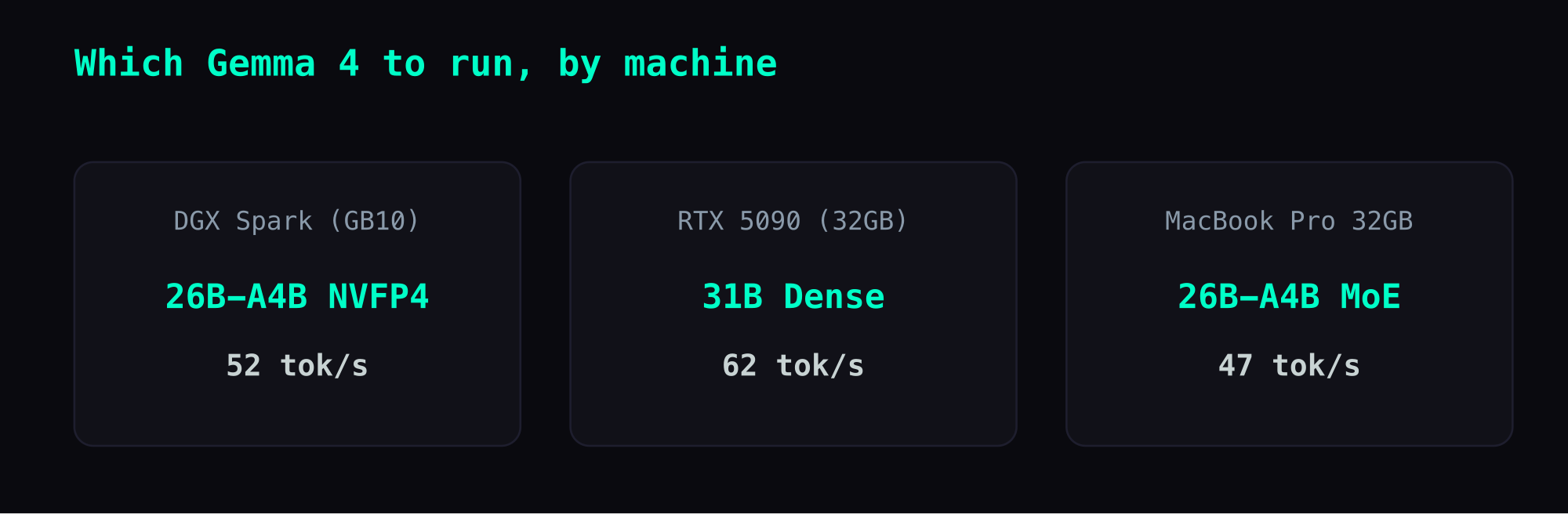
DGX Spark · part 14
[Benchmark] Gemma 4 on DGX Spark — Which Model Should You Pick?
❯ cat --toc
- The short version: four models, one table
- Full results across three machines
- DGX Spark (GB10) — 128 GB, 273 GB/s
- RTX 5090 — 32 GB GDDR7, 1792 GB/s
- MacBook Pro M1 Max — 32 GB, 400 GB/s
- How to Choose
- You have a DGX Spark
- You have an RTX 5090
- You have a MacBook Pro 32GB
- Why Not Dense?
- Quantization Format Guide
- Takeaways
- Further reading
TL;DR
Benchmarks of the four main Gemma 4 variants across three machines. 26B MoE NVFP4 on DGX Spark: 52 tok/s is the best bang for buck. 31B Dense is only 7 tok/s — skip it. MacBook Pro 32GB maxes out at 26B MoE (47 tok/s). RTX 5090 is the only hardware where 31B Dense is the right pick (62 tok/s — fast enough to keep full capability).
Updated July 2026 — Still works: the per-machine picks (Spark → 26B-A4B NVFP4, 5090 → 31B dense, MBP → 26B MoE). Changed: Google shipped Gemma 4 12B Unified (2026-06-03, encoder-free multimodal; 256K context per its HF model card) — a new option beyond the original table; NVIDIA's official 26B NVFP4 weights are out now too. Current pick: unchanged for the covered variants; evaluate 12B Unified for long-context multimodal.
