DeepSeek-V4-Flash on DGX Spark · part 3
[地端 LLM] 權重就是正義:284B 砍到 2-bit,還是比塞得下的小模型強
❯ cat --toc
TL;DR
權重就是正義:DeepSeek-V4-Flash 是 284B 的大模型,要塞進 128GB 小盒子,得砍到非對稱 Q2(約 80GB)。聽起來像自殺式量化——但它只砍「量大、每個只處理一小撮 token」的 routed experts,把 attention / shared experts / output / embedding 全留 Q8/F16。所以這是聰明的量化——像手術刀一樣,只精準量化那些不太影響品質的層,品質幾乎沒掉。實際當 daily agent 跑 280 輪零退化:繁中流暢、技術推理正確、工具呼叫結構完整。權重夠大,2-bit 也壓不垮它。(順帶:abliterated 版沒有審查。)
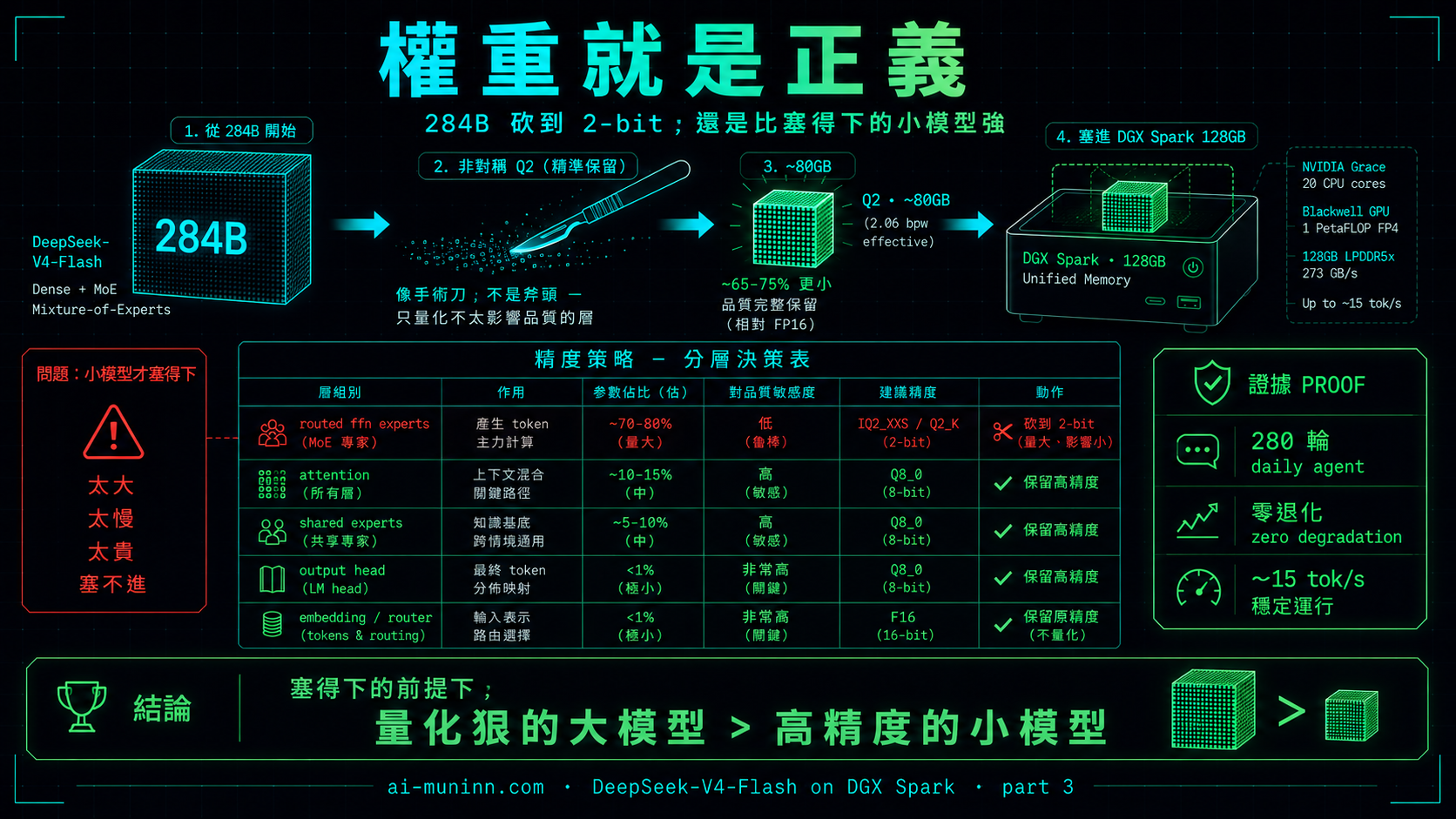
本文重點,一圖看懂
白話版:把百科全書印成口袋本,字變小,內容全在
DeepSeek-V4-Flash 是一顆 284B 的大模型,正常要一整櫃伺服器。要塞進我桌上那台 128GB 的小主機,得用「量化」把它壓小——把每個數字的精度砍掉。
砍到 2-bit(Q2)聽起來很恐怖,像把一本書的字壓到看不清。但這顆的量化很聰明:它只把「佔體積最大、但每個只處理一小撮內容」的部分壓狠,真正決定它聰不聰明的核心(注意力、推理、輸出)全留高精度。
結果就是:體積塞得進小盒子,腦袋還是那顆 284B 的腦袋。我把它當每天的 AI 助理用,跑了 280 輪重度任務,沒有一次掉鏈子。這篇就在講,為什麼一顆夠大的模型,即使砍得這麼狠,還是贏。
前言:284B 塞進小盒子,代價是砍到 2-bit——還能用嗎?
寫 ds4 引擎的 antirez(Redis 那個)講他為什麼做這個:「Very capable open weight models finally exist. DeepSeek v4 Flash feels quasi-frontier.」 夠強的 open weight 模型終於出現,DSv4-Flash 摸到了 quasi-frontier。
但 quasi-frontier 的代價是大。284B 在單台 128GB 的 DGX Spark 上只有一條路:狠狠量化到塞得下。非對稱 Q2,壓到約 80GB。
這是 DeepSeek-V4-Flash on DGX Spark 系列 Part 3。Part 1 把它跑起來、Part 2 調成每天順手的 agent。這篇回答一個我一開始也懷疑的問題:砍到 2-bit 這麼狠,它還剩多少? 答案出乎意料——剩很多。
