DGX Spark · part 26
[vLLM] DGX Spark 跑英文影片:Nemotron Omni 多模態實戰
❯ cat --toc
TL;DR
Part 25 那台跑純文字 74.75 tok/s 的 DGX Spark,這次拿來看英文影片。Nemotron-3-Nano-Omni-30B-A3B(NVIDIA card 標 ~31B 總參數、3B active)處理 Jawed Karim 的 19 秒「Me at the zoo」花 15 秒、處理 Karpathy 演講前 3 分鐘花 89 秒 / 53,842 prompt token,講話內容跟畫面都抓得對。前面踩了兩個雷:use_audio_in_video 一定要放 request 最外層(塞進 video_url 物件裡會直接被忽略),還有上一篇那個 b12x patched image 一碰 Omni 就 NaN logits — 換 upstream vllm/vllm-openai:v0.20.0 就過了。Recipe 放文末。
白話版:3 萬塊的桌機怎麼幫你看完英文影片
DGX Spark 是 NVIDIA 賣的小型 AI 桌機,台幣 9 萬出頭。我之前都拿它跑文字 — chat、寫 code、隨便聊。但同一顆晶片只要載多模態 model,影片跟音訊一樣處理。NVIDIA 出了一顆 Nemotron-3-Nano-Omni-30B-A3B,三樣東西包在一起:看影格的 vision encoder、聽聲音的 Parakeet 音訊 encoder、再加 30B-A3B 的 LLM 把兩邊接起來(NVIDIA model card 寫總參數 ~31B、每 token 啟用 3B 的 MoE)。
我想做的事很單純:丟一支英文 YouTube 影片、podcast 片段、研討會演講進去,model 看完聽完之後幫我寫心得。不是純逐字稿、也不是純畫面描述,而是把講的內容跟看到的畫面一起理解。
這篇就是流程跑通的紀錄。前兩個雷讓我整個晚上噴掉,第三個是長影片要怎麼調 knob。每段都附實測資料。
前言
Part 25 在拚 30B model 單流文字 throughput 衝到 74.75 tok/s。這篇的目標完全不一樣 — 重點是多模態到底對不對,速度不是 headline。當你卡在「model 到底有沒有聽懂」這種問題,throughput 那條曲線根本不重要。
這篇兩個雷都在 config 層級,不是架構問題。Model 沒壞、vLLM serving 也沒壞。但兩個 flag 放對放錯,差別就是「真的聽懂」對「自信滿滿地腦補」 — 偏偏 NVIDIA model card 的範例兩個都沒明寫。
19 秒短片戳出來的音訊雷
第一支拿來測的是大名鼎鼎的「Me at the zoo」 — Jawed Karim 2005 年 4 月 23 日上傳,YouTube 史上第一支影片,19 秒,公開、極短、英文清楚。
Jawed Karim, 'Me at the zoo'(2005-04-23)— YouTube 史上第一支影片,19 秒。
Model 第一次回答畫面寫得很對 — 年輕男生穿藍衫加紅灰外套、兩隻大象、稻草、圍欄全寫對了。但逐字稿吐給我的是這個:
"I'm here at the San Diego Zoo. And I'm going to show you some elephants. There are three of them. One is eating hay..."
幻覺。對照 YouTube 英文字幕,實際旁白是:
"Alright, so here we are in front of the elephants. The cool thing about these guys is that they have really, really, really long trunks. And that's, that's cool. And that's pretty much all there is to say."
