Troubleshooting · part 1
[Troubleshooting] HuggingFace 下載卡在 0 bytes:Xet、Windows、ai-toolkit 依賴地獄
❯ cat --toc
TL;DR
想在 Windows + RTX 5090 上用 ai-toolkit 訓練一顆 Wan 2.2 LoRA,結果光是「讓它跑起來」就先踩了三個坑:Python 3.13 依賴地獄(舊 scipy/numpy 沒 wheel → 跑去編原始碼然後炸,用 constraints 檔救)、HuggingFace 下載卡 0 bytes(huggingface_hub 1.x 的 Xet 並行下載在 Windows 直接掛死,HF_HUB_DISABLE_XET=1 + 逐檔抓繞過)、ssh 一斷線訓練就被殺(改用 schtasks 互動 token 存活)。三個都是「錯誤訊息指東、真兇在西」,這篇逐個拆給你看。

訓練還沒開始,先過三道牆。
白話版:訓練還沒開始,先跟環境打了一場架
我想在自己的 5090 上訓練一個 AI 角色(完整故事在這)。結果訓練都還沒開始,光是「讓環境跑起來、把模型抓下來」就連踩三個坑 —— 而且每個的錯誤訊息都在指錯方向,沒一個直接告訴你真兇是誰。這篇把三個坑怎麼查出來的過程寫下來,讓之後撞同一面牆的人少花幾個小時。
前言
訓練腳本跑起來之前,你得先過環境這一關。在 Windows + 最新的 Blackwell GPU + Python 3.13 這種「太新」的組合上,很多套件的預期跟現實對不上 —— 而且報出來的錯往往指向錯的方向。這篇是一連串「錯誤訊息說 A,真兇是 B」的偵探故事。
平台:Windows、RTX 5090(Blackwell、sm_120)、Python 3.13、透過 ssh 操作。底層 GPU/Python 換成別的也大多適用。
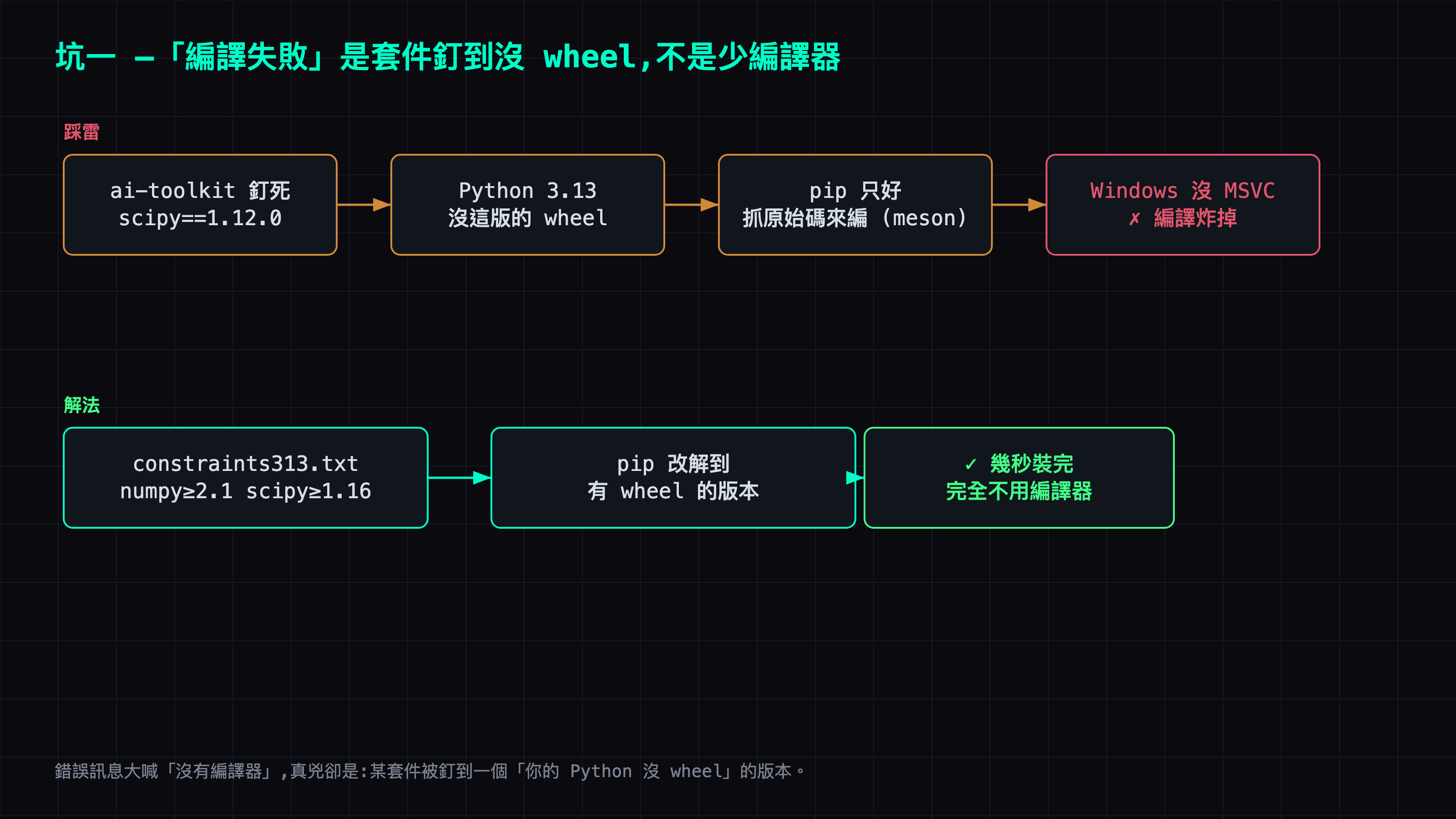
坑一:Python 3.13 依賴地獄 —— 真兇是沒有 wheel,不是程式碼
pip install -r requirements.txt 第一次就炸:
..\meson.build:1:0: ERROR: Unknown compiler(s): [['icl'], ['cl'], ['cc'], ['gcc'], ...]
error: metadata-generation-failed
