從 0 開始的 AI Agent 生活 · part 9
[Agent 進階 #9] 讓你的 AI 助理看得到、聽得到:幫文字腦接上眼睛跟耳朵
❯ cat --toc
TL;DR
你的 AI 助理只會讀文字——但它可以長出眼睛跟耳朵。做法不是把腦換成更貴的多模態大模型,是外掛一顆會看圖的小模型當「感知小幫手」:圖進來 → 小模型轉成文字描述 → 餵給你原本的文字腦。Hermes 內建 auxiliary.vision(指一個會看圖的 endpoint 就好,不用自己寫外掛)+ 內建 faster-whisper(語音轉文字,預設就開)。實測:丟一張寫著「CAT 42 / risk HIGH」的圖給一顆純文字的 284B 本地腦,它 OCR 全中、連黑字紅字都讀到、用繁體回我。而那顆眼睛跑在一張 2014 年的 GTX 970 上。
白話導讀:文字 AI 怎麼「長出」眼睛跟耳朵
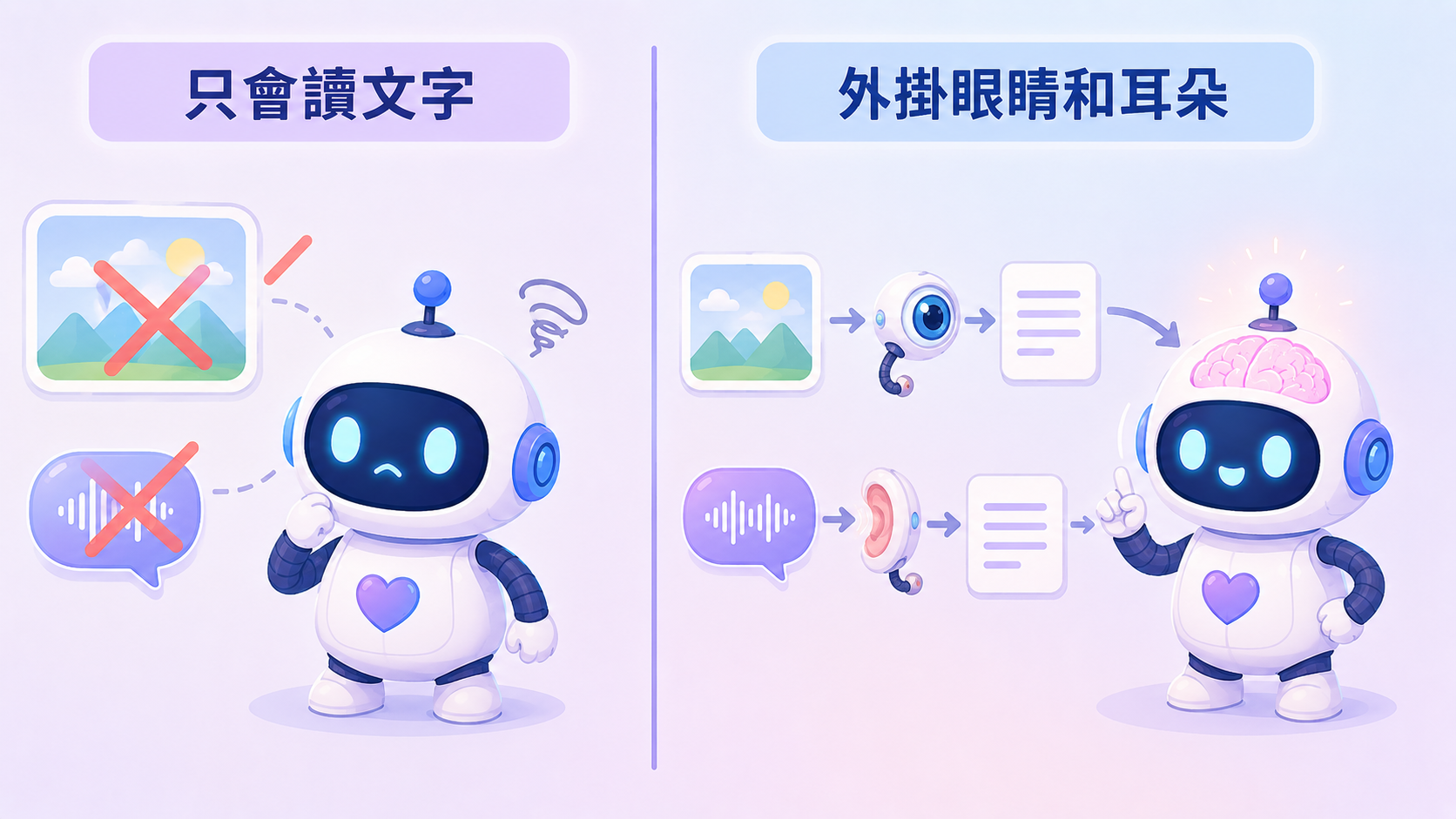
前面 #1–#7 你已經把助理裝起來、接上 LINE、會自己跑任務了。但它到現在還是個「只認得字」的助理——你貼一張截圖、傳一段語音,它完全看不到、也聽不到。
這篇要補上那塊:讓它看得到、聽得到。
重點是觀念上的一個轉彎。你直覺會想「那我得換一顆會看圖的模型吧?」——不用。會看圖的多模態大模型又大又貴,而且你原本那顆腦其實很好用。正確的做法是分工:原本的文字腦繼續當大腦,旁邊外掛一顆小小的、專門負責「看」的模型當眼睛。圖片先丟給眼睛、轉成一句「這張圖裡有什麼」,再把那句話交給大腦。大腦從頭到尾都只在讀文字,它根本不知道自己其實在看圖。
耳朵也一樣:語音先轉成文字,再照常處理。而且耳朵 Hermes 早就內建了,你可能根本沒發現。
