DGX Spark · part 25
[vLLM] Nemotron 3 Nano on DGX Spark: 74.75 tok/s NVFP4 — 11.5% Past the Public Baseline
❯ cat --toc
- Plain-Language Version: Why a 4-bit number can run faster than an 8-bit number
- Preface
- The public baseline was 67 tok/s. We hit 74.75 — same hardware, different image
- The 4-layer patch stack to enable b12x on SM121
- Qwen 3.6 capped at 44 tok/s — the bottleneck wasn't the kernel
- Switching to Nemotron 3 Nano: same A3B size, no GDN tax
- But wait — did 74.75 tok/s actually run NVFP4 compute?
- The MTP detour: 5 failures, 0 wins
- Takeaways
- Where the time went
- Reusable diagnostic patterns
- Universal pattern
- Conclusion
TL;DR
Nemotron 3 Nano 30B-A3B in W4A16 NVFP4 runs at 74.75 tok/s single-stream on DGX Spark, +11.5% past the public 67 tok/s forum baseline (eugr), and +57% past my own 47.6 tok/s FP8 hack from Part 20. The fix that closed the gap was a 4-layer software stack to enable b12x dispatch on SM121, plus picking the right model — Nemotron 3 is non-hybrid, so it dodges the BF16 GDN tax that capped Qwen 3.6 at 44 tok/s. We're now firmly in the bandwidth-bound regime for a 3.5B active-param model on 273 GB/s LPDDR5X.
Plain-Language Version: Why a 4-bit number can run faster than an 8-bit number
DGX Spark is a small AI computer that NVIDIA sells around US$3,000. It has a chip called GB10, and one big constraint: the memory bus moves data at 273 GB/s — about 1/12 the speed of a data-center H100. For local chat models, that memory speed is the whole game. The faster you can pull weights out of memory, the more tokens per second you generate.
NVFP4 packs each model weight into 4 bits — half of FP8's 8 bits. Theoretically, you should double the speed. But on DGX Spark's specific chip (SM121), the FP4 hardware path was broken in early vLLM builds. I wrote about that ten days ago in Part 19: NVFP4 was 32% slower than FP8.
Today the same hardware hits 74.75 tok/s on a 30B-parameter model in NVFP4. That's faster than my own FP8 ceiling, faster than the best public benchmark anyone has posted, and very close to the physical limit of how fast 273 GB/s can shuffle 4-bit weights. This article is the receipt: the patches, the model choice, the bench script, the dead-ends.
Preface
The trap was real. The trap was also surmountable. I just had to stop blaming the hardware and start reading vLLM source.
Part 19 declared NVFP4 a trap. Part 20 proposed a Triton FP8 dequant hack at 47.6 tok/s as the workaround. This is part 25, the reversal. The "trap" wasn't NVFP4. It was the combination of (a) hybrid SSM/Mamba models that hide BF16 layers in their decoder stack, (b) missing CUTLASS DSL patches for sm_121a that vLLM expected at runtime, and (c) using the wrong quantization variant for single-stream workloads.
This piece walks through the diagnostic chain that landed at 74.75 tok/s. Cherry-picking vLLM PR #40082 was step one. Patching cutlass-dsl and FlashInfer was step two. Picking the right model and W4A16 quant was step three. The bench script and timeline at the end.
The public baseline was 67 tok/s. We hit 74.75 — same hardware, different image
| Source | Image | Model | Single-stream tok/s |
|---|---|---|---|
| eugr (forum, Dec 2025) | avarok/vllm-dgx-spark:v11 | cybermotaz/nemotron3-nano-nvfp4-w4a16 | 67 |
| Spark Arena leaderboard | (various) | Nemotron-3-Nano-30B-A3B | 56.11 |
| This work (May 2026) | vllm-node-tf6-b12x (custom) | Same as eugr | 74.75 |
11.5% past the public best is a big enough delta to be worth explaining. The avarok image was shipped Jan 2026 with vLLM 0.14, before the b12x backend was available — and as of 2026-05-01, vLLM PR #40082 is still open. Our custom image is built on vLLM 0.20.1 with that PR cherry-picked into our local fork, plus the 4-layer SM121 patches that vLLM upstream still requires manually.
The 4-layer patch stack to enable b12x on SM121
CUTLASS PR #3082 was still open as of May 2026. The CUTLASS DSL warp/mma.py rejects anything that isn't sm_120a, even though the actual hardware features needed for FP4 MMA exist on sm_121a. Without the patches, the b12x kernel either refuses to dispatch or compiles broken PTX.
