DGX Spark · part 39
[vLLM] DiffusionGemma 26B NVFP4 on a DGX Spark: 158 tok/s, and why diffusion tok/s lies
❯ cat --toc
- In plain English: a model that writes a whole block at once
- Introduction
- The fast path is a prebuilt image, not a patched build
- Serving it: pass the model first, add one diffusion flag
- 158 / 143 / 257 tok/s — but only with the canvas full
- Why a single tok/s number lies for diffusion
- Tool calling works with the gemma4 parser
- Takeaways
- The real time sink
- Reusable takeaways
- The broader lesson
- TL;DR
TL;DR
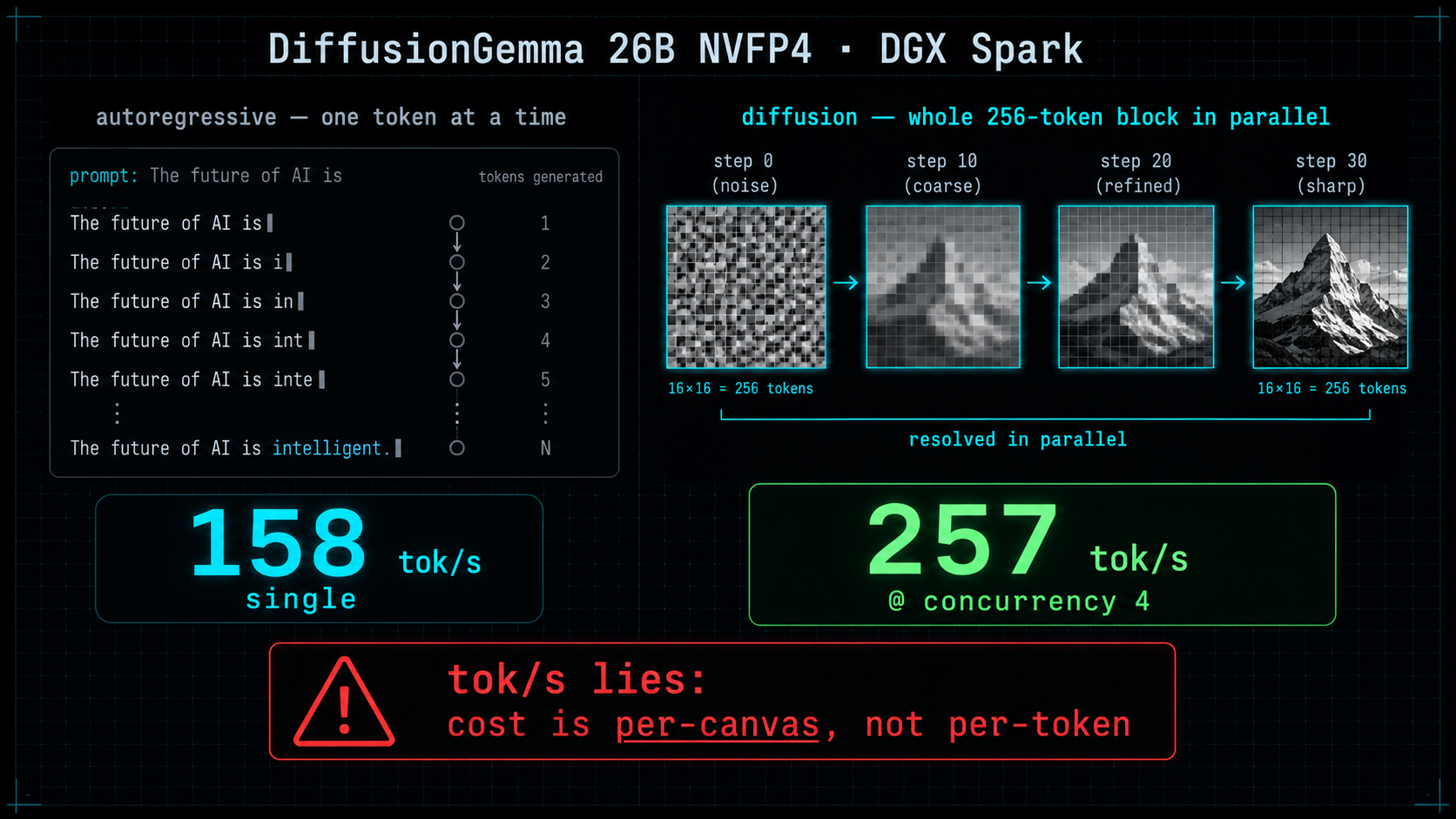
DiffusionGemma on vLLM works on a 128GB DGX Spark today — no patching. The official image (vllm/vllm-openai:gemma, aarch64-cu130 for GB10) already includes diffusion_gemma, so no PR wait or source build. Serving nvidia/diffusiongemma-26B-A4B-it-NVFP4 warm, with the 256-token canvas filled: 158 tok/s prose, 143 tok/s code single-stream, 257 tok/s aggregate at concurrency 4 — above my bf16 bare-Transformers numbers (43.6 / 84.9) and the community report (101 / 148). Tool calling works with the gemma4 parser. Gotcha: one tok/s number lies for diffusion. Cold or short replies drop to ~16 tok/s; cost is per-canvas, not per-token.
