DGX Spark · part 39
[vLLM] DiffusionGemma 26B NVFP4 上 DGX Spark:158 tok/s,但 diffusion 的 tok/s 會騙你
❯ cat --toc
TL;DR
DiffusionGemma 用 vLLM 在 128GB DGX Spark 免改跑。 官方 vllm/vllm-openai:gemma(aarch64-cu130)已含 diffusion_gemma,免等 PR/自編。nvidia/diffusiongemma-26B-A4B-it-NVFP4,warm、256-token 滿畫布:文字 158 tok/s、code 143 tok/s 單條,4 並行 257 tok/s;高過 bf16 裸 Transformers 43.6/84.9、社群 101/148。Tool call gemma4。坑:單一 tok/s 誤判 diffusion。 冷啟/短答 16 tok/s,成本按畫布,非 token。

一張圖看完整篇
白話版:把 AI 模型搬上桌機,而且這次它「橫著生字」
DiffusionGemma 是 Google 開源的一種 AI 語言模型,特別之處是它生字的方式跟一般的不一樣。一般的 AI(像 ChatGPT 背後那種)是「一個字一個字往下接龍」;這顆模型是「先鋪一整塊空白,再一次把整塊塗清楚」—— 比較像照片從模糊慢慢對焦,而不是逐字打字。
我之前在自己桌上那台 128GB 的 NVIDIA DGX Spark 上量過它,發現「橫著生字」這招在這台機器上特別快,因為它不卡記憶體頻寬。那時只能用比較陽春的方式跑,正式的高效跑法(vLLM)還在等支援。這篇就是:那個高效跑法現在直接有官方現成包可以拉了,不用自己改、不用等。我把它在自己機器上跑起來,量到單條每秒 158 個字、四條同時跑加起來每秒 257 個字。
但有個坑一定要先講:這種模型的「每秒幾個字」會騙人。它一次處理一整塊(256 個字的畫布),所以你叫它回「好的」兩個字,跟回滿 256 個字,花的時間幾乎一樣 —— 回得短反而看起來超慢。這跟一般 AI 的速度數字不能直接比。
前言
diffusion 語言模型是鋪一張畫布、不是逐字往右打 —— 想像拍立得慢慢顯影,而不是游標在那行字上一格一格爬。就這一個差別,讓它的行為跟這個系列其他篇 benchmark 的 AR 模型完全不一樣。
DiffusionGemma 26B-A4B 我已經量過一次了,用裸 Transformers,當時的結論是 GB10 的頻寬牆對它不成立。但快的那條路 —— vLLM —— 當時還不能用;模型才發三天,diffusion_gemma 支援還是一個進行中的 PR。所以我先擱著:「等 vLLM 支援了再回頭。」
後來 r/Vllm 上一篇貼文出現,有人已經在 DGX Spark 上用 vLLM 跑起來 —— 100+ tok/s —— 而且不是靠自己撿 patch,他拉的是官方現成 image。於是我在自己機器上整套重現了一遍。這篇就是結果。
快的那條路是官方現成 image,不是自己編的版本
這裡是我自己筆記裡記錯的地方。我原本以為只要「等 vLLM PR #45163 merge」就好。其實不用等 —— 那個 PR 6/12 才 merge,而且到現在都還沒進 stable release,但 vLLM 會在 stable 之前先推特製的「模型首發」image tag,diffusion_gemma 早就在其中一個裡面了:
docker pull vllm/vllm-openai:gemma-aarch64-cu130
官方 vllm/vllm-openai repo 有一個 multi-arch 的 gemma tag,底下還有分架構的版本;gemma-aarch64-cu130 就是 arm64 + CUDA 13 那個 —— GB10 要用的就是它(壓縮約 10GB)。不用編源碼、不用 cherry-pick、不用 --enforce-eager 繞 —— 就是那個 image,已經把 diffusion 的 code 帶在 vLLM 0.22.1rc1.dev357+g74b5964f0 裡。
這次學到的是:模型剛落地、支援 PR 還沒進 stable 的時候,先去 Docker Hub 看有沒有首發 tag 的 image,再決定要不要自己編 vLLM。「沒進 stable release」不等於「沒推出來」。
把服務跑起來:一個 positional model,一個 diffusion flag
image 的 entrypoint 是 vllm serve,所以 model 是第一個 positional 參數。這裡唯一不是普通 vLLM serve 的東西就是 --diffusion-config:
docker run -d --rm --gpus all --name dgemma \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e VLLM_USE_V2_MODEL_RUNNER=1 \
-e HF_HUB_OFFLINE=1 \
-p 8000:8000 \
vllm/vllm-openai:gemma-aarch64-cu130 \
nvidia/diffusiongemma-26B-A4B-it-NVFP4 \
--host 0.0.0.0 --port 8000 \
--trust-remote-code --dtype auto \
--max-model-len 100000 \
--gpu-memory-utilization 0.70 \
--max-num-batched-tokens 8192 \
--max-num-seqs 4 \
--diffusion-config '{"canvas_length": 256, "max_denoising_steps": 48}' \
--attention-backend TRITON_ATTN \
--enable-auto-tool-choice --tool-call-parser gemma4 --reasoning-parser gemma4 \
-tp 1
NVFP4 checkpoint 是 NVIDIA 自己用 ModelOpt 壓的版本,base 是 google/diffusiongemma-26B-A4B-it —— 硬碟上 18GB,對照 bf16 base 的 49GB。canvas_length 是模型一次當一塊去精修的 token 數;max_denoising_steps 是清乾淨那塊要幾趟。這兩個就是 diffusion 版的「batch size」跟「想多用力」。TRITON_ATTN 是官方推薦的 backend,剛好對 GB10 的 SM121 友善。從啟動到 "Application startup complete" 幾分鐘。
158 / 143 / 257 tok/s —— 但只有畫布填滿時