整段沒提 San Diego Zoo、也沒有三隻大象。Model 根本沒在聽 — 從畫面推一段聽起來合理的旁白出來而已。畫面對得太準,害我想了一下才反應過來。
問題出在 vLLM chat parser,chat_utils.py:910 這段看得最清楚:
# Extract audio from video if use_audio_in_video is True
if (
video_url
and self._mm_processor_kwargs
and self._mm_processor_kwargs.get("use_audio_in_video", False)
):
audio = self._connector.fetch_audio(video_url) if video_url else None
audio_placeholder = self._tracker.add("audio", (audio, uuid))
self._add_placeholder("audio", audio_placeholder)
沒這個 flag,vLLM 根本不會把音軌從影片抽出來、也不會餵給 Parakeet。Model 只拿到畫面,只好硬猜講者在說什麼。
flag 必須放在 chat completion request 的最外層,不是 video_url 物件裡:
{
"model": "nemotron-omni",
"mm_processor_kwargs": {"use_audio_in_video": true},
"messages": [{
"role": "user",
"content": [
{"type": "video_url", "video_url": {"url": "data:video/mp4;base64,..."}},
{"type": "text", "text": "把音訊轉錄出來。再描述畫面。"}
]
}]
}
flag 移到外層之後再跑一次:
"Alright, so here we are, one of the uh elephants. Um, cool thing about these guys is that they have really, really, really long um trunks. And that's that's cool. And that's pretty much all there is to say."
意思都到了 — 大象的框架對、"really, really, really long trunks" 這個關鍵錨點對、結尾也對。ASR 有點 drift("one of the uh" 跟原版的 "in front of the" 對不太上、多了幾個 "um"),但語意全保留。15 秒 wall time、5,637 prompt tokens、689 completion tokens。
3 分鐘 Karpathy 演講:把規模拉長
flag 修對之後,下一個問題是「這台桌機能吃多長的影片」。我抓 Andrej Karpathy「Intro to Large Language Models」前 3 分鐘 — 有講者鏡頭、投影片切很多、技術濃度高。
Andrej Karpathy, 'The busy person's intro to LLMs' — 測試前 3 分鐘。
Model 吐出來的內容(結構我有整理過、原輸出帶時間戳):
Andrej Karpathy 自我介紹,提到他之前講過一個 30 分鐘 LLM 演講沒被錄起來,所以重錄一次給 YouTube。標題投影片寫「The busy person's intro to LLMs」。下一張投影片是
llama-2-70b的目錄、底下兩個檔案:parameters(140GB)跟run.c(約 500 行 C)。他解釋 parameters 檔 140GB 是因為 70 億參數每個用 2 bytes 的 float16 存。run.c 沒任何 dependency — 編譯成 binary、加上 parameters 檔,MacBook 離線就能跑這顆 LLM。
每個 fact 都對。llama-2-70b、140 GB、~500 行 run.c、MacBook 跑 model — 全部對得上 Karpathy 影片真的講的內容。輸出是「整理過」、不是逐字稿,但技術重點全保留。