前言
入門那七篇把助理養起來了;從這篇開始是進階軌——玩的東西更進階一點,但我會一樣盡量講到你聽得懂(這系列的重點一直是「好懂」,不是「秀肌肉」)。
第一篇就挑最有感的:感知。一個會看會聽的助理,跟一個只會讀字的助理,是兩種體驗。而且做法意外地省——省到我把「眼睛」塞進一張十一年前的顯示卡裡還有剩。
⚠️ 先確認這篇適不適用你。 這套主要是給純文字主腦(像我這顆 ds4)用的:
- 看圖:如果你的主腦本來就會看圖(像入門 #4 用的 ChatGPT 就是多模態的),那你不用設這個看圖小幫手——圖直接丟給它就行。這顆小幫手是用來幫「看不到圖的純文字腦」補眼睛的。
- 聽語音:這個不分主腦。Hermes 的語音輸入一律先用內建 faster-whisper 轉成文字再進對話(agent 流程本來就吃文字),而且它免費、內建、預設就開——留著就好,沒什麼好省的。
核心觀念:文字腦 + 感知小幫手,不是換腦
先把架構講清楚,後面 config 才看得懂。
你的助理有一顆主腦(我這裡是 ds4,一顆 284B 的本地模型,純文字)。它負責推理、決定、回話。它看不到圖,也聽不到聲音——這是它的天生限制,不是 bug。
與其把這顆好用的腦換掉,不如在旁邊掛感知小幫手:
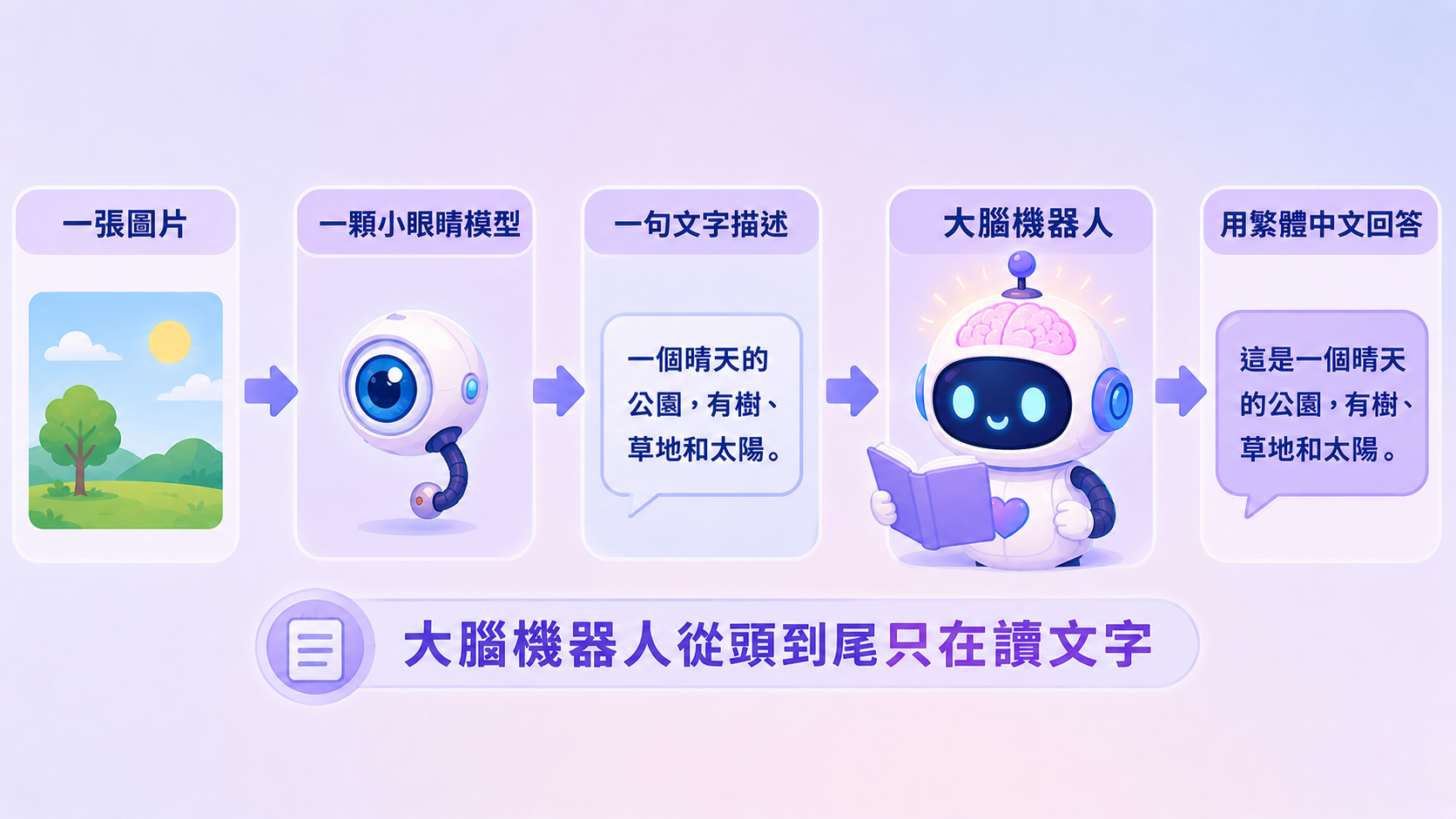
- 眼睛 = 一顆會看圖的小模型(Gemma 4 E2B + 視覺投影層)。任務只有一個:把圖變成一段文字描述。
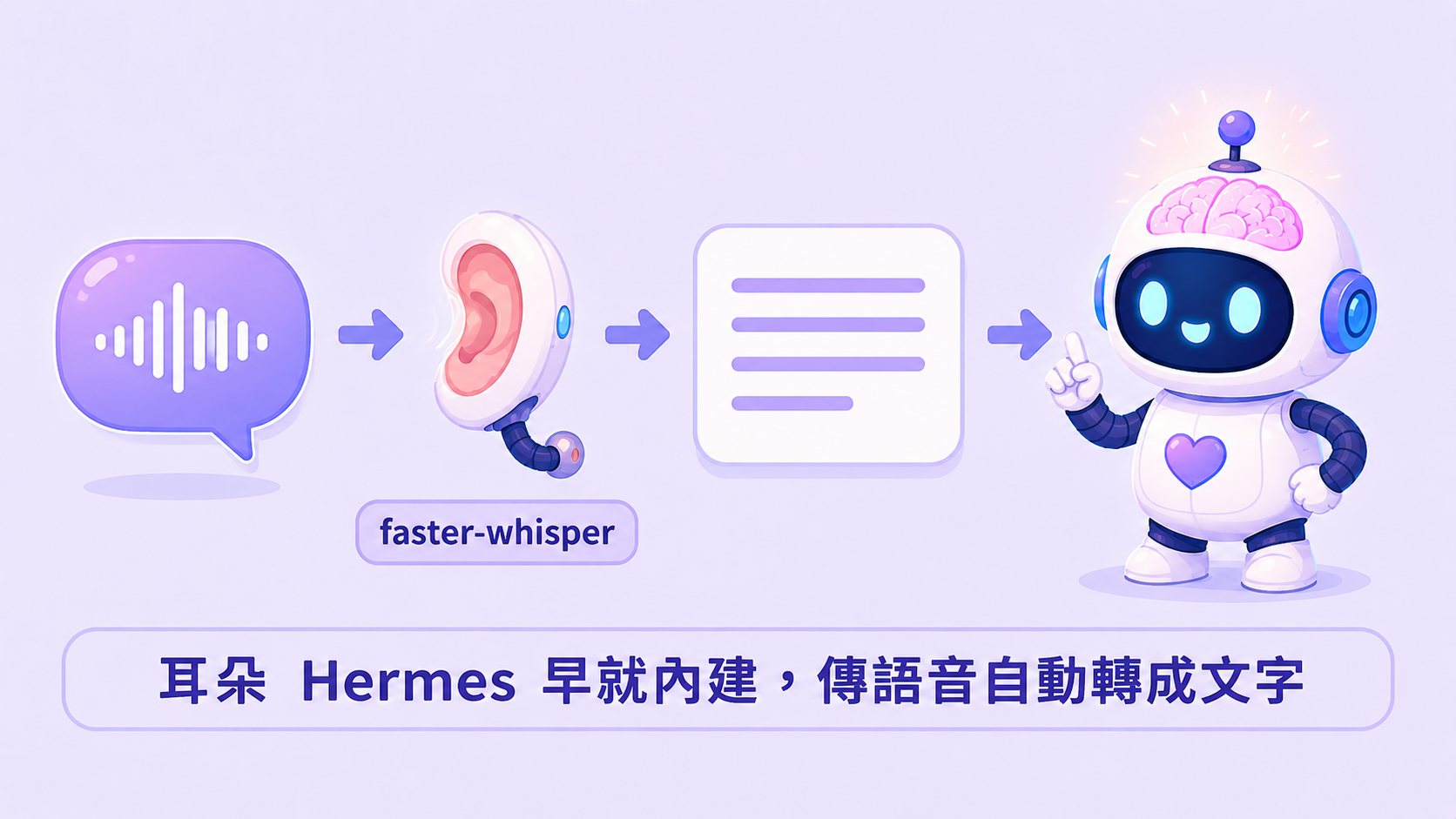
- 耳朵 = 一個語音轉文字引擎(faster-whisper)。任務只有一個:把聲音變成文字。