The whole post in one image
In plain English: a model that writes a whole block at once
DiffusionGemma is an open-source language model from Google, and the interesting part is how it writes. Most AI models — the kind behind ChatGPT — emit one token at a time, left to right. This one lays down a blank 256-token canvas and sharpens the whole block at once, closer to a blurry photo coming into focus than a cursor crawling across a line.
I'd benchmarked it once before on my 128GB NVIDIA DGX Spark and found that writing a whole block at once is unusually fast on this machine, because it isn't bottlenecked by memory bandwidth. Back then I could only run it the slow way — the fast path, vLLM, wasn't supported yet. This post is the update: the fast path now ships as an official prebuilt image, no waiting and no patching. I got it running and measured 158 tok/s on a single stream and 257 tok/s aggregate across four at once.
One thing to know going in: tok/s lies for this kind of model. It works on a whole 256-token block at a time, so a two-word "got it" takes almost as long as a full 256-token answer — which makes short replies look absurdly slow. You can't put these numbers head-to-head with a normal autoregressive model; if you're still sorting out the categories, start with the beginner's guide to picking a model.
Introduction
A diffusion language model fills a canvas instead of typing left to right — picture a Polaroid sharpening rather than a cursor crawling across the line. That single difference is why it behaves nothing like the autoregressive models covered in the complete Gemma 4 on DGX Spark guide and the rest of this series.
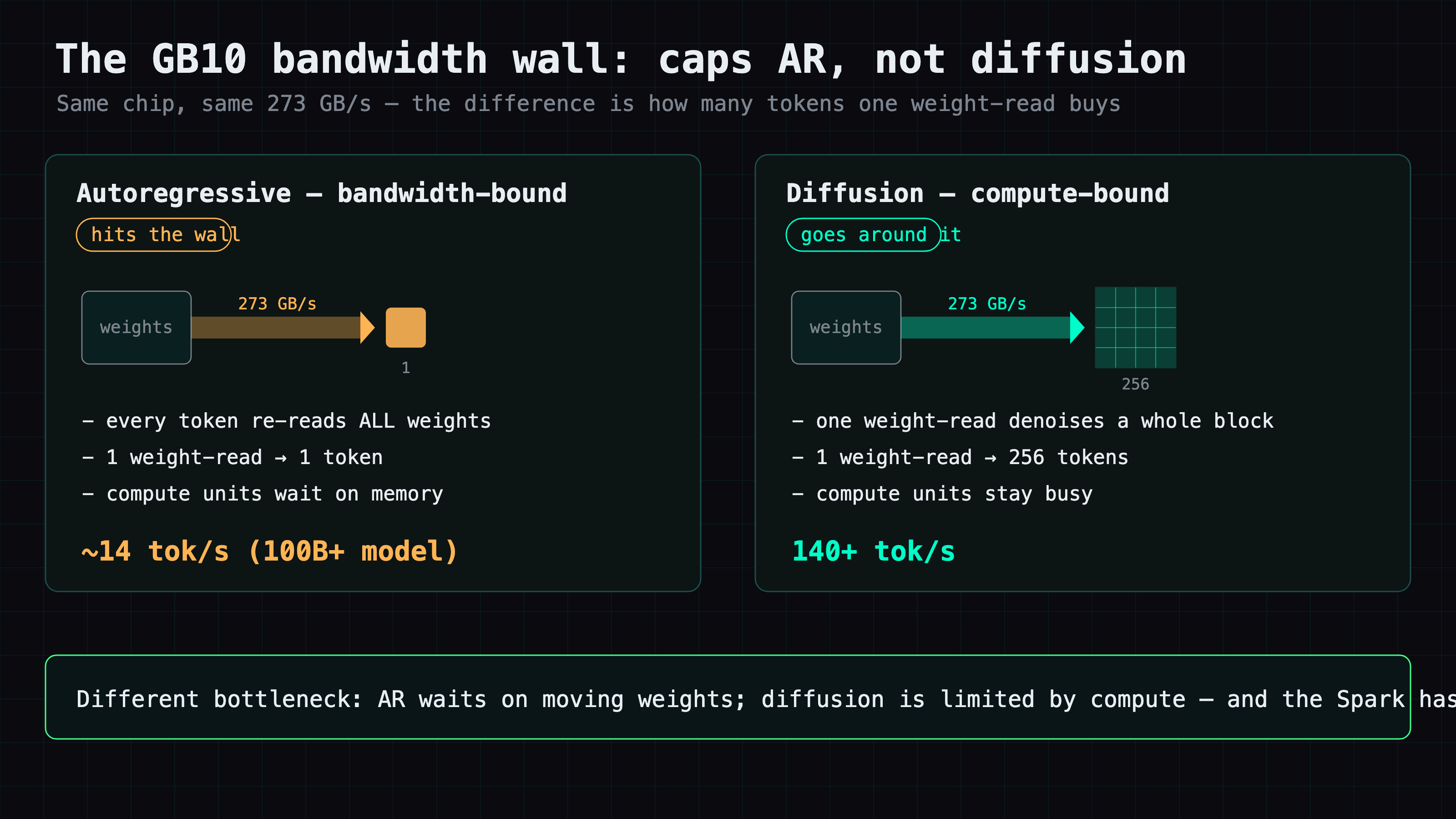
I'd already measured DiffusionGemma 26B-A4B once, on bare Transformers, and concluded the GB10 bandwidth wall doesn't apply to it. But the fast path — vLLM — wasn't an option yet; the model was three days old and diffusion_gemma support was still an in-flight PR. So I parked it: "revisit once vLLM ships."
Then a post on r/Vllm showed someone already serving it on vLLM on a DGX Spark — 100+ tok/s — and not by cherry-picking patches. They'd pulled an official prebuilt image. So I reproduced the whole thing on my own box. Here's what I found.
The fast path is a prebuilt image, not a patched build