| 指標 | 數值 |
|---|---|
| 影片長度 | 180 秒(3 分鐘) |
| Wall time | 89 秒 |
| Prompt tokens | 53,842 |
| Completion tokens | 2,000(撞到 max_tokens 上限) |
| 換算速率 | 每秒影片約 300 prompt tokens |
每秒影片 300 prompt token 這個數字兩支都吻合,後面規劃長影片就以這個為基準。
模型裡面長什麼樣
先把這顆 model 的架構畫出來,後面講 b12x dispatch 不相容、Mamba assertion、音訊 token 數,才會落在脈絡裡:
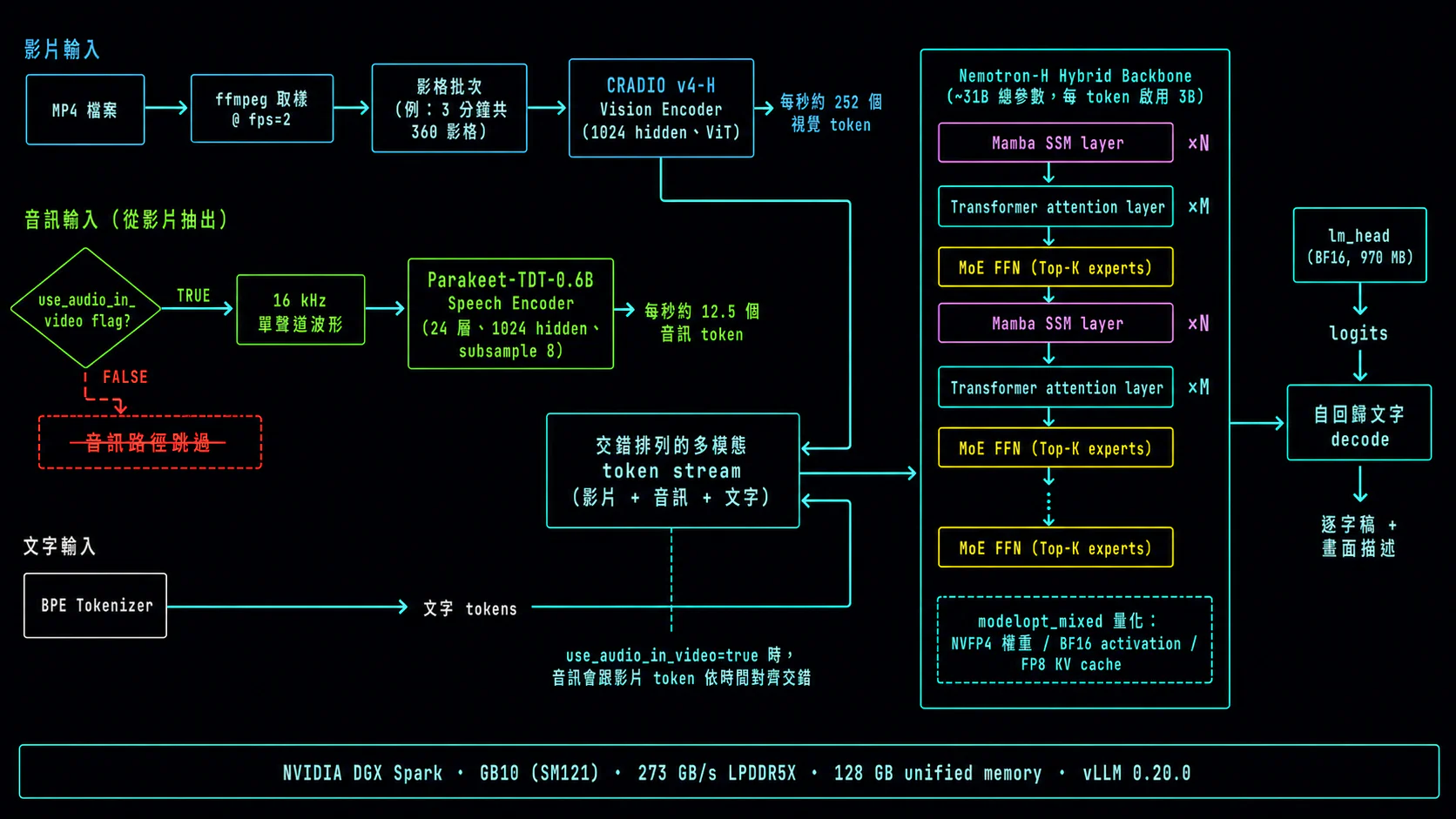
這張圖三個重點直接連到後面三段:
use_audio_in_videoflag 真的就是 Parakeet 那條路的開關。flag 放錯位置,Parakeet 那條流程根本不會跑,model 只剩畫面可以猜音訊。- Mamba SSM layer 是 backbone 裡的 — 這就是為什麼上 upstream image 起來會撞
block_size (2128) must be <= max_num_batched_tokensassertion。Nemotron-H 是 hybrid、不是純 transformer。 modelopt_mixedquantization(NVFP4 weight / BF16 activation / FP8 KV cache、vision/audio/LLM 各用不同精度)就是被我們 b12x patch 打到的東西。我們 patch 假設只有一種 quant config,這顆 model 三種混搭。
另一個雷:別用 b12x image
Part 25 我自己 build 了一個 vllm-node-tf6-b12x — vLLM 0.20.1 cherry-pick PR #40082 加 4 層 SM121 patch。這個 image 跑文字衝到 74.75 tok/s。第一直覺當然是 Omni 也用同一個 image。
跑不起來。第一個 decode step 就 NaN logits、output 全是 !!!!!!!!!!!!、engine 也救不回來。vLLM 啟動 log 寫的 dispatch 是這條:
Selected FlashInferFP8ScaledMMLinearKernel for ModelOptFp8LinearMethod
Omni 用的是 modelopt_mixed quantization — vision 跟 audio encoder 一個精度、LLM 主體另一個精度。我們那 4 層 SM121 patch 改了 FP8 GEMM kernel selection 的邏輯,剛好打到 Omni 這個混合 config 就會出問題。我沒去 trace 到底哪一行出包,因為實務上有更省事的做法:換 upstream image。
docker run -d --name vllm_upstream --gpus all --network host --ipc=host \
--shm-size 16g \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--entrypoint /bin/bash \
vllm/vllm-openai:v0.20.0 \
/tmp/launch-upstream-omni.sh
Upstream vllm/vllm-openai:v0.20.0 沒我們的 patch,走的是 Omni 出廠原本測過的 kernel selection 路徑。同一台機器、同一顆 model、兩個 image 各做各的事。
這不表示一定要永遠拆開。哪顆 model 跟 patched image 打架,就另外開一個 upstream container 跑它;想一個 image 通吃全部,通常就是踩這種坑。
Mamba block_size assertion:啟動時的小坑
Upstream image 第一次起 --max-model-len 65536,engine init 就掛:
AssertionError: In Mamba cache align mode,
block_size (2128) must be <= max_num_batched_tokens (2048).
Nemotron-3 是 hybrid 架構、有 Mamba/SSM layer。Mamba 的 KV cache block size 是從 model config 算出來的,vLLM 預設 max_num_batched_tokens=2048 比那個 block size 小,所以才撞到。改一個 flag 就好:
--max-num-batched-tokens 8192
把 prefill 的 batch budget 調大就過了。我們單流 concurrency=1 用不到那麼多 — 這 flag 是 prefill 一次 batch 多少 token 的上限,單支影片 request 根本碰不到。
影片可以多長?
從 3 分鐘 Karpathy 那次的資料反推:fps=2 下每秒影片大約 300 prompt tokens。瓶頸有三個 — --max-model-len、num_frames、跟採樣的 fps。
| 影片長度 | fps | num_frames 上限 | max-model-len | 預估 prompt tokens | 備註 |
|---|---|---|---|---|---|
| 1 分鐘 | 2 | 128 | 32768 | ~18k | 預設可以跑 |
| 2 分鐘 | 2 | 256 | 32768 | ~36k | max-model-len 拉到 65536 |
| 3 分鐘 | 2 | 512 | 65536 | ~54k | 這篇實測的 |
| 5 分鐘 | 1 | 300 | 65536 | ~45k | 視覺細節砍一半,音訊不變 |
| 10 分鐘 | 0.5 | 300 | 98304 | ~45k | 視覺細節砍 3/4,手勢/投影片會漏 |
| >10 分鐘 | — | — | — | — | ffmpeg 切段、每段獨立處理、再串心得 |
這張表藏兩個取捨:
**fps↓ 省 token 但不影響音訊。**Parakeet 跑的是 16 kHz 音訊波形,跟 video frame rate 完全獨立。音訊是另外一條路在跑、跟 fps 沒直接關係,所以 fps 降下來每秒還是大概 12.5 個 audio token。降 fps 砍的是視覺 token 數跟視覺細節(手勢、投影片切換),音訊轉錄品質不變。長影片要拉長就靠這個 — fps 降到 0.5、音訊一樣清楚。
**num_frames↑ + max-model-len↑ 吃統一記憶體。**GB10 的 128 GB 是 weight 跟 KV cache 共用。max-model-len 翻倍,KV cache budget 也翻倍。98k context 的時候,光一支影片 request 就吃掉桌機一半以上的 RAM。
超過 10 分鐘我會先 ffmpeg 切段、各段分開跑、再用一顆小型純文字 LLM 把 chunk 心得串起來。這台 9 萬桌機不適合單次吃完整段長影片。
可用的 recipe
spark-vllm-docker/recipes/nemotron-omni.yaml:
recipe_version: "1"
name: nemotron-omni
description: Nemotron-3-Nano-Omni multimodal (video+audio) on upstream vLLM 0.20.0
model: nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4
container: vllm/vllm-openai:v0.20.0
solo_only: true
defaults:
port: 8004
host: 0.0.0.0
gpu_memory_utilization: 0.80
max_model_len: 65536
max_num_seqs: 8
max_num_batched_tokens: 8192
command: |
pip install "vllm[audio]" --quiet && \