圖跟聲音都在「進到主腦之前」就被翻譯成文字了。主腦永遠在它的舒適圈(讀文字)裡工作,卻表現得像它會看會聽。這就是小幫手的全部精神:感知外包,推理留在主腦。
看圖:用 Hermes 內建的 auxiliary.vision,不要自己寫外掛
Hermes 內建一個 auxiliary.vision——你只要告訴它「會看圖的 endpoint 在哪」,它收到帶圖的訊息就自動把圖送過去取描述、接回對話裡。設定大概長這樣(在你的 config.yaml):
auxiliary:
vision:
provider: auto # 指了下面的 base_url,auto 就會走「自訂 vision endpoint」
base_url: http://<你的-vision-endpoint>/v1
api_key: "" # 自架本地通常留空
model: gemma-4-E2B-QAT-Q4_0.gguf
extra_body:
max_tokens: 512 # 太小描述會被截斷成空白
那個 endpoint 就是一顆「有加裝看圖能力」的小模型 Gemma(啟動時多帶一個 --mmproj 視覺檔,它就會看圖了)——任何會看圖、又長得像 OpenAI API 的 server 都能接。設完重啟一下就生效。
⚠️ Hermes 官方把「vision 指到非官方(OpenRouter/Nous 以外)的 endpoint」標為 experimental——能動,但設完務必實際丟一張圖測一次確認有接到;壞掉就把
base_url清掉、provider留auto退回預設。
為什麼用內建的 auto-hook,不自己寫一個「看圖 skill」叫 agent 自己呼叫? 因為你的主腦是純文字的——它根本看不到那張圖,要它自己判斷「現在該呼叫看圖工具了」並不可靠(它在瞎猜)。讓 gateway 在訊息進來時就自動 hook,比讓一個看不見的 agent 自己決定穩太多。而且——沒在維護的自寫 skill 會變技術債,能用內建就用內建。