meson 是 scipy/numpy 的建置系統 —— 它在試圖從原始碼編譯,而 Windows 上沒有 MSVC 編譯器。但為什麼要編譯?因為 ai-toolkit 釘死了舊版 scipy==1.12.0,而舊版 scipy 沒有 Python 3.13 的預編譯 wheel,pip 只好抓原始碼自己 build。
更麻煩的是 pip 的 backtracking 連 numpy 都拖下水:scipy 1.12.0 自己又要舊版 numpy(numpy<1.29),那個舊 numpy 在 Python 3.13 一樣沒有 wheel,於是連 numpy 都跟著開始編譯。(albumentations==1.4.15 這種為了 augmentation 釘死的舊 pin 只是讓相依解析更亂。)
解法不是裝編譯器,是禁止 pip 走原始碼版本。 用一個 constraints 檔把 numpy/scipy 釘在「有 wheel」的版本範圍,逼 pip 找到一個用新版的解,順便放寬那些只為了augmentation 釘死的舊 pin:
printf 'numpy>=2.1\nscipy>=1.16\n' > constraints313.txt
pip install -r requirements_relaxed.txt -c constraints313.txt
關鍵心法:Windows + 新 Python 上,「編譯失敗」九成不是要你裝編譯器,是有套件被釘到沒 wheel 的舊版。把它放開到有 wheel 的版本才是正解。 另外 torch 直接抄已知能跑的組合(我抄 ComfyUI 的 torch 2.11.0+cu128),torchao 的 uint4 量化也先單獨驗過能在 torch 2.11 + Blackwell 上跑,再往下走。
坑二:HuggingFace 下載卡在 0 bytes —— 偵探過程
環境裝好,訓練啟動,然後卡死在:
Fetching 3 files: 0%| | 0/3 [00:00<?, ?it/s]
process 還活著,但 blobs 資料夾 0 bytes,完全不動。逐步排查:
① 排除網路。 直接 curl 一個 shard:
curl.exe -sL -m 25 -o test.bin "https://huggingface.co/<repo>/resolve/main/<shard>.safetensors"
# 25 秒抓了 348 MB ≈ 14 MB/s
網路、CDN、認證全正常。API 也秒回。所以不是連不到。