為什麼 2-bit 沒把它砍笨:它聰明地只量化不太影響品質的層
「2-bit」這個數字會嚇人,但它沒講清楚砍的是「哪些」。DeepSeek-V4-Flash 的量化是非對稱的:
| 層 | 精度 |
|---|---|
| routed ffn gate/up experts | IQ2_XXS |
| routed ffn down experts | Q2_K |
| shared experts / attention / output head | Q8_0 |
| embedding / router / indexer | F16 |
被砍到 2-bit 的全是 routed experts——它們佔了模型絕大部分的體積,但每個 expert 只處理一小撮被 router 分過去的 token。換句話說,砍的是「量大、分散、每個影響有限」的部分。
真正決定品質的層——注意力(它怎麼讀上下文)、shared experts(每個 token 都會過)、output head(它怎麼吐字)、embedding——全留 Q8 或 F16。所以這不是拿斧頭亂砍,是拿手術刀:精準地只量化那些不太影響品質的層,把高精度留給決定品質的核心,讓品質受的影響降到最低。 這就是為什麼一個聽起來像被腰斬的模型,實際用起來不像。(同一張精度表在 Part 1 解釋過為什麼工具呼叫沒壞——那些格式相關的層也在高精度這側。)
體感實證:280 輪零退化,我沒跑 benchmark,我看了它幹活
光講機制不夠,我要證據。我沒跑 TMMLU+ 那種合成 benchmark——我做的是把它接成每天在用的 agent,直接讀它真實的生產記錄。
快一個禮拜、約 30 小時、280 輪重度使用(平均每輪 6.7 次工具呼叫)的 log,我從頭讀了一遍:
- 繁中流暢自然,台灣口語,零簡中洩漏。
- 技術推理正確——它正確判斷了一台 GTX 970 的 VRAM 夠不夠跑某顆模型、unified memory 是什麼、估了 tok/s,全對。
- 工具呼叫結構完整,連巢狀多行 python 的參數都 escape 正確。
- 零退化:280 輪重度使用,沒有 runaway、沒有重複迴圈、沒有壞掉的 JSON。
一顆「2-bit」的模型,跑了 280 輪重度 agentic,沒掉一次鏈子。比起一個合成分數,我更信這快一個禮拜、280 輪真在幹活的記錄。
順帶:它還是一顆沒上鎖的模型
這顆是 huihui 的 abliterated 版——無審查。問到敏感題,它不會直接打回票,審查 filter 過得去。
