DGX Spark · part 27
Liftoff: Gemma 4 hits 670 tok/s aggregate on DGX Spark (108 tok/s single-stream)
❯ cat --toc
- In plain English: Google shipped a turbo button for Gemma
- Setup: standing on the shoulders of giants
- The trap: drafter pairs with `-it`, not base
- Three-target comparison matrix
- Concurrency: 8 users at 84 tok/s each
- Output sanity check: lossless or not?
- Credits and provenance
- Limitations
- Quickstart: two commands to run it
- Related reading
TL;DR
A new technique makes existing models N× faster — same model, same hardware, no retraining. Just a smarter inference path.
On 2026-05-05 Google announced Multi-Token Prediction (MTP) drafters for Gemma 4. vLLM PR #41745 was opened and approved the same day (still open / awaiting merge as of 2026-05-06); a preview Docker image shipped hours later. On DGX Spark (GB10 / SM12.1), Gemma 4 26B-A4B-it FP8 (RedHat's quant) + Google's drafter + γ=4 hits 108.78 tok/s single-stream (2.66× over 40.85 baseline), 674 tok/s aggregate at concurrency=8 (~84 tok/s/request). ⚠️ Undocumented trap: pair the drafter with an -it target, never base. With base I saw 41 → 25 tok/s — a 38% slowdown, not speedup.
Updated July 2026 — Still works: the 108 tok/s MTP result, and the trap (pair the drafter with an
-ittarget, never base). Changed: PR #41745 merged 2026-05-06 and shipped in vLLM v0.21.0 (2026-05-15) — the preview image +gemma4_mtp.pybind-mount are no longer needed; MTP is in stock vLLM (now v0.24.0). Current pick: stock vLLM ≥ 0.21.0.
In plain English: Google shipped a turbo button for Gemma
Multi-Token Prediction (MTP) is a flavor of speculative decoding. A small "drafter" model proposes the next several tokens, then the much-larger target model verifies all of them in a single forward pass. Tokens the target accepts are kept; rejected ones get re-sampled normally. When the drafter is well-aligned with the target, you can produce 2-4 output tokens per target forward — speedup directly proportional to acceptance rate.
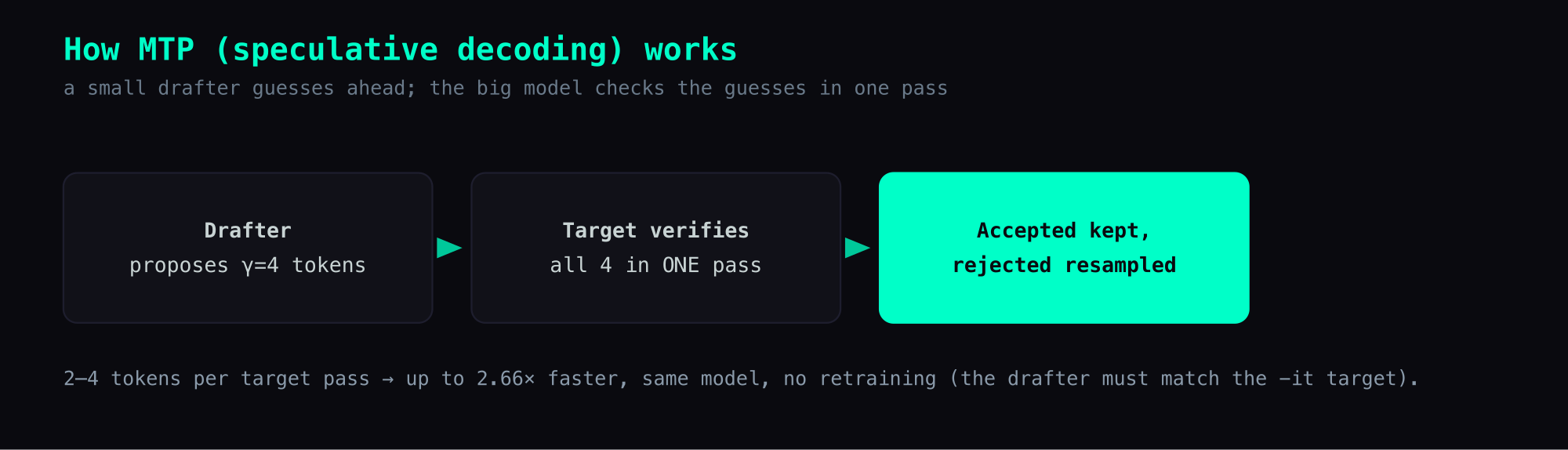
Google released matched MTP drafters for all four Gemma 4 sizes (E2B / E4B / 26B-A4B / 31B Dense) on 2026-05-05, claiming up to 3× speedup with no quality loss.