The short version: four models, one table
Gemma 4 is Google's 2026 open-source AI model family. The family spans several sizes; this guide covers the four most-used: E2B (phones), E4B (desktops), 26B (servers), and 31B (maximum capability). Google later added a 12B Unified variant too. The docs don't tell you how fast each one actually runs on your hardware.
This article puts all four variants on three machines into one table so you can decide without reading six separate articles.
Full results across three machines
DGX Spark (GB10) — 128 GB, 273 GB/s
| Model | Type | Active Params | Quant | Runtime | tok/s | Model Size | Rating |
|---|---|---|---|---|---|---|---|
| 26B-A4B | MoE | 4B | NVFP4 | vLLM | 52 | 16.5 GB | ⭐⭐⭐⭐⭐ |
| E4B | PLE | 4B | NVFP4 | vLLM | 50 | 9.8 GB | ⭐⭐⭐⭐ |
| E4B | PLE | 4B | FP8 | vLLM | 36 | ~14 GB | ⭐⭐⭐ |
| E2B | PLE | 2B | Q4_K_M | Ollama | 53 | 7.2 GB | ⭐⭐⭐ |
| E4B | PLE | 4B | BF16 | vLLM | 19 | ~18 GB | ⭐⭐ |
| 31B Dense | Dense | 31B | NVFP4 | vLLM | 7 | 31 GB | ❌ |
RTX 5090 — 32 GB GDDR7, 1792 GB/s
Rated by capability first — speed is a threshold, not a ranking. All four models clear the usability floor (~20 tok/s) on this hardware.
| Model | Quant | Runtime | tok/s | Active Params | Rating |
|---|---|---|---|---|---|
| 31B Dense | Q4_K_M | Ollama | 62 | 31B | ⭐⭐⭐⭐⭐ |
| 26B MoE | Q4_K_M | Ollama | 186 | 4B | ⭐⭐⭐⭐⭐ |
| E4B | Q4_K_M | Ollama | 202 | 4B | ⭐⭐⭐⭐ |
| E2B | Q4_K_M | Ollama | 310 | 2B | ⭐⭐⭐ |
MacBook Pro M1 Max — 32 GB, 400 GB/s
| Model | Quant | Runtime | tok/s | Notes |
|---|---|---|---|---|
| E2B | Q4_K_M | Ollama | 81 | Fastest |
| 26B MoE | Q4_K_M | Ollama | 47 | Largest usable |
| 31B Dense | Q4_K_M | oMLX | 12.8 | Requires oMLX |
| 31B Dense | Q4_K_M | Ollama (ctx=2048) | 9 | Context cap required |
| 31B Dense | Q4_K_M | Ollama (default) | 1.5 | ❌ Swap death |
How to Choose
You have a DGX Spark
→ 26B-A4B NVFP4 + vLLM. 52 tok/s, model uses only 16 GB, leaving 82 GB for KV cache. Best capability + speed combination.
Full deployment guide: 26B NVFP4 Complete Guide
You have an RTX 5090
→ Default pick: 31B Dense (62 tok/s). On 5090's 1792 GB/s bus, the Dense model that's unusable elsewhere becomes the strongest option at a perfectly comfortable speed. No reason to drop capability when the hardware can handle it.
→ Need more speed: 26B MoE (186 tok/s) — still very capable, 3x faster. Good for high-throughput agent workloads where latency matters more than reasoning depth.
→ Need raw throughput: E2B (310 tok/s) — least capable but fastest. Only pick this for edge-like workloads or batch processing where speed dominates.
You have a MacBook Pro 32GB
→ 26B MoE (47 tok/s) is the largest usable variant. For 31B Dense, don't use Ollama defaults — it drops to 1.5 tok/s.
If you want to try 31B anyway: Rescuing 31B on 32GB MBP
Why Not Dense?
31B Dense on GB10: 7 tok/s. 26B MoE: 52 tok/s. Same hardware, 7.5x difference.