Layer 1 — install the CUDA-13 backing libraries (the default pip install nvidia-cutlass-dsl only pulls libs-base, missing the runtime libs for CUDA 13):
pip install --no-deps nvidia-cutlass-dsl-libs-cu13==4.4.2
Layer 2 — patch cutlass-dsl warp/mma.py to admit sm_121a. Both the visible list AND the base equality check:
# /usr/local/lib/python3.12/dist-packages/nvidia_cutlass_dsl/python_packages/cutlass/cute/nvgpu/warp/mma.py
# Before:
admissible_archs = ["sm_120a"]
if not arch == Arch.sm_120a:
raise OpError(...)
# After:
admissible_archs = ["sm_120a", "sm_121a"]
if arch not in (Arch.sm_120a, Arch.sm_121a):
raise OpError(...)
Layer 3 — patch FlashInfer's dense_blockscaled_gemm_sm120.py. The kernel hardcodes sm_version="sm_120" in two places, which the b12x dispatcher then rejects when running on SM121:
# /usr/local/lib/python3.12/dist-packages/flashinfer/gemm/kernels/dense_blockscaled_gemm_sm120.py
# Accept sm_121 family in the runtime check
if sm_version not in ("sm_120", "sm_120a", "sm_121", "sm_121a"):
raise ValueError(...)
# Pass through the env-controlled arch instead of hardcoding sm_120
sm_version=__import__("os").environ.get("CUTE_DSL_ARCH", "sm_120"),
Layer 4 — recipe env vars:
env:
CUTE_DSL_ARCH: sm_121a
VLLM_NVFP4_GEMM_BACKEND: flashinfer-b12x
VLLM_FLASHINFER_MOE_BACKEND: latency
After all four layers, vLLM logs confirm dispatch:
Using FlashInferB12xNvFp4LinearKernel for NVFP4 GEMM
The full mod ships as mods/sm121-b12x-full-enable/run.sh and runs once per container start.
Qwen 3.6 capped at 44 tok/s — the bottleneck wasn't the kernel
With the 4-layer patch in place, b12x ran cleanly. But Qwen 3.6-35B-A3B-NVFP4 still topped out at 44 tok/s single-stream. A static audit of the loaded model explained why.
A small forward-hook patch on vllm.v1.worker.gpu_model_runner.GPUModelRunner.load_model walked model.named_modules() after weight loading and dumped each module's type(quant_method).__name__. The result was unambiguous:
| Layer type | Count | Quant method | Total weight |
|---|---|---|---|
linear_attn.in_proj_qkvz | 30 | UnquantizedLinearMethod | 1.44 GB BF16 |
linear_attn.out_proj | 30 | UnquantizedLinearMethod | 480 MB BF16 |
mlp.gate (router) | 40 | UnquantizedLinearMethod | 40 MB BF16 |
lm_head | 1 | UnquantizedEmbeddingMethod | 970 MB BF16 |
That's about 2.9 GB of BF16 weights read per single-stream decode token, on top of the 1.7 GB of NVFP4 weights for the active 3B MoE experts. At 273 GB/s, that hybrid Qwen 3.5-MoE architecture has a theoretical ceiling around 60 tok/s — and we measured 44, in the right neighborhood for "BF16 cuBLAS GEMV at batch=1 is slow."
linear_attn is the GDN/SSM mixer in the Qwen3-Next architecture. Each layer's in_proj_qkvz is a [12288, 2048] projection that the LLM Compressor recipe explicitly excluded from quantization for SSM precision reasons. On a memory-bound platform, that decision dominates single-stream throughput. The b12x kernel was never the issue.
Switching to Nemotron 3 Nano: same A3B size, no GDN tax
Nemotron 3 Nano-30B-A3B uses a Nemotron-H base — also hybrid SSM/Mamba — but a much lighter quantization-exclusion list. The W4A16 community quant by cybermotaz/nemotron3-nano-nvfp4-w4a16 keeps weights in FP4 and activations in BF16. That avoids the per-step activation FP4 quantization overhead that hurts single-stream latency.