vLLM opened and approved the support PR the same day. By the time I sat down 24 hours later, hospedales had already tested it on DGX Spark with NVFP4 (1.84× speedup), reported two bugs back to the PR, and the PR author landed both fixes within hours. So this article isn't pioneering — it builds on existing work, adding the FP8 instruction-tuned configuration as a third data point. Single-stream we hit 108 tok/s, which is 2.09× the 52 tok/s I recorded for the same model in Part 7.
There was one moment where I thought MTP just didn't work on DGX Spark. The reason ended up being something nobody had written down, and once I saw it, the rest fell into place fast.
Setup: standing on the shoulders of giants
The day-of-release timeline was aggressive:
- 2026-05-05 16:03 UTC — PR #41745 opened by @lucianommartins (Google engineer)
- 2026-05-05 18:14 UTC — @hospedales' first PR comment: NVFP4 26B + MTP benchmark on DGX Spark, plus first bug fix (
intermediate_size) - 2026-05-05 18:25 UTC — vLLM published the preview Docker image (
gemma4-0505-arm64-cu130) - 2026-05-05 19:57 UTC — @hospedales' second PR comment: second bug (
quant_config) + updated benchmark numbers - 2026-05-05 21:54 UTC — @benchislett (vLLM core maintainer) APPROVED the PR; both bugs already fixed in PR head
Two bugs hospedales identified that mattered for quantized targets:
intermediate_sizefrom wrong config layer (gemma4_mtp.py:297): the drafter MLP needstext_config.intermediate_size(8192) but the first PR commit pulled from top-level config (4096). MLP construction is half-size, weight load fails.quant_configpropagation to drafter Linears (lines 186/193/299): the target'squant_config(e.g.modelopt_fp4) was being passed to drafter Linear layers. vLLM allocates draft params with packing applied, but the drafter ships unquantized BF16 weights → shape mismatch on load.
Both fixes are in the PR's current head. But the official preview Docker image was built at an earlier SHA (9b4e83934) before either fix landed. So for any quantized target, the preview image needs the updated gemma4_mtp.py bind-mounted over its bundled copy. With BF16 targets, the unfixed image works; with FP8 / NVFP4, both bugs hit.
The setup we used:
- Hardware: DGX Spark (GB10 / SM12.1, 128 GB unified, 273 GB/s LPDDR5x)
- Docker:
vllm/vllm-openai:gemma4-0505-arm64-cu130(arm64 architecture, matches DGX Spark; CUDA 13.0) - Bind-mount:
/path/to/PR-head/gemma4_mtp.pyover docker's/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/gemma4_mtp.py - Drafter:
google/gemma-4-26B-A4B-it-assistant(~870 MB BF16, Apache 2.0) - Three target candidates tested below
The trap: drafter pairs with -it, not base
Reasonable first move: I had gemma4-26b-a4b-fp8 already on disk (a community quantization I've been using for a while). Quick swap, run the bench:
| Config | tok/s | Speedup |
|---|---|---|
| FP8 base baseline | 41.25 ± 0.07 | 1.0× |
| FP8 base + MTP γ=2 | 25.37 ± 0.02 | 0.62× ❌ |
A 38% slowdown, not speedup. Switching to --enforce-eager produced the same negative result (35.71 vs 22.88 tok/s, same 0.64× ratio). The std was tight (0.02-0.10), so this wasn't measurement noise — MTP was reproducibly worse than baseline.
Investigation took 30 minutes. The thing nobody had written down:
$ grep chat_template tokenizer_config.json
chat_template: NO
My FP8 model was the base variant, not instruction-tuned. No chat template, no RLHF.
The drafter gemma-4-26B-A4B-it-assistant is paired (per Google's model card) with gemma-4-26B-A4B-it. My deduction, not a measurement: the drafter was likely trained against the post-RLHF logit distribution of the -it target. Pair it with a base model and the logit signal isn't there. Acceptance rate must be very low — I didn't instrument it exactly, but the speed math forces that conclusion. Drafter forward time then becomes pure overhead with nothing to amortize against.
This isn't documented anywhere. Not in Google's announcement, not in the HuggingFace blog, not in the PR description. Both implicitly assume -it targets — and many self-hosted quantizers (myself included) had been running base variants for various reasons.