我第一輪 benchmark 跑出兩個並排看很矛盾的數字:
一般文字(sky blue): 84 tok / 5.091s = 16.5 tok/s ← 第一個請求,冷
code(linked list): 256 tok / 1.208s = 212.0 tok/s ← 填滿 256 畫布,warm
同一顆模型、前後腳跑出 16.5 跟 212。兩個都是真的,這個落差也是整篇的重點。不過第一次量測混進了兩個變因,所以我排除掉重跑一次:先 warmup 一次,再把輸出強制拉到約 256 token 讓畫布每次都填滿。
單條(warm,約 256 token,thinking 關):
一般文字: 256 tok / 1.613s = 158.7 tok/s
code: 256 tok / 1.789s = 143.1 tok/s
並行 4 條: 1024 tok / 3.980s = 257.3 tok/s aggregate
跟我手上這顆模型的所有其他數字排在一起:
| 精度 | runtime | 一般文字 | code | 並行 4 | |
|---|---|---|---|---|---|
| 我之前的 smoke test | bf16 | 裸 Transformers | 43.6 | 84.9 | — |
| 社群(r/Vllm) | NVFP4 | vLLM | — | 101 | 148 |
| 這篇 | NVFP4 | vLLM | 158.7 | 143.1 | 257.3 |
引用那個 158 之前先把限制講清楚:我強制輸出填滿,所以這些是 best-case 峰值 —— 畫布永遠是滿的,對 diffusion 來說是最有利的情況。社群那個 101 幾乎肯定是混合長度,比較貼近 chat 真實的手感。是量法不同,不是互相矛盾。
為什麼單一個 tok/s 數字對 diffusion 會騙人
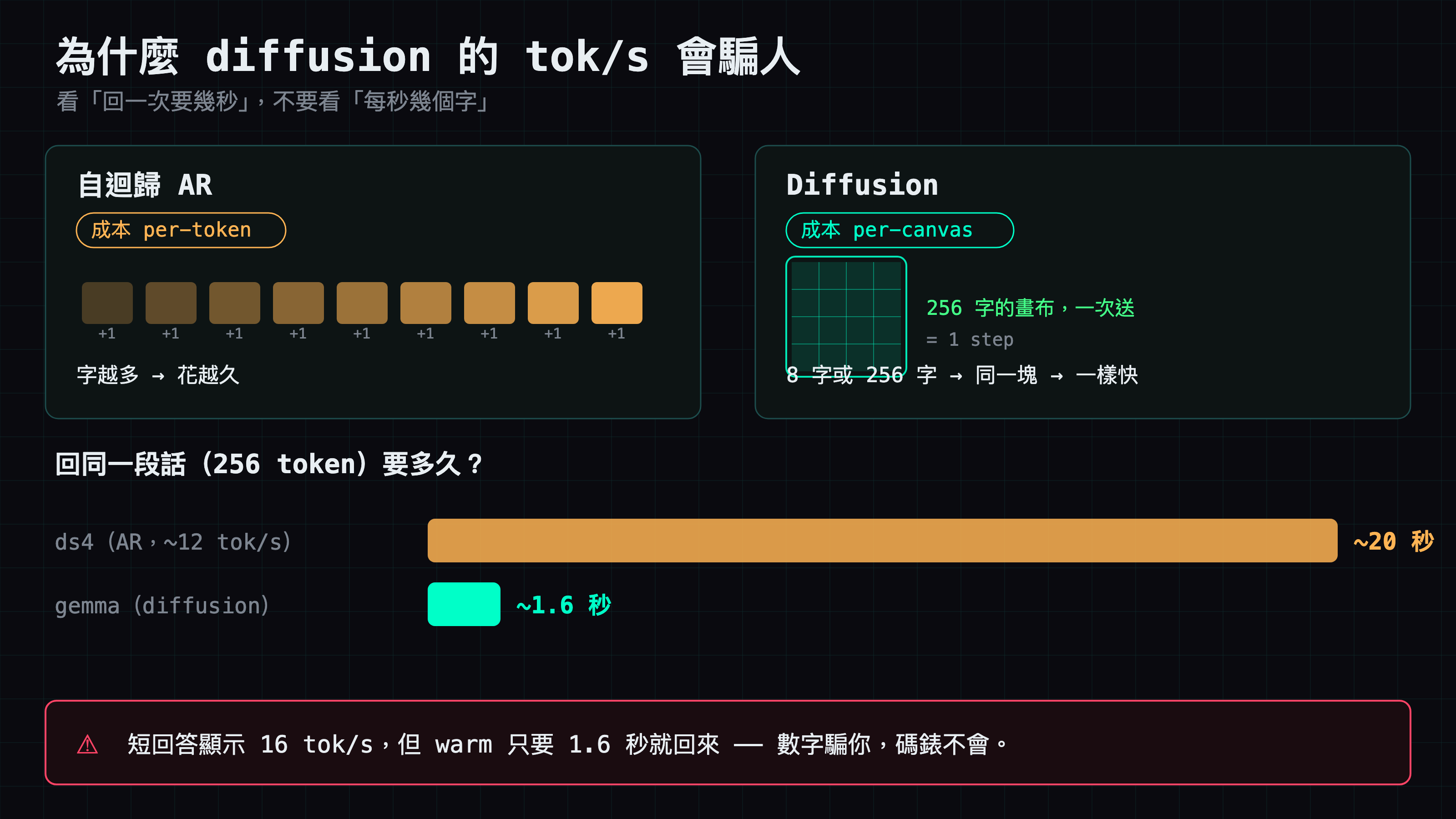
回到 16.5 跟 212。AR 模型一次 forward decode 一個 token,所以不管回 8 個 token 還是 800 個,tok/s 大致是定值。diffusion 不是。它鋪滿固定的 256 畫布、對整塊跑 48 步去噪,再一次 commit。成本是每張畫布,不是每個 token。
所以一句 8 個 token 的「好,我查一下」跟一篇 256 個 token 的長文,花的 wall-clock 幾乎一樣。短回答只是把那筆固定成本攤在 8 個 token 上,換算出來的 tok/s 就很小。那個冷啟的一般文字回答不是因為模型慢 —— 它只是剛冷啟動時一個自然長度的短回答(84 token),時間幾乎都花在每張畫布的固定開銷上。
這對你「把 diffusion 模型擺在 agent 後面」很關鍵。agent 會吐一堆短 turn —— 「呼叫工具」「收到,繼續」—— 每一個換算成 tok/s 都會看起來很鈍,即使每個 turn 的 wall-clock 其實沒問題。別用量 AR 的方式量 diffusion,也別在 model card 上掛一個 tok/s 卻不說輸出長度。
Tool call 用 gemma4 parser 正常
diffusion 模型要能當 agent 的腦,就得吐乾淨的 tool call、不只是一般文字。它做得到。用 --tool-call-parser gemma4 一個 smoke test:
TOOL_CALLS: [{"function": {"name": "get_weather", "arguments": "{\"city\": \"Tokyo\"}"}}]
finish_reason: tool_calls
格式正確的 function call、正確的 finish_reason、沒有漏進 content 欄。經過 NVFP4 量化跟 diffusion decode,輸出格式還是完整,跟量化 AR 模型一樣穩。
收穫
最花時間的地方
不是部署 —— 那就是一個 docker pull 加一個 docker run。時間花在「相信那兩個數字」。同一顆模型、同一分鐘內跑出 16.5 跟 212 tok/s,讀起來像 benchmark 壞了,直覺是想「修」量測直到它給一個乾淨的數字。真正該做的剛好相反:接受兩個都對,而且那個落差本身就是結論。貴的不是跑實驗,是把 AR 的假設拆掉 —— tok/s 不是模型的屬性,是模型加上輸出長度的屬性。
可搬走的診斷方法
- 模型的支援 PR 還開著時,先去 Docker Hub 找首發 tag 的 image(
:gemma、:<模型>)再考慮自己編。推出來 ≠ 進 release。 - diffusion LM 要同時量滿畫布跟短輸出,兩個都報。只報一個數字,看不出每張畫布的固定成本。
- vLLM 上量速度前一定 warmup —— 冷啟第一個請求會吃 graph capture 的成本,會冤枉模型。
通用原則
看一個吞吐數字,一定要連它的 decode 模式一起看才準。「158 tok/s」跟「16 tok/s」描述的是同一顆模型、同一台機器、相差一秒;差別全在畫布填不填滿。AR 的 decode 在 GB10 上會被頻寬卡死,但平行的 diffusion 去噪不會。Spark 從來不慢 —— 慢的是 AR 這種做法。

結論
- DiffusionGemma 用 vLLM 現在就能在 128GB DGX Spark 上跑,走官方
vllm/vllm-openai:gemma-aarch64-cu130image —— 不用等 PR、不用 cherry-pick、不用編源碼。 - serve
nvidia/diffusiongemma-26B-A4B-it-NVFP4(18GB),配--diffusion-config '{"canvas_length": 256, "max_denoising_steps": 48}'+TRITON_ATTN+gemma4的 tool/reasoning parser。 - warm、畫布填滿、thinking 關:一般文字 158.7、code 143.1 單條,並行 4 條 257.3 —— 是 best-case 峰值。
- tok/s 對 diffusion 會騙人:成本是每張畫布、不是每個 token,所以短/冷回答掉到約 16 tok/s。報數字時把輸出長度一起報。
- Tool call 正常(
gemma4parser,乾淨的 function call)。 - GB10 的頻寬牆卡 AR、不卡 diffusion。同一顆晶片,100B+ AR 模型 14 tok/s,26B diffusion 140+。
同系列:Part 38 — 128GB DGX Spark 我為什麼跑 30B 不跑 120B · DeepSeek-V4-Flash 三部曲 Part 1 — 128GB 桌機跑 284B
常見問題
- DiffusionGemma 可以在 DGX Spark(GB10)上用 vLLM 跑嗎?