Here's the part I'd gotten wrong in my own notes. I had it filed as "wait for vLLM PR #45163 to merge." You don't wait. That PR only merged on June 12, and even now it isn't in a stable release — but the vLLM project publishes special model-launch image tags ahead of the stable cut, and diffusion_gemma was already in one of them:
docker pull vllm/vllm-openai:gemma-aarch64-cu130
The vllm/vllm-openai repo carries a multi-arch gemma tag plus architecture-specific builds underneath it; gemma-aarch64-cu130 is the arm64 + CUDA 13 one — the exact match for a GB10 (~10GB compressed). No source build, no cherry-pick, no --enforce-eager workaround — just the image, already carrying the diffusion code at vLLM 0.22.1rc1.dev357+g74b5964f0.
The broader takeaway: when a model lands and its support PR hasn't reached a stable release yet, check Docker Hub for a launch-tagged image before you assume you have to build vLLM yourself. "Not in a stable release" doesn't mean "not shipped."
Serving it: pass the model first, add one diffusion flag
The image's entrypoint is vllm serve, so the model is the first positional argument. The only difference from a normal vllm serve is --diffusion-config:
docker run -d --rm --gpus all --name dgemma \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e VLLM_USE_V2_MODEL_RUNNER=1 \
-e HF_HUB_OFFLINE=1 \
-p 8000:8000 \
vllm/vllm-openai:gemma-aarch64-cu130 \
nvidia/diffusiongemma-26B-A4B-it-NVFP4 \
--host 0.0.0.0 --port 8000 \
--trust-remote-code --dtype auto \
--max-model-len 100000 \
--gpu-memory-utilization 0.70 \
--max-num-batched-tokens 8192 \
--max-num-seqs 4 \
--diffusion-config '{"canvas_length": 256, "max_denoising_steps": 48}' \
--attention-backend TRITON_ATTN \
--enable-auto-tool-choice --tool-call-parser gemma4 --reasoning-parser gemma4 \
-tp 1
The NVFP4 checkpoint is NVIDIA's own ModelOpt quant of google/diffusiongemma-26B-A4B-it — 18GB on disk, versus 49GB for the bf16 base. canvas_length is how many tokens the model refines as one block; max_denoising_steps is how many passes it takes to clean that block. Those two are the diffusion equivalent of "batch size" and "how hard it thinks." TRITON_ATTN is the recommended backend and it happens to be friendly to GB10's SM121. It took a few minutes to reach "Application startup complete".