The fix was finding an -it FP8. Several community quants exist; I chose RedHatAI/gemma-4-26B-A4B-it-FP8-Dynamic — Red Hat AI is a known reliable name in the vLLM ecosystem, FP8 Dynamic is a vLLM-native format, and the model card is clear about provenance.
After re-downloading and re-running:
| Config | tok/s | Speedup |
|---|---|---|
| it-FP8 baseline | 40.85 ± 0.10 | 1.0× |
| it-FP8 + MTP γ=2 | 74.51 ± 0.95 | 1.82× |
| it-FP8 + MTP γ=4 | 108.78 ± 0.41 | 2.66× ✅ |
We hit 108 tok/s. Drafter pairing was a silent killer — same drafter, same target architecture, but the -it distribution alignment doubled throughput.
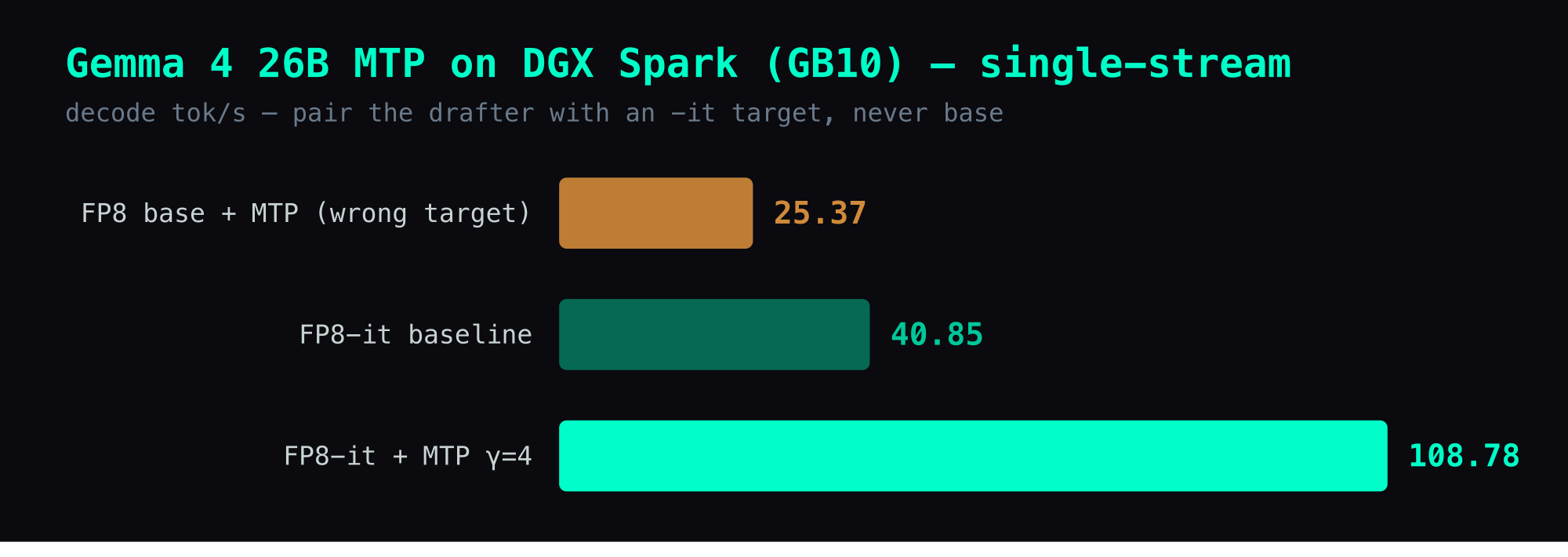
Three-target comparison matrix
I tested three quantized targets with Google's gemma-4-26B-A4B-it-assistant drafter — γ=4 on the two -it targets; the FP8-base row is the γ=2 trap result from above (it's a slowdown at any γ):
| Target | -it / base? | Baseline | + MTP | Speedup |
|---|---|---|---|---|
| Community FP8 base | base | 41.25 | 25.37 (γ=2) | 0.62× ❌ |
| NVIDIA NVFP4 it | -it | 30.23 | 76.88 | 2.54× ✅ |
| RedHat FP8 it | -it | 40.85 | 108.78 | 2.66× ✅ |
FP8-it beats NVFP4-it for both baseline and MTP — consistent with Part 19's finding that on GB10 the FP8 path beats NVFP4. SM12.1 (GB10) lacks the tcgen05/TMEM tensor-core path the native FP4 MoE kernel needs, so NVFP4 falls back to Marlin (a kernel that decompresses FP4 to BF16 at runtime). FP8, in contrast, uses native scaled matmul — faster path. The MTP layer doesn't change this gap; it stacks on top, preserving the ~30% FP8 advantage.