實測:一張「CAT 42 / risk HIGH」的圖,純文字腦讀得一清二楚
光講架構沒用,丟張圖試。我給它一張寫著 CAT 42 跟 risk HIGH 的圖(黑字一個、紅字一個):
- gateway 自動把圖 route 到那顆 Gemma 眼睛、取回描述
- ds4(純文字主腦)拿到描述、推理、用繁體回我
- 結果:數字
42對、CAT對、risk HIGH對,連「哪個字是黑的、哪個是紅的」都讀到了 - 端到端約 1 分 48 秒(眼睛看圖 ~12 秒 + 那顆 284B 本來就慢的 decode)
一顆從設計上就「看不到」的模型,準確地描述了一張它技術上看不到的圖。靠的全是旁邊那顆小幫手。

聽:你的 Hermes 可能早就會聽了,只是你沒發現
語音這塊更省,因為 Hermes 內建 faster-whisper,而且預設就開。你大概從來沒設定過它——因為不用。
stt:
enabled: true # 預設就是 true
第一次用到,它會自動把語音模型下載下來,之後你傳一段語音,它就先轉成文字、再照常丟進對話。我實測用 macOS 的 say 念一句中文 → 轉成 wav → faster-whisper 一秒多就轉出來,語言也自動判成中文。
簡體不是問題:最後回話的腦會用繁體重講
有個你會擔心的點:中間那兩顆小模型——Gemma 描述、Whisper 轉錄——可能吐簡體(「天氣」變「天气」之類),小模型偶爾也會聽錯一兩個字。