The bench:
| Model | Variant | Single-stream | c=16 aggregate |
|---|---|---|---|
| Qwen 3.6-35B-A3B-NVFP4 | hybrid | 44.32 | 363 |
| Gemma 4-31B-IT-NVFP4 | dense | 6.85 | 105 |
| Nemotron 3 Nano | W4A16 | 74.75 | 400 |
(Nemotron 3 Nano Omni — the multimodal sibling — is excluded here because the b12x patched stack feeds it NaN logits via modelopt_mixed dispatch. That model needs a different image; see Part 26 for the working multimodal recipe.)
Single-stream and aggregate are different regimes:
- W4A16 wins single-stream by 28% over W4A4 — no per-step activation quant, less compute per token.
- W4A4 wins aggregate by 96% over W4A16 — compressed activations let you batch more tokens per HBM read, so multi-batch scales harder.
If your workload is one user typing into a chat box, ship W4A16. If you're running a serving cluster with concurrency 16+, ship W4A4. They are not the same trade-off.
The bench script:
# 200-token deterministic decode, threaded concurrency
import json, time, urllib.request, threading
def req(out):
data = json.dumps({
"model": "nemotron-w4a16",
"messages": [{"role": "user", "content": PROMPT}],
"max_tokens": 200, "temperature": 0.0,
}).encode()
t0 = time.perf_counter()
r = urllib.request.urlopen(urllib.request.Request(
URL, data=data, headers={"Content-Type": "application/json"}
), timeout=600).read()
out.append((time.perf_counter() - t0,
json.loads(r)["usage"]["completion_tokens"]))
# Warm up first, then sweep concurrency 1-16
Output quality verified across factual, translation, and code tasks. No !!!!! garbage runs, no token degeneration. The model handles <think> reasoning blocks correctly even without the dedicated nano_v3_reasoning_parser (it just lands in content instead of being split into a separate field).
But wait — did 74.75 tok/s actually run NVFP4 compute?
Honest answer: the weights are NVFP4, the compute is not. This is worth pulling apart because the framing "NVFP4 finally beat FP8" oversells what's happening.
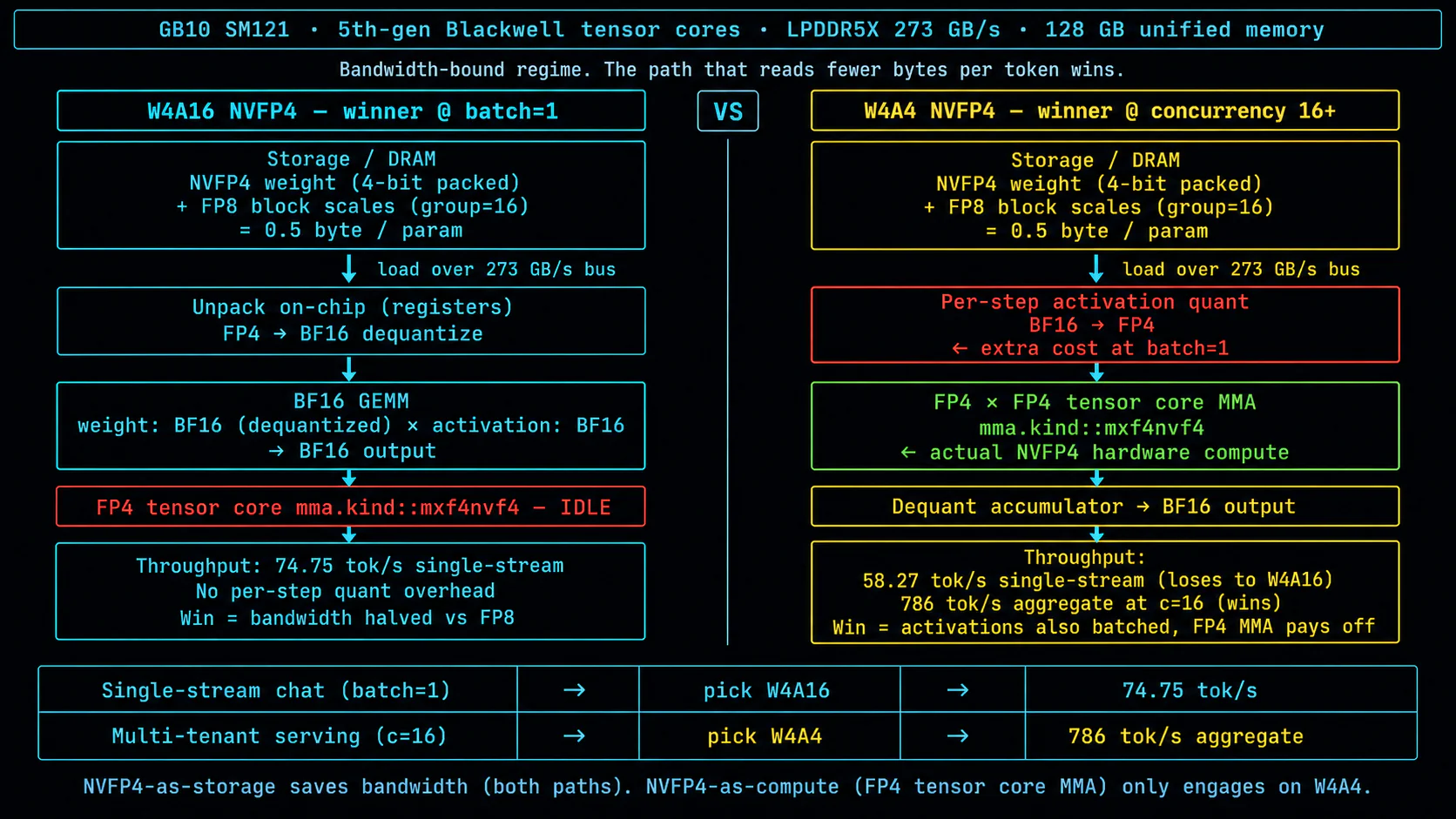
The diagram splits the W4A16 path (winner at batch=1) from the W4A4 path (winner at concurrency 16+) and shows where each engages — or doesn't engage — the FP4 tensor core. Three layers matter:
| Layer | W4A16 (74.75 tok/s) | W4A4 (786 tok/s aggregate) |
|---|---|---|
| Weight storage | NVFP4 packed, 0.5 byte/param | NVFP4 packed, 0.5 byte/param |
| Dispatch kernel | FlashInferB12xNvFp4LinearKernel (b12x) | FlashInferB12xNvFp4LinearKernel (b12x) |
| Activation | BF16 (no per-step quant) | FP4 (BF16→FP4 quant every decode step) |
| Actual GEMM | BF16 × BF16 after on-chip dequant | FP4 × FP4 via mma.kind::mxf4nvf4 |
| FP4 tensor core | Idle | Active |
So when I say "NVFP4 hit 74.75 tok/s" — what's true is the weight storage is NVFP4. The 5th-generation Blackwell mma.kind::mxf4nvf4 instruction (the actual FP4 hardware MMA) only fires on the W4A4 path. On W4A16, the FP4 weight is dequantized to BF16 in registers before the GEMM, and the multiply itself runs as a BF16 × BF16 operation.
The 57% win over the Triton FP8 hack came from bandwidth, not compute. GB10 is bandwidth-bound at single-stream — 273 GB/s LPDDR5X, weights dominate per-token byte budget — so cutting weight bytes per param from 1 (FP8) to 0.5 (FP4) was enough to nearly double throughput on its own. The FP4 tensor core staying idle didn't matter, because at batch=1 the GEMM compute isn't the bottleneck.
W4A4 does engage the FP4 tensor core, and at batch=1 it's still slower (58.27 tok/s) — because the per-step BF16→FP4 activation quantization eats more time than the FP4 MMA saves. At concurrency=16, the activation quant cost amortizes across the batch and W4A4's compute advantage finally pays off (786 tok/s aggregate vs W4A16's 400).
Punchline: NVFP4-as-storage wins both regimes. NVFP4-as-compute (FP4 tensor core) only wins multi-batch. If you read "NVFP4 hit 74.75 tok/s" and pictured the 5th-gen Blackwell tensor cores cranking — that's not what's happening. The win is bandwidth math, not silicon utilization.
The MTP detour: 5 failures, 0 wins
Multi-Token Prediction is the standard speculative decoding trick to break past memory bandwidth ceilings — predict 2-3 tokens per forward pass, accept what's right, retry what's wrong. NVIDIA's Spark Deployment Guide explicitly recommends --speculative_config '{"method":"mtp","num_speculative_tokens":3}' for Nemotron 3.