Comparison to hospedales' published numbers on identical hardware:
- His NVFP4 baseline: 23.2 tok/s (with
--enforce-eagerand--max-num-seqs 4); ours 30.23 (CUDA graphs, no batch limit) — same model, different config, ours runs the optimization layers - His NVFP4 + MTP γ=4: 42.6 tok/s; ours 76.88 — same delta from config differences propagates
Concurrency: 8 users at 84 tok/s each
Single-stream throughput is only half the story. Production cases usually run multiple concurrent requests. Same model + γ=4, varying batch:
| Concurrency | Aggregate tok/s | Per-request tok/s | vs baseline |
|---|---|---|---|
| 1 | 108.78 ± 0.04 | 108.78 | 2.66× |
| 4 | 348.30 ± 0.82 | 87.08 | 8.53× |
| 8 | 674.28 ± 6.03 | 84.29 | 16.51× |
The two columns answer different questions:
- Aggregate tok/s = total tokens the box emits per second across all in-flight requests. This is the operator's view — how much traffic the hardware can serve, how many mouths one $3,000 box can feed.
- Per-request tok/s = aggregate ÷ concurrency, the speed each individual user perceives. This is the user's view — does the chat feel snappy when the box is busy.
Read the conc=8 row this way: 8 concurrent users, each seeing ~84.29 tok/s on their screen, summed across all 8 = 8 × 84.29 ≈ 674.28 tok/s aggregate.
At concurrency=8, each user still gets ~84 tok/s individually — that's 2× the original single-user baseline of 40 tok/s. Eight users hammering the same box, each one perceives 2× speed over what one user would have without MTP.
Aggregate scaling from conc=1 → conc=4 → conc=8 is roughly 1× → 3.2× → 6.2×. Drafter forward shares well across the batch (single drafter pass produces draft tokens for all requests in flight), and target verification batches efficiently too.
For a ~$4,700 desktop, 674 tok/s aggregate handles small-team internal chatbot loads comfortably. (Whether it counts as "production" in your environment depends on your monitoring, retry, and SLA layer — none of which this article validates.)
Output sanity check: lossless or not?
Google's announcement claims no quality loss. The PR's test plan sets specific bars for MTP:
MTP_SIMILARITY_RATE = 0.8— across a batch of test prompts, at least 80% of prompts must produce identical output between baseline and MTP (prompt-level, not token-level).- GSM8K accuracy must stay above 0.8.
So a minority of prompts may diverge in their output text, but benchmark quality must hold. To verify on our setup, I ran a simple prompt with identical seed against baseline and MTP γ=4:
Prompt: "List the first 5 prime numbers and explain in 2 sentences why each one is prime."
Baseline (48 tokens):
The first 5 prime numbers are 2, 3, 5, 7, and 11. Each of these numbers is prime because it is only divisible by 1 and itself.
MTP γ=4 (54 tokens):
The first five prime numbers are 2, 3, 5, 7, and 11. These numbers are prime because they are greater than 1 and cannot be formed by multiplying any two smaller natural numbers.
Both correctly answer (2, 3, 5, 7, 11), both give a coherent explanation. But the wording isn't identical — baseline uses "divisible by 1 and itself", MTP uses "cannot be formed by multiplying any two smaller natural numbers". Both are mathematically valid definitions of primality.
This is exactly the kind of divergence the PR test plan permits within its 80% prompt-match bar. Semantically lossless, not bit-identical. FP8 paths and speculative verification together produce text-level non-determinism even with the same seed. Don't expect deterministic byte-for-byte reproduction; do expect the same answer quality.
Credits and provenance
This 24-hour iteration was only possible because of work done by:
- Google Research / DeepMind — the Multi-Token Prediction technique itself plus all four Gemma 4 drafter checkpoints
- @lucianommartins (Google) — vLLM PR #41745 author; opened, iterated, and got it approved within hours
- @benchislett — vLLM core maintainer who reviewed and approved the same day
- @hospedales — first DGX Spark + NVFP4 + MTP measurement, published openly in the PR comments (first comment + second comment). Identified both critical bugs that affected quantized targets, posted patches, validated the fixes
- RedHatAI —
gemma-4-26B-A4B-it-FP8-Dynamicquantization - NVIDIA —
Gemma-4-26B-A4B-NVFP4quantization (one of the comparison-matrix entries) - vLLM team — preview Docker image
vllm/vllm-openai:gemma4-0505-arm64-cu130(arm64 architecture matches DGX Spark)
Our specific contribution: the FP8 instruction-tuned configuration plus concurrency=4/8 aggregate throughput numbers. Hospedales tested NVFP4 single-stream; we add the FP8-it path and the multi-user numbers, giving DGX Spark self-hosters a copy-pasteable best-config recipe.