但這幾乎不影響你看到的結果,因為最後回話的是你的主腦。描述也好、轉錄也好,都只是丟給主腦的中間材料;主腦消化完,是用它自己的繁體重講一遍。中間簡體、繁體混著進去,出來還是乾淨的繁體。所以「把中間的小模型升級成更準的版本」是可有可無的優化,不是必須。
省到誇張:眼睛跑在一張 2014 年的顯示卡上
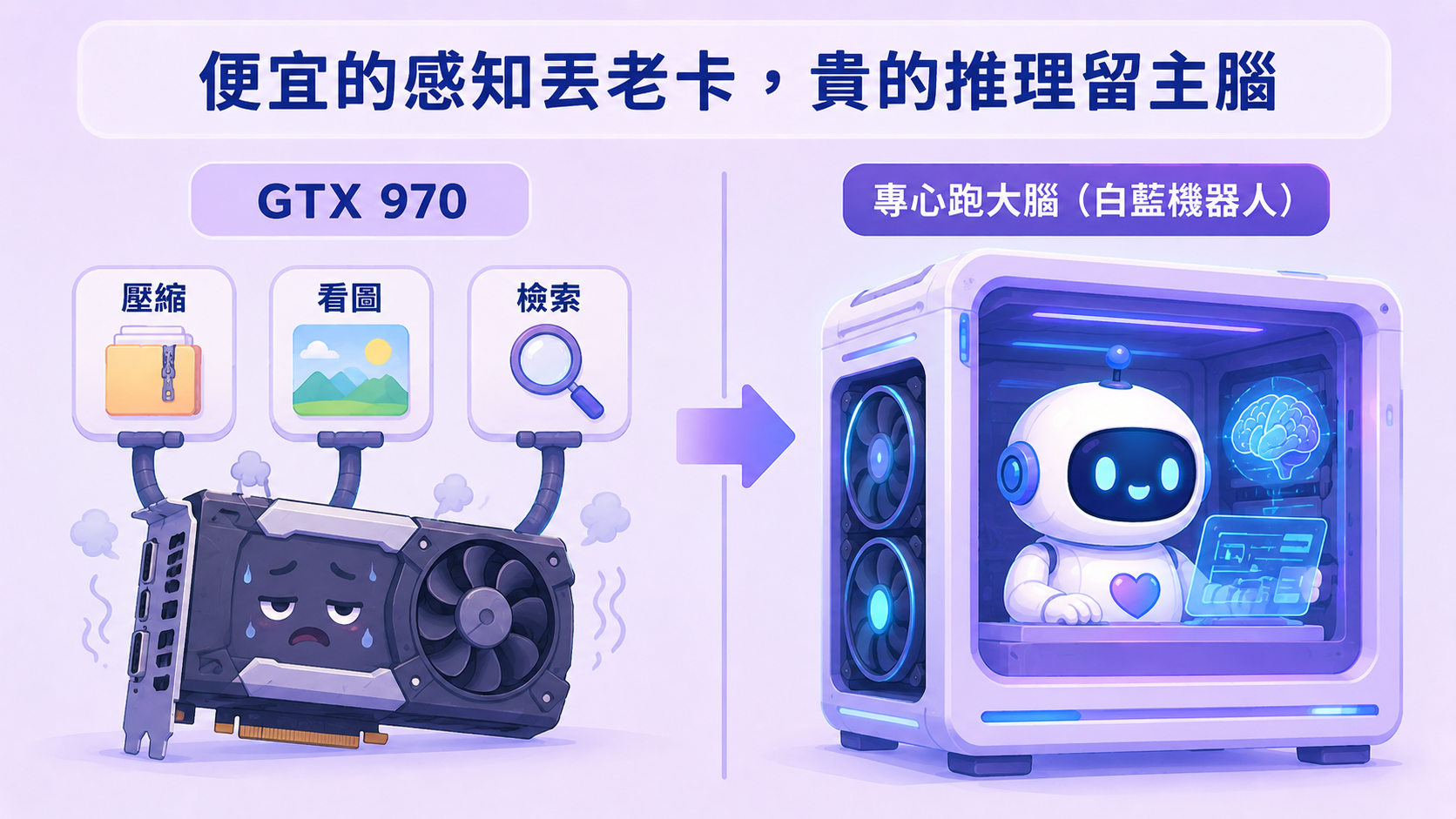
最後講硬體,因為這是整件事最爽的地方。那顆「眼睛」——Gemma + 視覺投影層——我跑在一張 2014 年的 GTX 970(二手約台幣兩千) 上,而且同一張卡同時還在做別的事(幫主腦壓縮長對話)。
塞得下的關鍵是這顆模型很省記憶體:它只「仔細記」最近講的話,更早的只留個大概,所以就算讓它記很長的對話,也幾乎不佔顯卡的記憶體——一張 4GB 的老卡才同時裝得下「壓縮 + 看圖」兩份工。(為什麼這樣就省、省多少,我在 GTX 970 系列裡拆得更白。)
分工的好處在這裡收斂成一句話:「便宜但要一直開著」的感知工作,丟給快變電子垃圾的老卡;貴的推理留給主腦。 你不需要一台新機器才能讓助理看見世界。
最花時間的不是接 vision,是想通「不要自己寫看圖 skill」
我一開始想得很自然:寫一個看圖工具、讓 agent 想看圖時自己呼叫就好。但卡在一個死結——主腦看不到圖,它根本沒有可靠的訊號去決定「現在該看了」,等於叫一個盲人自己判斷桌上有沒有照片。換成 gateway 一收到訊息就 auto-hook,這問題直接消失。所以這裡有個之後很多地方都用得到的判斷:感知這種事,要在 agent 動腦之前就先發生,不能交給看不見的 agent 自己決定。