Five attempts, none successful:
- Qwen 3.6 + b12x MoE backend.
b12xdoesn't support unquantized MoE — the draft model defaulted to BF16 and the dispatcher refused. Errored at startup. - Qwen 3.6 + flashinfer_cutlass + gpu_memory_utilization=0.85. vLLM's CUDA-graph memory profiler returned
-35.63 GiB(sign bug, no clamp), which inflated the available KV cache budget to 112 GB on a 128 GB unified-memory system. SIGKILL during graph capture. - Same, with util=0.70. Same OOM, same kill.
- Same, with util=0.65 + max_num_seqs=16. Same OOM, same kill.
- Nemotron 3 Nano W4A16 + mtp method. vLLM 0.20 promotes Nemotron-H to MTP only when
num_nextn_predict_layers > 0exists in the model config. Thecybermotazcommunity quant stripped that field.NotImplementedError: Unsupported speculative method: 'mtp'at config validation.
ngram speculative as a workaround lost 25% on essay-generation prompts (74.75 → 55.70). Essays don't have repeating n-grams, so the prompt-lookup table never hits, and the wasted draft compute slows things down.
The Codex review I ran on this concluded that breaking past 74.75 with this exact stack would require either (a) a new vLLM cherry-pick like PR #35947 for the E2M1 software fallback (uncertain throughput gain), or (b) finding an EAGLE3 head trained for Nemotron-H (none exists publicly). Neither is a 2-hour fix.
The shape of "MTP is the speedup" became "MTP is the next 6-month research project."
Takeaways
Where the time went
The MTP cul-de-sac. Five separate failure modes, each looking like the last one's ghost. The OOM-then-system-freeze cycle in particular needed a physical reboot trigger from the user — vLLM's CUDA-graph memory profiler has no negative-value clamp, and a -35.63 GiB estimate at high gpu_memory_utilization will silently allocate more than the system's unified-memory ceiling and lock the kernel.
What actually advanced the throughput was a sequence of static introspection passes — dumping model.named_modules() to find which projections were UnquantizedLinearMethod, reading vllm/config/speculative.py to learn that mtp is gated on a model config field that community quants strip out, and grepping the FlashInfer source to confirm the b12x kernel hardcoded sm_120 in three places.
Reusable diagnostic patterns
1. Static module audit beats forward hooks. When a model is too slow and you don't know which layers dominate, walk model.named_modules() after load_model() and group by type(m.quant_method).__name__. You'll see the BF16 fallback layers immediately. No NVTX, no profiler trace, no framework changes.
2. Read the kernel's source before trusting the dispatch log. Using FlashInferB12xNvFp4LinearKernel for NVFP4 GEMM appeared in the launch log on day 1, but the kernel itself had sm_version="sm_120" baked in three places that needed monkey-patching. The dispatch log confirms intent, not behavior.
3. CUDA-graph memory bugs masquerade as OOM. If vLLM's gpu_worker.py:448 log says Estimated CUDA graph memory: -X GiB, the estimator is broken and the KV-cache budget is wrong. Pin --kv-cache-memory-bytes directly instead of relying on --gpu-memory-utilization.
Universal pattern
Memory bandwidth is a physical fact. 273 GB/s on LPDDR5X is the budget for everything you need to read per token — quantized weights, plus whatever lm_head and unquantized layers the checkpoint kept in BF16. The exact ceiling depends on those non-quant residuals (a clean back-of-envelope for Nemotron 3 W4A16 lands somewhere in the low 80s tok/s), and 74.75 tok/s is far enough up that curve that the next gain has to come from changing the bytes-per-token regime, not optimizing kernels. Speculative decoding, smaller active param counts, or faster memory are the only directions left.
Conclusion
If you want NVFP4 single-stream throughput on DGX Spark today:
- Cherry-pick vLLM PR #40082 onto vLLM main.
- Apply the 4-layer SM121 patch stack (
libs-cu13,cutlass-dsl mma.py, FlashInfer dense kernel, env vars). - Use a non-hybrid model.
cybermotaz/nemotron3-nano-nvfp4-w4a16is the highest single-stream tok/s I've measured. - Pick W4A16 for chat, W4A4 for serving. They optimize for different metrics.
- Skip MTP for now. The vLLM/checkpoint compatibility matrix isn't clean yet.
The complete mod and recipe ship in the spark-vllm-docker fork as mods/sm121-b12x-full-enable/run.sh and recipes/nemotron-w4a16.yaml. Reproducing the 74.75 should take about 30 minutes from a clean image build.