vllm serve nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4 \
--served-model-name nemotron-omni \
--trust-remote-code \
--gpu-memory-utilization {gpu_memory_utilization} \
--max-model-len {max_model_len} \
--max-num-seqs {max_num_seqs} \
--max-num-batched-tokens {max_num_batched_tokens} \
--kv-cache-dtype fp8 \
--reasoning-parser nemotron_v3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--limit-mm-per-prompt '{{"video":1,"image":1,"audio":1}}' \
--media-io-kwargs '{{"video":{{"fps":2,"num_frames":512}}}}' \
--enable-prefix-caching \
--host {host} \
--port {port}
3 分鐘 MP4 丟進 /tmp/、base64 編一下、request 最外層帶 mm_processor_kwargs: {"use_audio_in_video": true},90 秒就拿到一份「轉錄 + 畫面描述」的回答。
收穫
可以搬走的方法
1. 多模態 model 在幻覺,先懷疑某個模態被 silent drop。 畫面對得很準、音訊卻是「合理但講者根本沒說過」 — 這個訊號就是某個 flag 該開沒開。直接 grep 框架原始碼找那個 flag,確認 gating 是真的有開。
2. 沒有哪個 image 能通吃所有 model。 針對某個 model 做的 patch 可能打破另一個 model 的 dispatch。某顆 model 在客製 image 上跑壞,先拿 upstream image 做 A/B,很多時候直接就過。
3. 多模態的 token budget 跟著影片長度走、不是文字長度。 Nemotron-3-Nano-Omni 在 fps=2 是每秒影片 ~300 prompt tokens。前後文字 prompt 占不到主體 — 主體是 frame embedding。
通用原則
這台桌機跑一支 3 分鐘多模態影片,token 量就是純文字 chat 的 5 倍。平常不用管的 KV cache 跟 prefill batch budget,換成影片就真的會卡到。要跑 multi-tenant serving 的話,影片流量跟文字流量最好分開排,兩邊量級差很多。
收尾
DGX Spark 真的能看英文影片告訴你內容。配方:
- 用 upstream
vllm/vllm-openai:v0.20.0,不要用 patched image。 - 加
--max-num-batched-tokens 8192過 Mamba block_size assertion。 --max-model-len 65536、num_frames=512、fps=2撐到 ~4 分鐘。- 一定要把
mm_processor_kwargs: {"use_audio_in_video": true}放在 chat request 最外層 — 沒這個 flag 音訊整個被 silent drop。 - 影片 >5 分鐘就降 fps — Parakeet 跑 16 kHz 跟 fps 無關,音訊品質不會掉;>10 分鐘就 ffmpeg 切段。
Part 25 那台 DGX Spark 文字跑 74.75 tok/s,現在 3 分鐘英文影片 90 秒看完。兩個 image、一台機器、兩種工作。
系列其他文章:
- Part 25:DGX Spark 跑 Nemotron 3 Nano NVFP4 — 74.75 tok/s — 同硬體的純文字 throughput
- Part 7:Gemma 4 26B NVFP4 — 52 tok/s — 同台桌機更早的 benchmark
常見問題
- DGX Spark 真的能看 YouTube 影片告訴我內容嗎?