順手再記幾個可以搬走的:要讓文字模型多模態,先問「能不能外掛感知小幫手」,再想「要不要換多模態大模型」——小幫手便宜、可拆、不動你原本的腦。能用框架內建的(auxiliary.vision、內建 STT)就別自寫 skill,自寫的沒人維護就變技術債。中間環節吐簡體或聽錯一兩個字不用慌,只要最後回話的腦夠好,它會用乾淨繁體重講一遍;力氣花在主腦,不是中間那一層。
說穿了就一句:多模態不一定要一顆會看會聽的大腦,可以是一顆會想的腦 + 幾顆會感知的小器官。 把「感知」跟「推理」拆開,你就能用最便宜的硬體做感知、把好模型留給該用腦的地方——這也是為什麼一張 2014 年的卡,能當一顆 2026 年大腦的眼睛。
結論
- 文字助理長眼睛:Hermes
auxiliary.vision指一個--mmproj的 Gemma endpoint,gateway 自動 hook,主腦不用懂圖。 - 長耳朵:faster-whisper 內建、預設開,傳語音自動轉文字。
- 中間吐簡體沒差,主腦用繁體重講。
- 眼睛可以很便宜:SWA 讓 64K context 不吃VRAM,一張 4GB 老卡同時扛壓縮 + 看圖。
- ⚠️ 誠實提醒:4GB 卡載完只剩 ~142MB VRAM餘量,桌面一波動可能 OOM,長期 production 要壓力測;語音轉錄偶有小錯(不影響最終繁體輸出)。
📱 出門也想用它?這個助理能裝進手機 我做了一支 iOS app「Muninn」:家裡的桌面 agent 架好後,手機掃個 QR 就能在外面 5G 直連它,中間不繞任何第三方伺服器。到 muninn.chat 看介紹、直接裝。
同系列:
- 入門 #1–#7:從「助理是什麼」到「裝起來、接 LINE、自動跑任務」
- 硬體那一面:Gemma 4 on a GTX 970 系列——這顆眼睛跑在什麼卡上、為什麼塞得下
常見問題
- 純文字的 AI 模型怎麼看得懂圖片?
