DGX Spark · part 26
[vLLM] Watching English Videos with DGX Spark: Nemotron Omni Multimodal on GB10
❯ cat --toc
- Plain-Language Version: how a $3000 desktop watches videos for you
- Preface
- The 19-second video that exposed the audio trap
- The 3-minute Karpathy talk: scaling up
- What's inside the box
- The other trap: don't use the b12x image
- Mamba block_size assertion: a launch-time gotcha
- How long a video can fit?
- The working recipe
- Takeaways
- Transferable patterns
- Universal pattern
- Conclusion
TL;DR
Same DGX Spark hardware that hit 74.75 tok/s on text in Part 25 can also watch English videos. Nemotron-3-Nano-Omni-30B-A3B transcribed Jawed Karim's 19-second "Me at the zoo" in 15 seconds wall and the first 3 minutes of Andrej Karpathy's LLM talk in 89 seconds wall with 53,842 prompt tokens, both factually correct. Two traps got me first: use_audio_in_video must go at the top level of the request (not inside video_url), and the b12x-patched image breaks Omni's modelopt_mixed dispatch with NaN logits — fix is the upstream vllm/vllm-openai:v0.20.0 image. Recipe at the end.
Plain-Language Version: how a $3000 desktop watches videos for you
DGX Spark is a small desktop computer that runs AI models locally. Until now I'd been using it for text — chat, code, the usual. But the same chip can also process video and audio if you load a multimodal model. NVIDIA released one called Nemotron-3-Nano-Omni-30B-A3B that bundles three things: a vision encoder for video frames, a Parakeet speech encoder for audio, and a 30B-A3B language model that fuses them (NVIDIA's card lists ~31B total params, with 3B active per token in the MoE).
The use case I cared about: I find an English YouTube video, a podcast clip, a conference talk — and I want the model to watch it, listen to it, and write me a summary. Not just transcription, not just visual captioning, but the actual fused understanding of what was said and what was shown.
This article is the working setup. Two traps cost me an evening, the third is a knob you turn for video length. The numbers come from the test runs.
Preface
Part 25 was about pushing single-stream text throughput to 74.75 tok/s on a 30B parameter model. Different goal here — multimodal correctness, not raw speed. Throughput stops being the headline once your bottleneck is "did the model hear what was said."
The traps in this piece are config-level, not architectural. The model works. The vLLM serving layer works. But two flag placements decide whether you get real audio understanding or a confident hallucination — and they're both undocumented in the model card example I started from.
The 19-second video that exposed the audio trap
The first video I sent was the famous "Me at the zoo" — Jawed Karim, 19 seconds, the first video ever uploaded to YouTube in 2005. Public, short, has clear English narration.
Jawed Karim, 'Me at the zoo' (April 23, 2005) — first YouTube upload, 19 seconds.
The model's first response described the visuals perfectly — young man in blue shirt and red-grey jacket, two elephants, hay, fence. But the transcription it returned was:
"I'm here at the San Diego Zoo. And I'm going to show you some elephants. There are three of them. One is eating hay..."
That's a hallucination. YouTube's English caption track for the clip says:
"Alright, so here we are in front of the elephants. The cool thing about these guys is that they have really, really, really long trunks. And that's, that's cool. And that's pretty much all there is to say."
San Diego Zoo isn't mentioned. There aren't three elephants. The model wasn't listening — it was inferring plausible commentary from the visual scene. Because the visual was correct, it took me a beat to realize what was happening.
The fix lives in vLLM's chat parser, chat_utils.py:910:
# Extract audio from video if use_audio_in_video is True
if (
video_url
and self._mm_processor_kwargs
and self._mm_processor_kwargs.get("use_audio_in_video", False)
):
audio = self._connector.fetch_audio(video_url) if video_url else None
audio_placeholder = self._tracker.add("audio", (audio, uuid))
self._add_placeholder("audio", audio_placeholder)
Without that flag, vLLM never extracts the audio track from the video and never feeds it to the Parakeet encoder. The model gets video frames only and is forced to guess what the speaker said.
The flag belongs at the top level of the chat completion request, not inside the video_url object:
{
"model": "nemotron-omni",
"mm_processor_kwargs": {"use_audio_in_video": true},
"messages": [{
"role": "user",
"content": [
{"type": "video_url", "video_url": {"url": "data:video/mp4;base64,..."}},
{"type": "text", "text": "Transcribe the audio. Then describe the scene."}
]
}]
}
With the flag at the root, the second run produced:
"Alright, so here we are, one of the uh elephants. Um, cool thing about these guys is that they have really, really, really long um trunks. And that's that's cool. And that's pretty much all there is to say."