- 可以。Nemotron-3-Nano-Omni-30B-A3B 在 DGX Spark 上,19 秒短片 15 秒看完、3 分鐘演講 89 秒看完,講的內容跟畫面都抓得對。但要避兩個雷:use_audio_in_video flag 一定要放 request 最外層(不能塞進 video_url 物件),而且不能用上一篇那個 b12x patch 過的 image — Omni 在那 image 上會吐 NaN logits。
- 為什麼影片送進去之後音訊內容是亂掰的?
- vLLM 只在 chat completion request 最外層的 mm_processor_kwargs 看到 use_audio_in_video=true 才會啟動 Parakeet 音訊編碼器。flag 塞進 video_url 物件裡會直接被忽略,model 只拿到畫面,就從畫面腦補一段「聽起來合理」的旁白出來。修法:把 flag 移到最外層。
- GB10 上 Nemotron Omni 能看多長的影片?
- fps=2 + max_model_len=65536 大概到 3-4 分鐘是極限(每秒影片約 300 prompt token,含音訊)。5-10 分鐘要把 fps 降到 1 或 0.5;超過 10 分鐘就老實用 ffmpeg 切段、每段獨立跑再串心得。單次 context 撐不住。
- 為什麼不能用上一篇那個 74 tok/s 的 b12x image?
- Omni 用的是 modelopt_mixed quantization(vision/audio/text 各自不同精度混搭),我們的 b12x patch 改掉 FlashInferFP8ScaledMMLinearKernel 的 dispatch 路徑,剛好把 Omni 這個混合 config 弄出 NaN logits。實務上不去 trace patched source,直接換 upstream vllm/vllm-openai:v0.20.0 — 沒我們的 patch,Omni 出廠就跑得起來。
接著讀
- 2026-06-04[Benchmark] Gemma 4 12B omni 上 DGX Spark:weight-only NVFP4 贏 W4A4,還保住多模態
我在 DGX Spark GB10 上量化 Google 新的 omni Gemma 4 12B。weight-only NVFP4 只要 7.7GB、跑 24.9 tok/s,而且圖片/語音/影片都還能用 —— 全 W4A4 反而沒比較快,還把多模態弄壞。
- 2026-07-07DGX Spark 2026 現況:哪些還能跑、哪些已經過時、我現在會怎麼配
DGX Spark 2026 年中現況整理:現在該用 vLLM、官方 Gemma 4 NVFP4 權重、MTP、長 context 多模態,以及仍然會咬人的坑。
- 2026-06-13[vLLM] DiffusionGemma 26B NVFP4 上 DGX Spark:158 tok/s,但 diffusion 的 tok/s 會騙你
DiffusionGemma 26B-A4B 用官方現成 image 就能在 128GB DGX Spark 上跑 vLLM,不用等 PR、不用 cherry-pick。NVFP4 單條 158 tok/s、四條同時 257。但單一個 tok/s 數字會騙人:diffusion 的速度取決於 256 token 的畫布有沒有填滿。
- 2026-06-01[Benchmark] NVFP4 W4A4 在 DGX Spark 上超車 FP8:拔掉 enforce-eager,MoE 從 23 衝到 67 tok/s
GB10 上 NVFP4 W4A4 拔掉 --enforce-eager 後從 23 衝到 67 tok/s,贏 FP8 29% 還省 16GB。Part 32 說 cudagraph 沒用——那只對 dense,MoE 完全相反。
不想錯過新文章?
訂閱我確保不漏接!
隨時一鍵退訂。