② 縮小範圍。 huggingface_hub 升到 1.x 後改用 httpx,還自動裝了 hf-xet(Xet 協定)。錯誤的 traceback 裡出現 xet_file_data —— 走的是 Xet 路徑。
③ 關鍵測試。 設 HF_HUB_DISABLE_XET=1,單檔 hf_hub_download 一個 shard:
import os; os.environ["HF_HUB_DISABLE_XET"] = "1"
from huggingface_hub import hf_hub_download
# 11.25 GB / 35 秒 ≈ 314 MB/s —— 飛快
真兇:snapshot_download(也就是 from_pretrained 用的並行多執行緒下載)在 Windows 上掛 0 bytes,單檔下載卻沒事。 是 Xet 的並行下載在這台機器上 hang。
解法:繞過 snapshot,用單檔迴圈把 cache 灌滿,訓練啟動時就會發現全部 cached、跳過壞掉的並行抓檔:
import os
os.environ["HF_HUB_DISABLE_XET"] = "1"
from huggingface_hub import list_repo_files, hf_hub_download
for f in list_repo_files(repo):
hf_hub_download(repo, f) # 逐檔,穩
額外的坑:ai-toolkit 把一個模型拆成四個 HuggingFace repo(transformer、accuracy-recovery adapter、text encoder、VAE),每一個都會撞同樣的 Xet 卡死,全部都要用上面的方法預先灌進 cache。哪些 repo 不會寫在 log 裡,要去讀 source 才找得到。

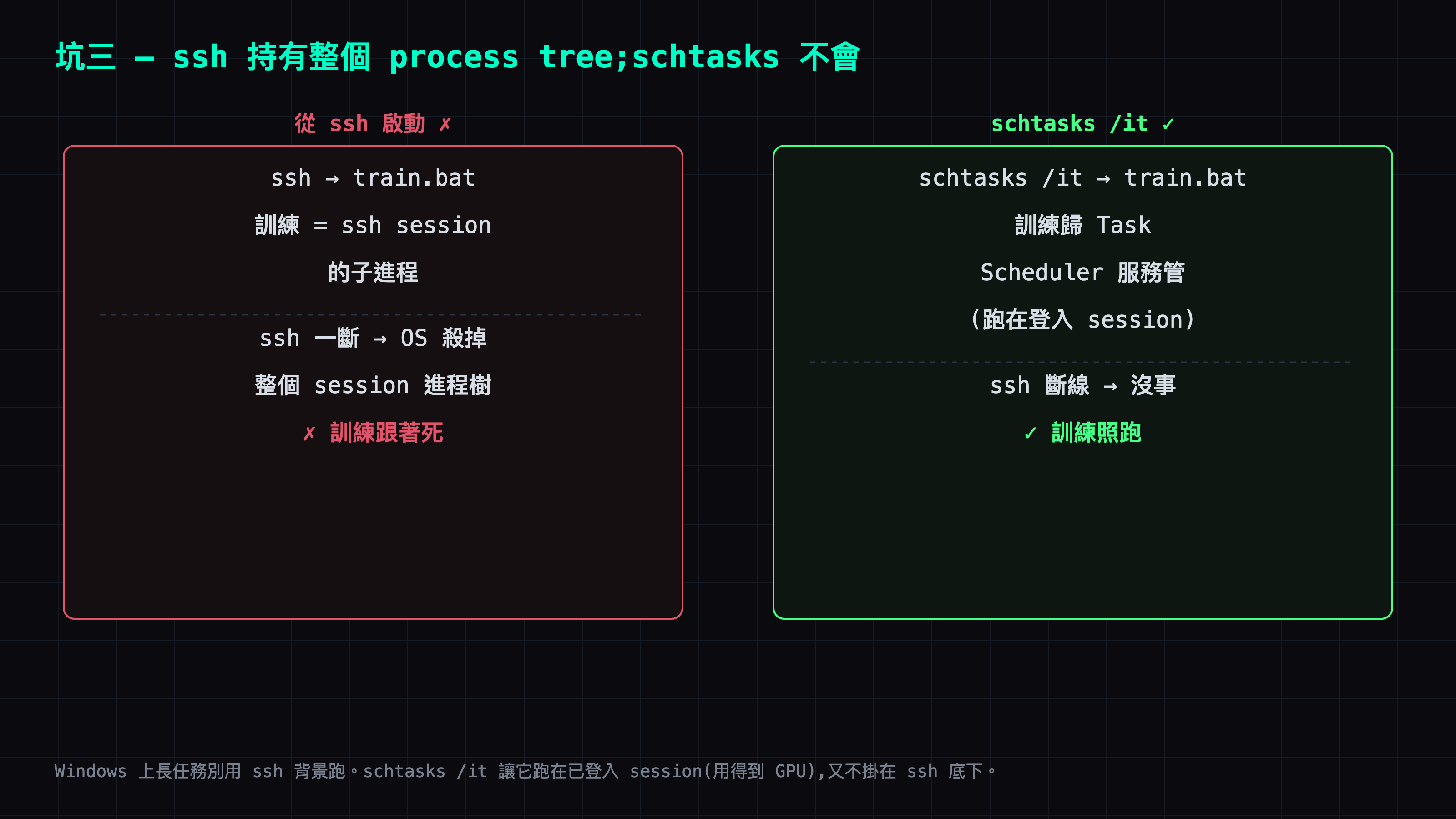
坑三:ssh 斷線把訓練殺了 —— 用排程工作存活
訓練是長時間任務,我從 ssh 啟動後想讓它在背景跑。但 Windows OpenSSH 在 session 斷線時,可能會把整個 session 的 process tree 一起殺掉(至少我這台、預設設定是這樣)—— ssh 一斷,訓練就死。
解法是不要從 ssh 直接啟動,改用 排程工作(schtasks)+ /it 互動 token:
schtasks /create /tn LoraTrain /tr "C:\path\train.bat" /sc once /st 00:00 /ru user /it /rl highest /f