Substantially correct — same elephants framing, same "really, really, really long trunks" anchor, same closing. Slight ASR drift ("one of the uh" vs "in front of the") and extra "um" hesitations, but the meaning is preserved. 15 seconds wall, 5,637 prompt tokens, 689 completion tokens.
The 3-minute Karpathy talk: scaling up
Once the flag was right, the next question was how long a video the box could handle. I downloaded the first 3 minutes of Andrej Karpathy's "Intro to Large Language Models" — talking head, slide-driven, dense technical content.
Andrej Karpathy, 'The busy person's intro to LLMs' — tested on the first 3 minutes.
The model's output (paraphrased structure, the actual content was timestamped):
Andrej Karpathy introduces himself, mentions an earlier 30-minute LLM talk that wasn't recorded so he's re-recording it for YouTube. Title slide reads "The busy person's intro to LLMs". The slide changes to show a
llama-2-70bdirectory with two files:parameters(140GB) andrun.c(~500 lines of C). He explains the parameters file is 140GB because it's a 70-billion-parameter model with each parameter stored as 2-byte float16. The C file has no dependencies — you compile it into a binary, copy the parameters file, and you have a working LLM on a MacBook with no internet.
Every fact is correct. llama-2-70b, the 140 GB number, the ~500-line run.c, the MacBook framing — all match Karpathy's actual content. The output was a paraphrase rather than a verbatim transcript, but the model preserved the technical claims.
| Metric | Value |
|---|---|
| Video duration | 180 seconds (3 minutes) |
| Wall time | 89 seconds |
| Prompt tokens | 53,842 |
| Completion tokens | 2,000 (capped at max_tokens) |
| Effective rate | ~300 prompt tokens per second of video |
The 300 prompt-tokens-per-video-second figure is consistent across both clips and is the number you use to plan longer videos.
What's inside the box
Quick architectural sketch of what handled the video, so the rest of this article (b12x dispatch incompatibility, Mamba assertion, audio token math) lands in context:
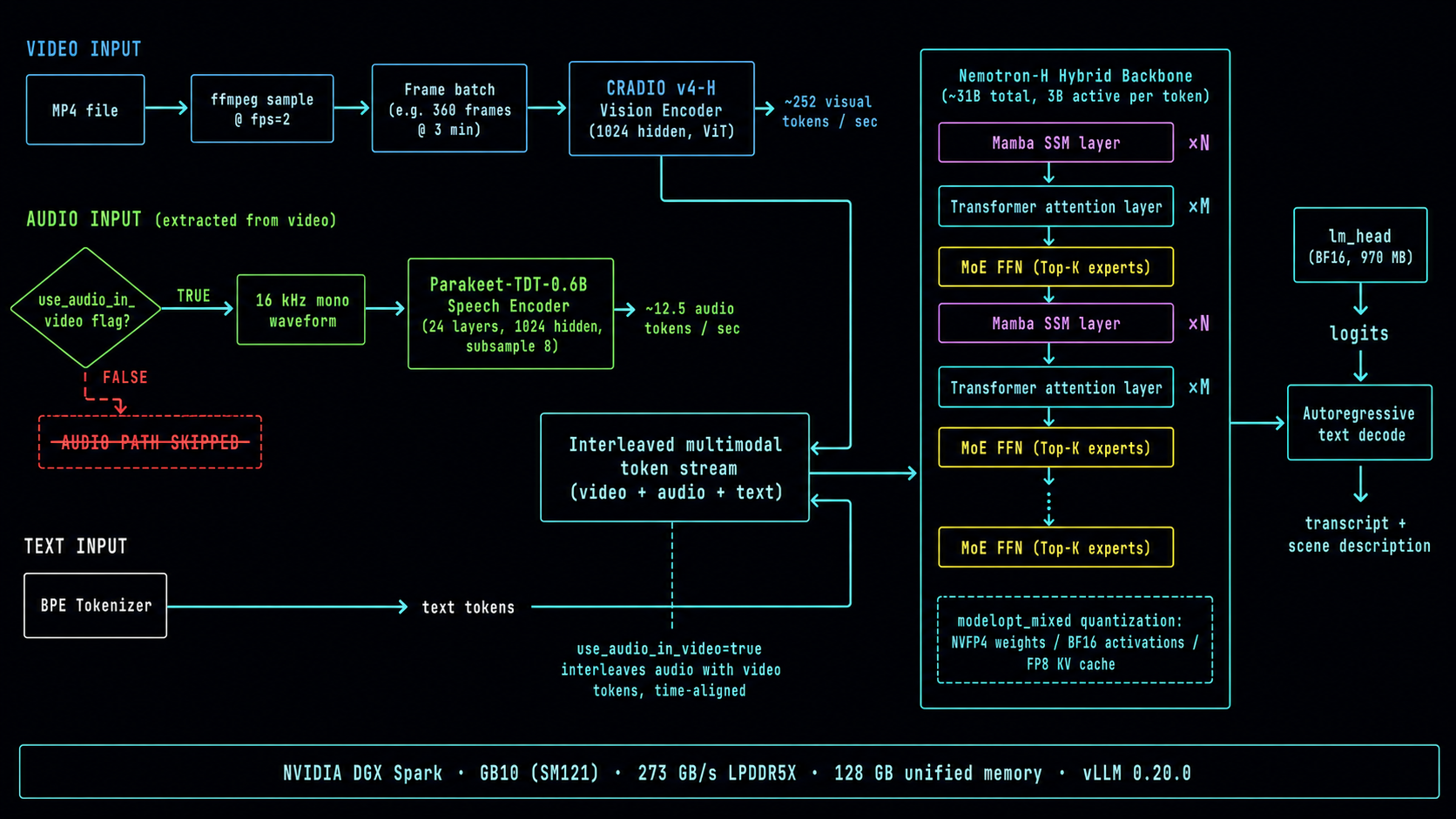
Three things on this diagram drive the rest of the article:
- The
use_audio_in_videoflag literally gates whether the Parakeet path runs. Wrong flag placement → entire green lane skipped → model hallucinates audio from frames. - Mamba SSM layers in the backbone are why the upstream image hits the