我不打算在這篇深挖政治(那是另一個坑)。重點只是:在「夠大 + 量化塞得下 + 沒審查」三件事同時成立的前提下,你在自己的小盒子上,有一顆完全屬於你的 quasi-frontier 模型。沒有 API、沒有額度、沒有人在另一端決定它能說什麼。
權重就是正義
繞回標題。在一台塞得下的機器上,你要選一顆模型——是一顆精度漂亮的小模型,還是一顆砍到 2-bit 的大模型?
我選後者。一顆 284B 即使砍得這麼狠,它見過的世界、學到的推理深度還在;小模型再高精度,天花板就是小。decode 慢一點(~15 tok/s)我認,但品質的地板高很多。
權重就是正義——在小盒子上,規模是壓不垮的本錢。 antirez 賭 open weight 終於夠好,賭對了;而「夠好」的意思是,連把它砍到 2-bit,它都還頂得住。
收穫
最花時間的地方
不是技術,是說服我自己「2-bit 不會是廢的」。我一開始的預設跟大家一樣——Q2 = 腰斬 = 大概很笨。要推翻這個預設,靠的不是 benchmark 分數,是回去翻那 280 輪的生產 log,一條一條看它其實沒崩。最花時間的往往不是跑實驗,是放下成見。
別只看 bit 數
看量化別只看 bit 數,看砍的是哪些層。「Q2」「4-bit」這種標籤只講了平均,沒講分布。非對稱量化可以把核心層留高精度、只砍冗餘的部分;同樣叫「Q2」,砍對地方跟砍錯地方差很多。判斷一個量化能不能用,先問它留了什麼。
通用原則
量化的數字會騙人。 「2-bit」聽起來像把模型砍半,但砍 routed experts ≠ 砍掉它的推理。一顆夠大的模型本來就有很多冗餘;把這些砍掉、核心留住,你得到的是一顆塞得進小盒子、但腦袋沒變笨的大模型。規模給你的不只是能力,是被壓縮的空間。
TL;DR
- 權重就是正義:284B 砍到非對稱 Q2(~80GB)塞進 128GB,品質還是頂得住。
- 「2-bit」是聰明的非對稱量化:像手術刀只量化不太影響品質的 routed experts,attention / shared / output / embedding 留 Q8/F16。
- 體感實證:280 輪零退化(繁中 / 推理 / 工具全穩),不是合成 benchmark。
- 順帶:abliterated,沒有審查,過得了 filter。
- 選模型:塞得下的前提下,量化狠的大模型 > 高精度的小模型。規模是壓不垮的本錢。
Also in this series: Part 1 — 在 128GB 小盒子上跑 284B,然後錯怪了 2-bit · Part 2 — 把 15 tok/s 的 284B 當每天的 agent 大腦:怎麼設才舒服
常見問題
- 把 284B 模型量化到 2-bit,品質還能用嗎?
