V4-Flash 是 284B 的 frontier 模型。我用 antirez 的 ds4 引擎 + 非對稱 Q2 在單台 GB10 跑起來,15.6 tok/s。本來以為 2-bit 量化讓它假裝呼叫工具,結果真兇是 runtime 沒接 DSML parser。
- 2026-06-26[趣味競賽 進階 #5] 別讓助理每次都重讀整本對話:KV cache 存硬碟,回神快 7 倍
對話一長,每傳一句它都要把整段重讀一遍(re-prefill)才回你——重開、被擠掉快取後尤其痛。stock llama.cpp 沒內建把 KV cache 存硬碟(feature 被官方標 not planned),我用一支 60 行的 proxy 騙它做到:restore 比重算快 7×(5K 對話 9.9 秒→1.4 秒)。附:機制、proxy 設計、和為什麼我目前還沒上線它。
不想錯過新文章?
訂閱我確保不漏接!
隨時一鍵退訂。