158 / 143 / 257 tok/s — but only with the canvas full
My first benchmark pass produced two numbers that looked impossible next to each other:
prose (sky blue): 84 tok / 5.091s = 16.5 tok/s ← first request, cold
code (linked list): 256 tok / 1.208s = 212.0 tok/s ← full 256-canvas, warm
16.5 and 212 from the same model, back to back. Both are real, and the gap is the whole point of this article — but it's confounded by two things, so I reran clean: one warmup, then outputs forced to ~256 tokens so the canvas always fills.
SINGLE (warm, ~256 tok, thinking off):
prose: 256 tok / 1.613s = 158.7 tok/s
code: 256 tok / 1.789s = 143.1 tok/s
CONCURRENCY=4: 1024 tok / 3.980s = 257.3 tok/s aggregate
Lined up against everything else I have on this model:
| precision | runtime | prose | code | concurrency 4 | |
|---|---|---|---|---|---|
| my earlier smoke test | bf16 | bare Transformers | 43.6 | 84.9 | — |
| community (r/Vllm) | NVFP4 | vLLM | — | 101 | 148 |
| this post | NVFP4 | vLLM | 158.7 | 143.1 | 257.3 |
One caveat before anyone quotes the 158: I forced full-length outputs, so these are best-case peaks — the canvas is always full, which is the most favorable case for diffusion. The community's 101 is almost certainly mixed-length and closer to what a chat session feels like. Different measurement, not a contradiction.
Why a single tok/s number lies for diffusion
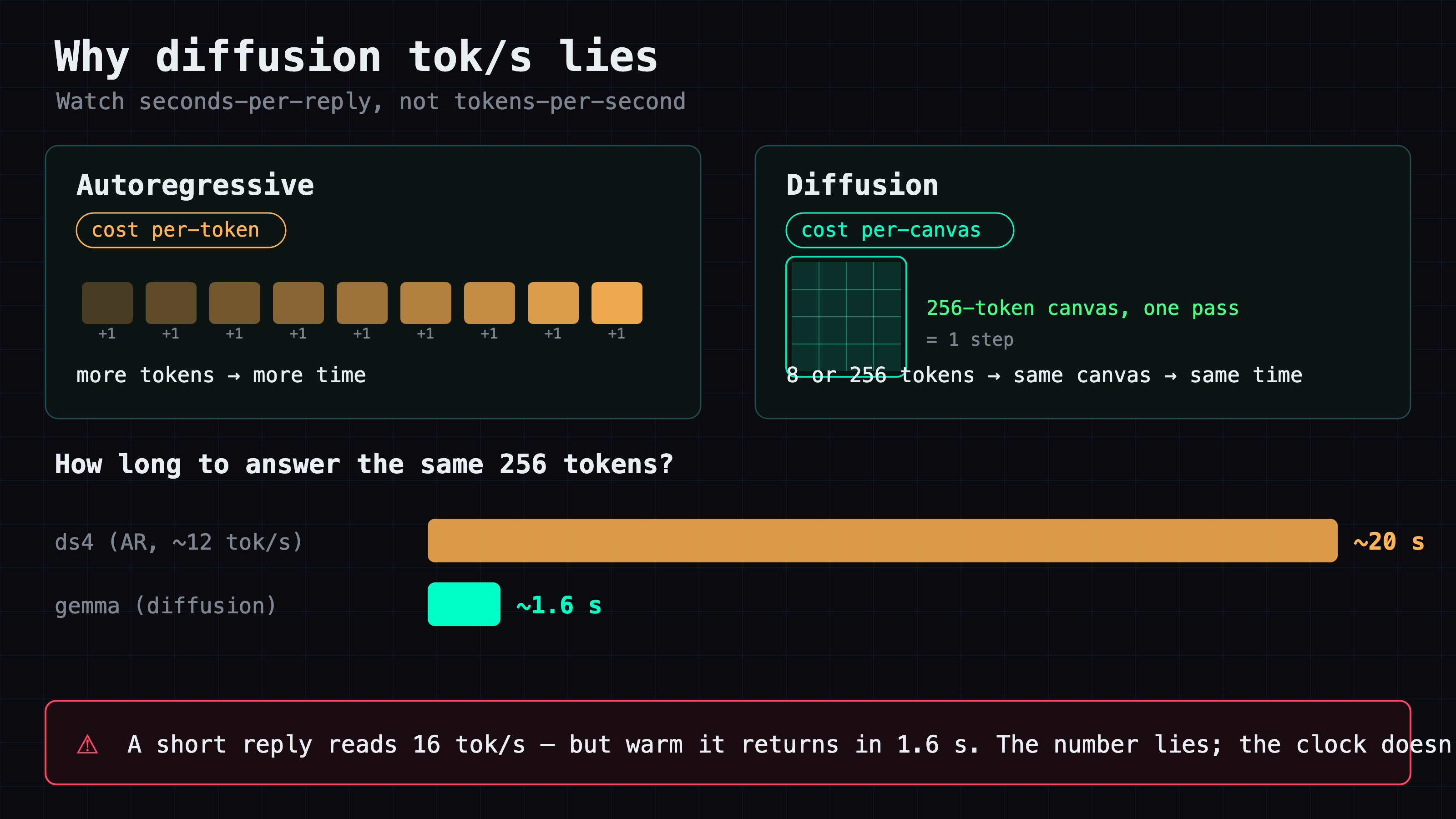
Go back to the 16.5 vs 212. An autoregressive model decodes one token per forward pass, so tok/s is roughly constant whether the answer is 8 tokens or 800. A diffusion LM doesn't. It fills a fixed 256-token canvas and runs 48 denoising steps over the whole block, then commits it. The cost is per-canvas, not per-token.
So an 8-token "sure, let me check" and a 256-token essay cost nearly the same wall-clock time. The short answer just spreads that fixed cost over 8 tokens and reports a tiny tok/s. The cold prose run wasn't slow because the model is slow — it was a short, natural-length answer (84 tokens) on a cold engine, and the per-canvas overhead dominated.