Limitations
- Preview Docker image lacks the GB10 MoE tuning config. The startup log warns:
Using default MoE config. Performance might be sub-optimal! Config file not found at .../E=128,N=704,device_name=NVIDIA_GB10,dtype=fp8_w8a8.json. Our baseline is roughly 24% slower than what the same model achieves on a self-built vLLM with the GB10 config. When upstream vLLM ships GB10 tuning (or someone publishes the auto-tune output), both baseline and MTP numbers will improve proportionally. - My Part 20 NVFP4→FP8 Triton patch isn't stacked on top. The
sm121_quant_bind.soextension I built was compiled against vLLM 0.17 + torch 2.10+cu131 against Qwen 35B's Marlin path; this preview image runs torch 2.11+cu130 with Gemma 4. The ABI mismatch means I can't simply mount the extension. Stacking would require rebuilding from source against the new toolchain — a 30-60 minute compile that's worth doing on a follow-up but not for this article. - Drafter is BF16, not quantized. At 870 MB, it's noise on a 128 GB unified memory budget. No FP8 / NVFP4 drafter exists in the community yet. When one ships, drafter forward overhead might shrink another 20-30% which would help γ scaling.
- Output is not bit-deterministic. Same prompt + same seed produces semantically equivalent but textually different outputs across runs with MTP. The PR test plan explicitly accepts this; production callers should treat it as approximately deterministic, not strictly so.
Quickstart: two commands to run it
For DGX Spark owners running Gemma 4 26B-A4B starting today, here's the actually-copy-pasteable recipe.
Step 1 — fetch the models once (skip if already on disk):
huggingface-cli download RedHatAI/gemma-4-26B-A4B-it-FP8-Dynamic \
--local-dir ~/models/gemma4-26b-a4b-it-fp8
huggingface-cli download google/gemma-4-26B-A4B-it-assistant \
--local-dir ~/models/gemma4-26b-a4b-it-assistant
Step 2 — grab the patched gemma4_mtp.py directly from vLLM's PR head SHA (GitHub raw URLs pinned to a commit are immutable, so this stays valid even if the PR force-pushes later) and run:
# fetch the patched file (includes hospedales' two bug fixes,
# which the official preview docker image was built before)
# URL is pinned to PR #41745 head SHA d8b3826
wget https://raw.githubusercontent.com/vllm-project/vllm/d8b3826648da6b407f8c55457a2103be9aeb5d83/vllm/model_executor/models/gemma4_mtp.py \
-O /tmp/gemma4_mtp.py
# start vLLM
docker run -d --name gemma4-mtp \
--gpus all --ipc host --shm-size 64gb \
-p 8000:8000 \
-v ~/models:/models \
-v /tmp/gemma4_mtp.py:/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/gemma4_mtp.py:ro \
vllm/vllm-openai:gemma4-0505-arm64-cu130 \
--model /models/gemma4-26b-a4b-it-fp8 \
--speculative-config '{"method":"mtp","model":"/models/gemma4-26b-a4b-it-assistant","num_speculative_tokens":4}' \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.85 \
--max-model-len 4096 \
--limit-mm-per-prompt '{"image":0,"audio":0,"video":0}'
That's it. Single-stream 108 tok/s, concurrency=8 674 tok/s aggregate with ~84 tok/s per request. A ~$4,700 desktop AI workstation comfortably serving a small team's internal chatbot loads — the throughput layer is solved; production reliability still depends on whatever monitoring / retry layer you wrap it in.
When PR #41745 merges and the next official Docker image ships, the bind-mount step is no longer needed — pull the new image and drop the wget + -v /tmp/gemma4_mtp.py:... line.