schtasks /run /tn LoraTrain
/it 讓工作跑在使用者已登入的互動 session 裡(GPU 才能用),而這個工作是交給 Task Scheduler 服務管的,不掛在 ssh session 底下 —— ssh 斷線照跑。同一招也適用於需要長駐的 ComfyUI。
收穫
三個坑,三次「錯誤訊息指向錯的方向」:
- 最花時間的是 Xet 那個 —— 因為 curl 一切正常,很容易往「網路問題」鑽,但真兇在 library 的並行下載。排查心法:先用最笨的工具(curl)確認底層能動,再逐層往上縮小到是哪一層壞。
- 其他坑也能套用的查法:Windows + 新 Python「編譯失敗」≈ 套件被釘到沒 wheel 的舊版(放開版本,別裝編譯器);長時間任務在 Windows 上要存活,走 schtasks 互動 token,不要 ssh 背景啟動。
- 一句話教訓:在「太新」的平台上(最新 GPU + 最新 Python + 廠商剛改版的 library),你打的不是訓練、是環境;先把環境的每一層單獨驗過再往下走,比事後從錯誤訊息倒推快得多。
訓練本身跟成果(那個能換衣服、換畫風、會動的角色)在 Character LoRA 系列。這篇純粹是過程中跟環境打的那場架。
常見問題
- HuggingFace 下載卡在 0 bytes 怎麼辦?
- huggingface_hub 1.x 的 Xet 並行下載在 Windows 上會掛在 0 bytes。設環境變數 HF_HUB_DISABLE_XET=1 強制走一般 HTTPS 下載;還是卡的話,改用單檔 hf_hub_download 迴圈逐檔抓。
- 為什麼 ssh 啟動的訓練一斷線就死掉?
- Windows OpenSSH 在 session 斷線時,可能會把整個 session 的 process tree 一起殺掉(至少預設設定常常這樣)。用 schtasks 排程工作 + /it 互動 token 啟動,讓它跑在使用者的登入 session 裡,就能在 ssh 斷線後存活。
- Python 3.13 上裝 ai-toolkit 為什麼一直編譯失敗?
- ai-toolkit 釘死的舊版 scipy/numpy 在 Python 3.13 沒有預編譯 wheel,會嘗試從原始碼編譯,Windows 沒有 MSVC 就炸。用 constraints 檔強制 numpy>=2.1、scipy>=1.16 走有 wheel 的版本即可。