- 可以。2026 年 6 月起有官方現成 image,vllm/vllm-openai:gemma(還有對應 GB10 的 aarch64-cu130 變體),裡面已經內建 diffusion_gemma 支援。你不用等支援 PR 進 stable release、也不用自己 cherry-pick patch —— docker pull 那個 gemma tag,serve nvidia/diffusiongemma-26B-A4B-it-NVFP4 就好。
- DiffusionGemma 26B NVFP4 在 GB10 上多快?
- 在我的 DGX Spark 上,warm 且把 256 token 的畫布填滿時,NVFP4 單條一般文字約 158 tok/s、code 約 143 tok/s,四條並行加起來約 257 tok/s。這是 best-case 峰值,我強制讓輸出填滿畫布。冷啟的第一個請求、或回答很短的時候會掉到約 16 tok/s,因為 diffusion 的成本是「每張畫布」固定的,跟它實際吐幾個 token 沒關係。
- 為什麼 diffusion 的 tok/s 跟輸出長度有關?
- diffusion LM 不是一個 token 一個 token 往下接。它一次鋪滿固定大小的畫布(這裡是 256 token),對整塊跑固定步數(48 步)的去噪再 commit。成本大致是「每張畫布」而不是「每個 token」。所以回 256 個 token 跟回 8 個 token 花的時間差不多 —— 短回答換算成 tok/s 就會看起來超慢。這個數字是真的,但跟 AR 的 tok/s 不能直接比。
- GB10 的頻寬牆對 diffusion 語言模型也成立嗎?
- 不像對 AR 模型那樣成立。GB10 約 273 GB/s 的記憶體頻寬把 AR 的 decode 卡得很死(100B+ 的 AR 模型大概 14 tok/s)。diffusion 的 decode 是平行去噪整塊 —— compute-bound、不是 bandwidth-bound —— 所以同一顆晶片上,26B diffusion 衝到 140+ tok/s。Spark 慢的一直是 AR 這種做法,不是晶片本身。
接著讀
- 2026-07-07DGX Spark 2026 現況:哪些還能跑、哪些已經過時、我現在會怎麼配
DGX Spark 2026 年中現況整理:現在該用 vLLM、官方 Gemma 4 NVFP4 權重、MTP、長 context 多模態,以及仍然會咬人的坑。
- 2026-06-04[Benchmark] Gemma 4 12B omni 上 DGX Spark:weight-only NVFP4 贏 W4A4,還保住多模態
我在 DGX Spark GB10 上量化 Google 新的 omni Gemma 4 12B。weight-only NVFP4 只要 7.7GB、跑 24.9 tok/s,而且圖片/語音/影片都還能用 —— 全 W4A4 反而沒比較快,還把多模態弄壞。
- 2026-06-01[Benchmark] NVFP4 W4A4 在 DGX Spark 上超車 FP8:拔掉 enforce-eager,MoE 從 23 衝到 67 tok/s
GB10 上 NVFP4 W4A4 拔掉 --enforce-eager 後從 23 衝到 67 tok/s,贏 FP8 29% 還省 16GB。Part 32 說 cudagraph 沒用——那只對 dense,MoE 完全相反。
- 2026-05-30[Benchmark] NVFP4 在 DGX Spark 比 FP8 快 1.5 倍——但贏在壓縮,不是那顆 FP4 運算單元
GB10 DGX Spark 上,純 dense 模型單流 decode,NVFP4 比 FP8 快約 1.5 倍。但快的是頻寬(權重檔變小),不是 FP4 tensor core——最快那條路根本沒碰它。
不想錯過新文章?
訂閱我確保不漏接!
隨時一鍵退訂。