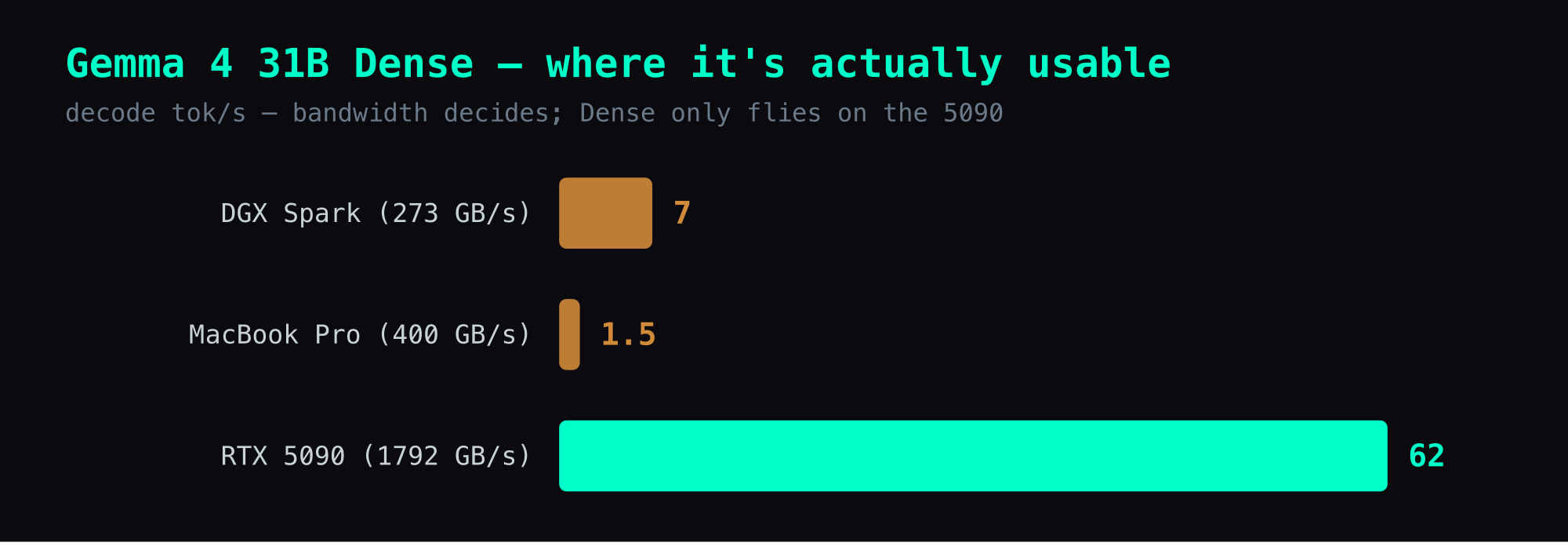
Dense models read all 31B parameters per token (62 GB at BF16). MoE activates only 4B per token (8 GB). On a 273 GB/s memory bus, that difference sets the ceiling.
If you have an RTX 5090 (1792 GB/s), 31B Dense at 62 tok/s is the top recommendation — capable enough to justify the speed, fast enough to feel responsive. On anything else, choose MoE.
Detailed math: 31B Dense Bandwidth Wall
Quantization Format Guide
| Format | Best For | Notes |
|---|---|---|
| NVFP4 | DGX Spark + vLLM | Fastest. E4B: 2.6x speedup. Needs --moe-backend marlin |
| FP8 | DGX Spark + vLLM | Middle ground. Slower than NVFP4 |
| Q4_K_M | Any + Ollama | Universal. Works everywhere |
| BF16 | Large VRAM only | Lossless but slowest |
Full E4B NVFP4 quantization walkthrough: World-First E4B NVFP4
Takeaways
The biggest time sink: not having a unified comparison table, which meant re-reading individual articles for every decision. This article exists to fix that.
The decision tree: Does it fit in memory? → Is bandwidth sufficient? → Is there a MoE variant at this size? → Is there an NVFP4 checkpoint?
The general rule: on bandwidth-limited hardware, always pick a sparse-activation architecture (MoE, or PLE-style dense models like E2B/E4B) over a fully dense one. Total parameter count doesn't matter — the parameters read per token decide the speed.