- 能,出乎意料地好。關鍵是『非對稱 Q2』——只把量大、但每個只處理一小撮 token 的 routed experts 砍到 2-bit,跟推理、格式、注意力相關的層(attention / shared experts / output head)全留 Q8,embedding / router 留 F16。這是聰明的非對稱量化——像手術刀一樣,只精準量化那些不太影響品質的層,核心精度沒動。我接成 daily agent 跑了 280 輪,零退化。
- 為什麼要把 DeepSeek-V4-Flash 砍到 Q2?
- 為了塞進單台 128GB 的 DGX Spark。284B 的模型全精度要一整櫃伺服器;非對稱 Q2 把它壓到約 80GB,剛好擠進 128GB unified memory。代價是 decode 慢(~15 tok/s),但品質意外地保住了。
- Q2 量化的 284B,跟一顆精度更高的小模型比,哪個好?
- 我的體感是大的贏。一顆夠大的模型(284B)即使砍到 2-bit,它見過的東西、學到的推理深度還在;小模型再高精度,天花板就是小。在塞得進同一台機器的前提下,我寧可要一顆量化狠的大模型。這就是『權重就是正義』——規模是壓不垮的本錢。
- DeepSeek-V4-Flash 這顆 abliterated 版有內容審查嗎?
- 沒有。huihui 的 abliterated 版無審查,問敏感題它不會直接打回票,審查 filter 過得去。這篇重點不在這,只是順帶一提它是顆沒上鎖的模型。
接著讀
- 2026-06-12[地端 LLM] 第一次跑 Q2 就以為模型變笨了 —— 284B DeepSeek-V4-Flash 在 128GB 桌機,真兇是 parser 不認 DSML
DeepSeek-V4-Flash 是 284B 的 frontier 模型。我用 antirez 的 ds4 引擎 + 非對稱 Q2 在單台 GB10 跑起來,15.6 tok/s。本來以為 2-bit 量化讓它假裝呼叫工具,結果真兇是 runtime 沒接 DSML parser。
- 2026-06-12[地端 LLM] 把 15 tok/s 的 284B 當每天的 agent 大腦:DeepSeek-V4-Flash 怎麼設才舒服
一顆 284B、只有 15 tok/s 的模型,要拿來當每天的 agent 大腦,得先做點準備才用得舒服。server 跟 agent 框架兩邊各一組設定:--no-mmap 冷啟砍到 57 秒、KV disk cache 省一半 prefill、context_length 沒設對整個 session 會炸。
- 2026-07-09[本地 LLM] 我把 FlashMemory 重訓到自己的 Q2 build 上,它還是改善不了 V4-Flash 的 native lightning indexer
DeepSeek-V4-Flash 本來就有一套 native lightning indexer,追真實 attention 追到 93–96%。FlashMemory 會先把候選 chunk 篩小一圈,但直接拿來用跟亂猜沒兩樣;我重訓到自己的 Q2 build 上,也只爬到 89–92%。GB10 上 NO-GO。
- 2026-07-07[地端 LLM] 284B 塞得進 128GB、長 context 還跑得動:DeepSeek-V4-Flash 打的是 KV cache,不是參數量
DeepSeek-V4-Flash 是 284B 的 MoE,長 context 還能在 128GB 的 GB10 上跑得動,靠的不是權重小,是它天生就在打 KV cache:混合式 attention(SWA + CSA + HCA)把 KV 壓到 64K 只剩 871MiB;lightning indexer 挑的是壓過的 entry、一步只讀幾百列。這篇拆 ds4 的實作,順便講為什麼你沒辦法再靠量化 KV 省記憶體。
不想錯過新文章?
訂閱我確保不漏接!
隨時一鍵退訂。