block_size (2128) must be <= max_num_batched_tokensassertion at boot — Nemotron-H is hybrid, not pure transformer. modelopt_mixedquantization (NVFP4 weights / BF16 activations / FP8 KV cache, mixed across vision-audio-LLM) is what our b12x patches break. The patches assume one quant config; this model has three.
The other trap: don't use the b12x image
In Part 25 I built vllm-node-tf6-b12x — vLLM 0.20.1 with PR #40082 cherry-picked plus four SM121 patches. That image hit 74.75 tok/s on text. My first instinct was to run Omni on the same image.
It didn't work. First decode step produced NaN logits, output was !!!!!!!!!!!!, and the engine refused to recover. The vLLM startup log said the dispatch was:
Selected FlashInferFP8ScaledMMLinearKernel for ModelOptFp8LinearMethod
Omni uses modelopt_mixed quantization — vision and audio encoders in one precision, the LLM body in another. Our SM121 patches changed the FP8 GEMM kernel selection in a way that's wrong for that mixed config. I didn't trace it to the patched source line, because the pragmatic fix was simpler: use the upstream image.
docker run -d --name vllm_upstream --gpus all --network host --ipc=host \
--shm-size 16g \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--entrypoint /bin/bash \
vllm/vllm-openai:v0.20.0 \
/tmp/launch-upstream-omni.sh
The upstream vllm/vllm-openai:v0.20.0 doesn't have our patches and hits the standard kernel selection path that Omni was tested against. Same hardware, same model, two different images for two different jobs.
This isn't a permanent split. It says: when our patched image is wrong for a model, ship the model on a separate stock-image container. Trying to make one image cover everything is the usual integration mistake.
Mamba block_size assertion: a launch-time gotcha
First boot of the upstream image with --max-model-len 65536 died at engine init:
AssertionError: In Mamba cache align mode,
block_size (2128) must be <= max_num_batched_tokens (2048).
Nemotron-3 is a hybrid architecture with Mamba/SSM layers. The Mamba KV cache uses a block size derived from the model config, and vLLM's default max_num_batched_tokens=2048 is smaller than that block size. The fix is one flag:
--max-num-batched-tokens 8192
Bumping the prefill batch budget makes the assertion pass. There's no perf tradeoff at our concurrency=1 workload — the flag controls the upper limit of how many tokens vLLM will batch together for prefill, and we never approach that limit with a single video request anyway.