Related reading
- Part 7 — Gemma 4 26B at 52 tok/s on DGX Spark with NVFP4 — the original record this post supersedes
- the complete Gemma 4 DGX Spark guide (E2B/E4B/26B/31B compared)
- Part 19 — NVFP4 is a trap on GB10: FP8 wins by 32% — why this article picked the FP8 path
- Part 20 — NVFP4 → FP8 Triton patch — the SM121 acceleration work mentioned in limitations
- Google blog: Accelerating Gemma 4 with MTP drafters
- vLLM PR #41745: Add Gemma4 MTP speculative decoding
- hospedales' DGX Spark NVFP4 first test + follow-up bug patch
FAQ
- How fast is Gemma 4 26B-A4B with the MTP drafter on DGX Spark?
- FP8 instruction-tuned target + Google's official MTP drafter at γ=4 hits 108.78 ± 0.41 tok/s single-stream — 2.66× the 40.85 tok/s baseline. At concurrency=8, aggregate throughput reaches 674.28 tok/s while each individual request still gets 84 tok/s. All measurements are N=5 with std under 1%.
- Why does the base model with MTP run slower than baseline?
- The drafter `gemma-4-26B-A4B-it-assistant` is paired (per Google's model card) with `gemma-4-26B-A4B-it`. I infer the drafter was trained against the instruction-tuned target's logit distribution; pairing it with a base model means predictions miss the post-RLHF logits and acceptance rate must be very low (I didn't instrument exactly, but the speed math forces that conclusion). The drafter forward overhead then can't be amortized. I measured base FP8 going from 41.25 tok/s baseline to 25.37 tok/s with MTP — a 38% slowdown, not the 2-3× speedup promised. The drafter must be paired with an instruction-tuned target.
- Is MTP integrated in vLLM main yet?
- PR #41745 by lucianommartins (Google) was opened on 2026-05-05 and was approved within hours by vLLM core maintainer benchislett. All 7 CI checks passed. As of 2026-05-06 the PR is still open and awaiting merge. Anyone can run it today via the official `vllm/vllm-openai:gemma4-0505-arm64-cu130` preview Docker image (arm64 matches DGX Spark architecture). For quantized targets, the docker image needs the latest `gemma4_mtp.py` bind-mounted over its older copy — the preview was built before two important bug fixes hospedales identified in PR comments landed.
- Is MTP truly lossless? Does it produce identical output to baseline?
- **Semantically lossless, not bit-identical**. Google's announcement says no quality loss. vLLM's spec-decode test for MTP enforces `MTP_SIMILARITY_RATE = 0.8` — at least 80% of *prompts* in a test set must produce identical output between baseline and MTP, plus GSM8K accuracy must stay above 0.8. With identical prompt + seed, baseline and MTP γ=4 both correctly answered a prime-number question with coherent explanations, but the wording differed slightly. FP8 quantized paths combined with speculative verification introduce text-level non-determinism; the same answer quality holds, byte-identical reproduction does not.
Read next
- 2026-06-01[Benchmark] NVFP4 W4A4 beats FP8 on a DGX Spark MoE: 67 vs 52 tok/s once CUDA graphs fire
On a GB10 DGX Spark, NVFP4 W4A4 went from 23 to 67 tok/s the moment I dropped --enforce-eager — beating FP8 by 29% and saving 16GB. The catch from Part 32 was real, just dense-only.
- 2026-05-09Want MTP speedup on abliterated Gemma 4? Vanilla draft can't track the modified body
I self-quantized huihui's abliterated Gemma 4 26B-A4B to FP8-Dynamic and shipped it to HF. After sweeping num_speculative_tokens 1→4, the abliterated body is exactly as fast as vanilla on the same stack (39.4 vs 39.3 tok/s baseline) and the MTP boost at n=1 is equivalent — but per-position acceptance decays so steeply that deeper speculation is wasted. Three drafts of this article each smuggled in a different fabrication that Codex caught; this is the corrected version.
- 2026-04-05Gemma 4 26B-A4B on DGX Spark: 52 tok/s with NVFP4, skip the 31B
Gemma 4 26B-A4B + NVFP4 hits 52 tok/s on DGX Spark (GB10) — 7.5× faster than the 31B dense, in 16.5 GB with 82 GB free for KV cache. Plus the vLLM 0.19 marlin/patch gotchas that make it work.
- 2026-06-04[Benchmark] Gemma 4 12B Omni on DGX Spark: Weight-Only NVFP4 Beats W4A4 (and Keeps Multimodal)
I quantized Google's new omni Gemma 4 12B on a DGX Spark GB10. Weight-only NVFP4 hits 24.9 tok/s in 7.7 GB and keeps image/audio/video working — full W4A4 is slower AND breaks multimodal.
Don't miss the next one
Subscribe, and you won't.
One-click unsubscribe anytime.