This matters if you're putting a diffusion model behind an agent. An agent emits a lot of short turns — "calling the tool," "got it, continuing" — and every one of those will look sluggish in tok/s even though wall-clock per turn is fine. Don't benchmark a diffusion LM the way you benchmark an AR one, and don't put a single tok/s number on its model card without saying what the output length was.
Tool calling works with the gemma4 parser
For a diffusion model to be useful as an agent brain it has to emit clean tool calls, not just prose. It does. One smoke test with --tool-call-parser gemma4:
TOOL_CALLS: [{"function": {"name": "get_weather", "arguments": "{\"city\": \"Tokyo\"}"}}]
finish_reason: tool_calls
The function call is well-formed, finish_reason is correct, and nothing leaks into the content field. NVFP4 quantization and diffusion decoding didn't break the tool-call format — the same way they don't on a quantized AR model.
Takeaways
The real time sink
Not the deployment — that was a docker pull and a docker run. The hard part was trusting the two numbers. 16.5 and 212 tok/s from the same model in the same minute reads like a broken benchmark, and the instinct is to "fix" the measurement until it gives one clean number. The actual fix was the opposite: accept that both are correct and that the spread is the finding. The expensive part wasn't running the test — it was un-learning the AR assumption that tok/s is a property of the model rather than a property of the model and the output length.
Reusable takeaways
- When a model's support PR is still open, check Docker Hub for a launch-tagged image (
:gemma,:<model>) before building from source. Shipped ≠ released. - Benchmark a diffusion LM at full canvas and at short outputs, and report both. One number hides the per-canvas cost.
- Always warm up before measuring on vLLM — the cold first request eats graph-capture cost and will tank the model's numbers for no real reason.
The broader lesson
A throughput number only means something if you say which decoding method produced it. "158 tok/s" and "16 tok/s" describe the same model on the same box one second apart; the difference is entirely the canvas fill. Bandwidth caps autoregressive decode on a GB10; it doesn't cap parallel diffusion denoising. The Spark was never slow — the autoregressive paradigm was.