How long a video can fit?
The math from the 3-minute Karpathy run gives a clean rule: ~300 prompt tokens per second of video at fps=2. The choke points are --max-model-len, num_frames, and the fps you sample at.
| Video length | fps | num_frames cap | max-model-len | Est. prompt tokens | Notes |
|---|---|---|---|---|---|
| 1 min | 2 | 128 | 32768 | ~18k | Default config works |
| 2 min | 2 | 256 | 32768 | ~36k | Bump max-model-len to 65536 |
| 3 min | 2 | 512 | 65536 | ~54k | What this article tested |
| 5 min | 1 | 300 | 65536 | ~45k | Half the visual detail; audio unchanged |
| 10 min | 0.5 | 300 | 98304 | ~45k | Quarter the visual detail; gestures/slides lost |
| >10 min | — | — | — | — | Chunk with ffmpeg, summarize per chunk, stitch |
Two trade-offs hide in this table:
fps↓ saves tokens without losing audio detail. Parakeet runs on the audio waveform at 16 kHz, independent of the video frame rate. The audio path produces about 12.5 audio tokens per second of clip regardless of fps. So lowering fps cuts visual token count and visual detail (gestures, slide changes) — but the speech transcription stays as good as the input audio. That's actually the win condition for long-form: drop fps to 0.5, keep the audio.
num_frames↑ + max-model-len↑ costs unified memory. GB10's 128 GB is shared between weights and KV cache. Doubling max-model-len doubles the KV cache budget. At the 98k context, you're using more than half the box's RAM for one in-flight video request.
For anything over 10 minutes I'd chunk in ffmpeg, run the model per chunk, and concatenate the per-chunk summaries with a small text-only LLM. Single-pass long-form is not the win condition for a $3,000 desktop.
The working recipe
spark-vllm-docker/recipes/nemotron-omni.yaml:
recipe_version: "1"
name: nemotron-omni
description: Nemotron-3-Nano-Omni multimodal (video+audio) on upstream vLLM 0.20.0
model: nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4
container: vllm/vllm-openai:v0.20.0
solo_only: true
defaults:
port: 8004
host: 0.0.0.0
gpu_memory_utilization: 0.80
max_model_len: 65536
max_num_seqs: 8
max_num_batched_tokens: 8192
command: |
pip install "vllm[audio]" --quiet && \
vllm serve nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4 \
--served-model-name nemotron-omni \
--trust-remote-code \
--gpu-memory-utilization {gpu_memory_utilization} \
--max-model-len {max_model_len} \
--max-num-seqs {max_num_seqs} \
--max-num-batched-tokens {max_num_batched_tokens} \
--kv-cache-dtype fp8 \
--reasoning-parser nemotron_v3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--limit-mm-per-prompt '{{"video":1,"image":1,"audio":1}}' \
--media-io-kwargs '{{"video":{{"fps":2,"num_frames":512}}}}' \
--enable-prefix-caching \
--host {host} \
--port {port}
Drop a 3-minute MP4 into /tmp/, base64-encode it, send the request with mm_processor_kwargs: {"use_audio_in_video": true} at the top level, and you get a transcribed-and-described answer in about 90 seconds.
Takeaways
Transferable patterns
1. When a multimodal model hallucinates, suspect the modality is silently dropped. A confident, scene-consistent transcription for audio you know the model can't have heard is the signature of a flag that was supposed to enable that modality but didn't. Grep the framework source for the flag name and confirm the gating condition was actually true.
2. One image rarely fits all models. Patches optimized for one model's kernel path can break another model's dispatch. When something breaks under your custom image, A/B against the upstream image before debugging the model — half the time the upstream just works.
3. Multimodal token budgets follow video duration, not text length. Plan for ~300 prompt tokens per second of video at fps=2 on Nemotron-3-Nano-Omni. The math is dominated by frame embeddings, not the text prompt around them.
Universal pattern
A single multimodal request on this box uses 50,000+ prompt tokens for 3 minutes of input. That's 5x the typical text-only chat request. KV cache and prefill batch budgets that you'd never think about for text become live constraints for video. If you're planning multi-tenant serving on this hardware, video tenants and text tenants need separate queues — they're not in the same throughput regime at all.