- 它本身看不到。做法是外掛一顆會看圖的小模型當「眼睛」,把圖轉成一段文字描述,再餵給你原本的文字腦。Hermes 有內建的 auxiliary.vision,你只要指一個會看圖的 endpoint,它收到圖就自動轉描述、接進對話,你不用自己寫任何外掛。
- 要讓 Hermes 助理聽得懂語音,要另外裝什麼嗎?
- 幾乎不用。Hermes 內建 faster-whisper(語音轉文字),預設就開著、模型第一次用會自動下載。你傳一段語音,它就先轉成文字再照常處理。
- 看圖、聽語音會不會吐簡體中文?
- 中間那顆小模型(Gemma 看圖、Whisper 轉錄)可能吐簡體,但最後回你話的是你的主腦,它會用繁體重講一遍,所以你看到的還是繁體。中間簡體不影響結果。
- 跑這些要很貴的 GPU 嗎?
- 不用。我把「眼睛」跑在一張 2014 年的 GTX 970(二手約台幣兩千)上,同一張卡同時做文字壓縮 + 看圖。關鍵是 sliding-window attention 讓長 context 幾乎不吃VRAM。
接著讀
- 2026-07-01[Agent 進階 #17] Hermes 的 /learn:讓一隻本地 27B 把「做過的事」自己寫成可重用技能
Hermes 有個叫 /learn 的指令,能把『你做過的事』自動整理成一份可重用技能(一份 SKILL.md)。這篇我把它接上自己的艦隊實測:派一張 Kanban 卡,讓一隻跑在改裝 2080 Ti 上的本地 27B 模型,3 分鐘把一次遊戲開發蒸餾成一份合格技能——還挖到兩個文件沒講清楚、實作才會踩到的細節:斜線指令 vs 派工、技能到底存哪。白話講 /learn 是什麼、怎麼用、以及它的真實限制。
- 2026-06-19[Agent 進階 #11] 把助理的腦換成你家機器上的:從雲端 ChatGPT 換成本地模型
前面我們用 ChatGPT 當助理的大腦。這篇做一件更狠的事——把那顆腦從雲端換成跑在你自己機器上的本地模型(例如 ds4)。賣點是「腦」這塊整套自主:推論不靠雲端、你跟它講的話不出門、不限額、全在你手上。代價也誠實講:本地腦通常較慢(ds4 實測約 10 tok/s),而且要一台夠力的機器。換腦不換身體,Hermes 這副身體完全不動。
- 2026-07-21[Agent 進階 #18] 給你的 Hermes 做一次設定健檢:五個沒人細講、但你一定會撞的雷
第 13 篇說助理發瘋八成是「車子」壞了不是「引擎」笨。這篇就給你那張健檢表:context_length 設錯層會無聲提早壓縮、Qwen 沒關 thinking 慢 10 倍、MCP 工具接了卻全部失敗、sib 跑的模型跟你以為的不一樣。五個真實設定雷,每個都附一條你可以丟給 agent 自己跑的檢查跟修法。
- 2026-06-29[Agent 進階 #16] 同一份規格,丟給三隻分身各寫一個俄羅斯方塊:Hermes 看板派工實測
養了一群分身之後,我把同一份「做個俄羅斯方塊」的規格——就一句話、細節啥都沒講——一隻分身發一張卡,讓三隻各自一次寫完一個網頁俄羅斯方塊。我一行遊戲碼都沒碰,只負責發布。結果蹦出個意外驚喜:靠 Hermes 這套外框加一顆我自己在家調、跑在改裝 2080Ti 上的小模型,居然一次就把我沒要求的 ghost、wall-kick 都補上了。成品點開就能玩。
不想錯過新文章?
訂閱我確保不漏接!
隨時一鍵退訂。