Further reading
Every data point has a full article behind it:
| Topic | Article |
|---|---|
| 26B NVFP4 deployment + 52 tok/s | Full guide |
| Why 31B Dense is so slow | Bandwidth wall |
| 31B on 32GB MacBook Pro | From 1.5 to 12.8 tok/s |
| 4 machines full comparison | Memory decides everything |
| E2B vs E4B on 3 machines | Bandwidth = speed |
| E4B NVFP4 quantization | From 19 to 50 tok/s |
| DGX Spark power diagnostic | 30W / 100W / overheating guide |
FAQ
- How many Gemma 4 variants are there and what is the difference?
- The family spans several sizes; the four benchmarked here are E2B (2.3B effective, phone/edge), E4B (4.5B effective, desktop), 26B-A4B (3.8B active, server), and 31B (30.7B params, largest but slowest). Google later added a 12B Unified variant too. E2B and E4B are dense models with PLE (Per-Layer Embedding) that reduces effective compute. Only 26B-A4B is genuine MoE (128 experts, top-8 routing). 31B is plain dense — it reads all parameters for every token.
- Which Gemma 4 variant runs fastest on DGX Spark?
- E2B on Ollama is nominally fastest at 53 tok/s, but it's the least capable. Among the strong variants, 26B-A4B MoE NVFP4 leads at 52 tok/s (vLLM), with E4B NVFP4 close behind at 49.9. 31B Dense is only 7 tok/s — not recommended.
- Can a MacBook Pro 32GB run Gemma 4?
- Up to 26B MoE (47 tok/s). 31B Dense will drop to 1.5 tok/s because KV cache exceeds memory and triggers swap. Reducing context window to 2048 gets 9 tok/s, oMLX gets 12.8 tok/s. Recommend E4B or 26B MoE.
- Which quantization format is best?
- On DGX Spark with vLLM: NVFP4 is fastest (E4B goes from 19 to 50 tok/s, 2.6x improvement). On Mac/consumer GPUs with Ollama: Q4_K_M is the only option. FP8 is a middle ground (E4B 36 tok/s) but not worth it over NVFP4.
- Is the DGX Spark worth $4,699 in 2026?
- For Gemma 4 specifically: 26B MoE NVFP4 at 52 tok/s using only 16 GB of the 128 GB available — yes, if you plan to run multiple models or 100B+ models. For a single model under 32 GB, an RTX 5090 runs the same 26B MoE at 186 tok/s (3.6x faster). The DGX Spark wins on capacity and the ability to run models that don't fit anywhere else.
- DGX Spark vs RTX 5090 for Gemma 4 — which is better?
- RTX 5090 is faster on every Gemma 4 variant (E2B 310 vs 53, 26B MoE 186 vs 52 tok/s). But RTX 5090 can't run models over 32 GB. On RTX 5090, 31B Dense at 62 tok/s is the strongest responsive option. On DGX Spark, 26B MoE NVFP4 at 52 tok/s is the best balance because 31B Dense hits only 7 tok/s (bandwidth-limited).
Read next
- 2026-04-13[DGX Spark] From Unboxing to Running: Complete Deployment Guide
Everything you need to go from a sealed DGX Spark box to serving your first local LLM. Hardware check, Ollama quickstart, vLLM production setup, model selection, and the 5 gotchas that cost hours.
- 2026-04-05[Benchmark] vLLM vs Ollama on the Same Model: Why 30% Faster on GB10
Same Gemma 4 26B-A4B, same GPU, 30% speed gap. vLLM NVFP4 hits 52 tok/s while Ollama Q4_K_M tops at 40. Root cause: Marlin kernels, CUDA graphs, and an Ollama CPU/GPU split trap.
- 2026-04-05Gemma 4 26B-A4B on DGX Spark: 52 tok/s with NVFP4, skip the 31B
Gemma 4 26B-A4B + NVFP4 hits 52 tok/s on DGX Spark (GB10) — 7.5× faster than the 31B dense, in 16.5 GB with 82 GB free for KV cache. Plus the vLLM 0.19 marlin/patch gotchas that make it work.
- 2026-07-07DGX Spark in 2026: What Still Works, What Broke, and What I'd Run Today
A current 2026 guide to running local AI on DGX Spark: vLLM, official Gemma 4 NVFP4 weights, MTP, long-context multimodal options, and the traps still worth avoiding.
Don't miss the next one
Subscribe, and you won't.
One-click unsubscribe anytime.