Conclusion
DGX Spark can watch English videos and tell you what was said. The recipe is:
- Use the upstream
vllm/vllm-openai:v0.20.0image, not a patched one. - Set
--max-num-batched-tokens 8192to clear the Mamba block-size assertion. - Set
--max-model-len 65536,num_frames=512,fps=2for videos up to ~4 minutes. - Always pass
mm_processor_kwargs: {"use_audio_in_video": true}at the top level of the chat request — without it, audio is silently dropped. - For >5-minute videos, lower fps — Parakeet runs at 16 kHz independent of fps, so audio quality stays intact. For >10-minute, chunk in ffmpeg.
The same DGX Spark from Part 25 hits 74.75 tok/s on text and now also handles 3-minute video in 90 seconds. Two images, one box, two different jobs.
Also in this series:
- Part 25: Nemotron 3 Nano on DGX Spark — 74.75 tok/s NVFP4 — text throughput on the same hardware
- Part 7: Gemma 4 26B NVFP4 — 52 tok/s — earlier benchmark on the same box
FAQ
- Can DGX Spark watch a YouTube video and tell me what was said?
- Yes. Nemotron-3-Nano-Omni-30B-A3B on DGX Spark transcribed a 19-second clip in 15 seconds wall and a 3-minute talk in 89 seconds, with both the spoken audio and visual scene reported correctly. Two configuration traps must be avoided: the use_audio_in_video flag goes at the top level of the request (not inside video_url), and you must use the upstream vLLM image — our b12x-patched stack feeds Omni's modelopt_mixed dispatch NaN logits.
- Why does the model hallucinate audio when I send a video?
- Because vLLM only runs the Parakeet speech encoder when use_audio_in_video=true is in the top-level mm_processor_kwargs of the chat completion request. Putting the flag inside the video_url object silently no-ops, and the language model then synthesizes plausible-sounding audio from the visual frames alone. The fix is to move the flag to the request root.
- What's the longest video Nemotron Omni can handle on GB10?
- About 3-4 minutes at fps=2 with max_model_len=65536 (~300 prompt tokens per second of video, including audio). For 5-10 minute videos drop fps to 1 or 0.5. For >10 minute videos, chunk with ffmpeg and stitch summaries — single-pass context exhausts before then.
- Why not use the same b12x image as the 74 tok/s W4A16 setup?
- Omni uses modelopt_mixed quantization (mixed precision across vision/audio/text components), and our b12x patches break the FlashInferFP8ScaledMMLinearKernel dispatch path for that mixed config. The result is NaN logits at the first decode step. The pragmatic fix is the upstream vllm/vllm-openai:v0.20.0 image, which doesn't have our patches and works out of the box for Omni.
Read next
- 2026-06-04[Benchmark] Gemma 4 12B Omni on DGX Spark: Weight-Only NVFP4 Beats W4A4 (and Keeps Multimodal)
I quantized Google's new omni Gemma 4 12B on a DGX Spark GB10. Weight-only NVFP4 hits 24.9 tok/s in 7.7 GB and keeps image/audio/video working — full W4A4 is slower AND breaks multimodal.
- 2026-07-07DGX Spark in 2026: What Still Works, What Broke, and What I'd Run Today
A current 2026 guide to running local AI on DGX Spark: vLLM, official Gemma 4 NVFP4 weights, MTP, long-context multimodal options, and the traps still worth avoiding.
- 2026-06-13[vLLM] DiffusionGemma 26B NVFP4 on a DGX Spark: 158 tok/s, and why diffusion tok/s lies
DiffusionGemma 26B-A4B runs on vLLM on a 128GB DGX Spark via an official prebuilt image — no PR-waiting, no cherry-picking. NVFP4 hits 158 tok/s single-stream and 257 aggregate. But a single tok/s number lies: diffusion speed is decided by whether the 256-token canvas fills.
- 2026-06-01[Benchmark] NVFP4 W4A4 beats FP8 on a DGX Spark MoE: 67 vs 52 tok/s once CUDA graphs fire
On a GB10 DGX Spark, NVFP4 W4A4 went from 23 to 67 tok/s the moment I dropped --enforce-eager — beating FP8 by 29% and saving 16GB. The catch from Part 32 was real, just dense-only.
Don't miss the next one
Subscribe, and you won't.
One-click unsubscribe anytime.