TL;DR
- DiffusionGemma on vLLM runs on a 128GB DGX Spark now, via the official
vllm/vllm-openai:gemma-aarch64-cu130image — no PR-waiting, no cherry-picking, no source build. - Serve
nvidia/diffusiongemma-26B-A4B-it-NVFP4(18GB) with--diffusion-config '{"canvas_length": 256, "max_denoising_steps": 48}'+TRITON_ATTN+ thegemma4tool/reasoning parsers. - Warm, full canvas, thinking off: 158.7 tok/s prose, 143.1 code single-stream, 257.3 aggregate at concurrency 4 — best-case peaks.
- tok/s lies for diffusion: cost is per-canvas, not per-token, so short/cold replies drop to ~16 tok/s. Report output length with the number.
- Tool calling works (
gemma4parser, clean function call). - The GB10 bandwidth wall caps AR decode, not diffusion. Same chip, 14 tok/s for a 100B+ AR model, 140+ for a 26B diffusion one.
Also in this series: Part 38 — Why I run a 30B model on a 128GB DGX Spark, not a 120B · Part 1 of the DeepSeek-V4-Flash trilogy — a 284B on a 128GB box
FAQ
- Can you run DiffusionGemma on vLLM on a DGX Spark (GB10)?
- Yes. As of June 2026 there's an official prebuilt image, vllm/vllm-openai:gemma (with an aarch64-cu130 variant that matches GB10 exactly), that already has diffusion_gemma support baked in. You don't have to wait for the support PR to land in a stable release or cherry-pick patches yourself — just docker pull the gemma tag and serve the nvidia/diffusiongemma-26B-A4B-it-NVFP4 checkpoint.
- How fast is DiffusionGemma 26B NVFP4 on a GB10?
- On my DGX Spark, warm and with the 256-token canvas filled, NVFP4 gets ~158 tok/s on prose and ~143 tok/s on code single-stream, and ~257 tok/s aggregate at concurrency 4. That's a best-case peak — I forced full-length outputs. A cold first request or a short reply drops to ~16 tok/s, because diffusion pays a fixed denoising cost per canvas regardless of how many tokens it actually emits.
- Why does diffusion tok/s depend on output length?
- A diffusion LM doesn't decode left-to-right one token at a time. It fills a fixed-size canvas (256 tokens here) and refines the whole block over a fixed number of denoising steps (48). The cost is roughly per-canvas, not per-token. So a 256-token answer and an 8-token answer cost almost the same wall-clock — which means the short answer looks dramatically slower in tok/s. The metric is real but it's not comparable to autoregressive tok/s.
- Does the GB10 bandwidth wall apply to diffusion language models?
- Not the way it does to autoregressive models. GB10's ~273 GB/s memory bandwidth caps AR decode hard (a 100B+ AR model sits around 14 tok/s). Diffusion decode is parallel block denoising, so weight reads amortize across the whole canvas and the bottleneck shifts from bandwidth toward compute — a 26B diffusion model clears 140+ tok/s on the same chip. The slow part of the Spark was always the AR paradigm, not the silicon.
Read next
- 2026-07-07DGX Spark in 2026: What Still Works, What Broke, and What I'd Run Today
A current 2026 guide to running local AI on DGX Spark: vLLM, official Gemma 4 NVFP4 weights, MTP, long-context multimodal options, and the traps still worth avoiding.
- 2026-06-04[Benchmark] Gemma 4 12B Omni on DGX Spark: Weight-Only NVFP4 Beats W4A4 (and Keeps Multimodal)
I quantized Google's new omni Gemma 4 12B on a DGX Spark GB10. Weight-only NVFP4 hits 24.9 tok/s in 7.7 GB and keeps image/audio/video working — full W4A4 is slower AND breaks multimodal.
- 2026-06-01[Benchmark] NVFP4 W4A4 beats FP8 on a DGX Spark MoE: 67 vs 52 tok/s once CUDA graphs fire
On a GB10 DGX Spark, NVFP4 W4A4 went from 23 to 67 tok/s the moment I dropped --enforce-eager — beating FP8 by 29% and saving 16GB. The catch from Part 32 was real, just dense-only.
- 2026-05-30NVFP4 is 1.5× FP8 on a DGX Spark — but it's compression, not the FP4 cores
On a GB10 DGX Spark, NVFP4 beats FP8 by ~1.5× for single-stream decode on a dense model. But the win is bandwidth (smaller weights), not the FP4 tensor cores — the fastest path never touches them.
Don't miss the next one
Subscribe, and you won't.
One-click unsubscribe anytime.