Also in this series:
- Part 26: Watching English Videos with DGX Spark — Nemotron Omni Audio+Video — same hardware, multimodal: 3-min talk transcribed in 89s
- Part 19: NVFP4 Is a Trap on GB10 — FP8 Wins by 32% — what I thought NVFP4 was 10 days ago
- Part 20: NVFP4 → FP8 Triton Patch — 47.6 tok/s — the FP8 hack this article beats
- Part 7: Gemma 4 26B NVFP4 — 52 tok/s on DGX Spark — same approach, different model
FAQ
- How fast is Nemotron 3 Nano NVFP4 on DGX Spark?
- 74.75 tok/s single-stream on cybermotaz/nemotron3-nano-nvfp4-w4a16 (W4A16) with our patched vLLM image. That's 11.5% past the public 67 tok/s forum baseline. The number is firmly inside the bandwidth-bound regime for a 3.5B active-param model on GB10's 273 GB/s LPDDR5X — further gains will need more than kernel tuning.
- W4A16 or W4A4 on DGX Spark?
- Depends on workload. W4A16 wins single-stream chat (74.75 vs 58.27 tok/s). W4A4 wins multi-batch serving (786 vs 400 tok/s aggregate at concurrency 16). The activation FP4 quantization in W4A4 has per-step overhead but lets you batch more tokens per HBM read.
- Did NVFP4 finally beat FP8 on GB10?
- Yes — but the win is bandwidth, not compute. Cutting weight bytes per param from 1 (FP8) to 0.5 (NVFP4) on a memory-bound box doubles throughput by itself. The actual FP4 tensor core (mma.kind::mxf4nvf4) only fires on W4A4, not on the W4A16 setup that hit 74.75 tok/s — W4A16 dequantizes FP4 weights to BF16 in registers and runs BF16 GEMM. So 'NVFP4 beats FP8' here means NVFP4-as-storage, not 5th-gen Blackwell tensor cores being utilized. The 'NVFP4 is a trap' diagnosis was correct for Qwen 3.6 hybrid models — BF16 GDN linear_attn projections were the real bottleneck.
- What's in the 4-layer patch stack?
- 1) pip install nvidia-cutlass-dsl-libs-cu13==4.4.2 for CUDA 13 backing libs. 2) Patch cutlass-dsl warp/mma.py admissible_archs and base equality check to allow sm_121a. 3) Patch FlashInfer dense_blockscaled_gemm_sm120.py sm_version check. 4) Set CUTE_DSL_ARCH=sm_121a + VLLM_NVFP4_GEMM_BACKEND=flashinfer-b12x. Cherry-pick vLLM PR #40082 for the b12x dispatcher.
Read next
- 2026-06-01[Benchmark] NVFP4 W4A4 beats FP8 on a DGX Spark MoE: 67 vs 52 tok/s once CUDA graphs fire
On a GB10 DGX Spark, NVFP4 W4A4 went from 23 to 67 tok/s the moment I dropped --enforce-eager — beating FP8 by 29% and saving 16GB. The catch from Part 32 was real, just dense-only.
- 2026-04-05Gemma 4 26B-A4B on DGX Spark: 52 tok/s with NVFP4, skip the 31B
Gemma 4 26B-A4B + NVFP4 hits 52 tok/s on DGX Spark (GB10) — 7.5× faster than the 31B dense, in 16.5 GB with 82 GB free for KV cache. Plus the vLLM 0.19 marlin/patch gotchas that make it work.
- 2026-05-30NVFP4 is 1.5× FP8 on a DGX Spark — but it's compression, not the FP4 cores
On a GB10 DGX Spark, NVFP4 beats FP8 by ~1.5× for single-stream decode on a dense model. But the win is bandwidth (smaller weights), not the FP4 tensor cores — the fastest path never touches them.
- 2026-05-06Liftoff: Gemma 4 hits 670 tok/s aggregate on DGX Spark (108 tok/s single-stream)
Google announced Multi-Token Prediction drafters for Gemma 4 on 2026-05-05. The vLLM PR was opened and approved the same day; a preview Docker image shipped hours later. I tested it on DGX Spark: Gemma 4 26B-A4B-it FP8 + MTP γ=4 hits 108.78 tok/s single-stream (2.66× baseline), 674.28 tok/s aggregate at concurrency=8. One undocumented trap: the drafter pairs with -it, not base.
Don't miss the next one
Subscribe, and you won't.
One-click unsubscribe anytime.