DGX Spark · part 40
Directional Steering on an Abliterated DeepSeek-V4 (DGX Spark): the same scalpel as abliteration, and why the second cut fights back
❯ cat --toc
TL;DR
ds4 ships directional steering — a runtime activation edit that nudges the model along a chosen direction. The math is literally abliteration with a continuous, signed scale. I got it running on GB10/CUDA (the tooling looks Metal-only, but the activation dump fires on CUDA too) and pulled a verbosity vector from our abliterated Q2 model. The dial works — but it runs non-monotonic, and positive scales collapse the output to a four-word fragment. Two cuts from the same scalpel, fighting each other — and that fight is the interesting part.
TL;DR
- Directional steering = no weight change, no prompt change. At inference, you push the model's internal residual stream along a direction. ds4 has it built in (
--dir-steering-file). - The math is
y = y - scale·dir·dot(dir, y): positive scales remove the direction (scale=1 is a full projection-out), negative scales amplify it. Abliteration is the scale=1 case applied to the refusal direction — baked into the weights — and steering is that same edit as a live, signed dial. - The tooling looks Metal-only, but CUDA captures activations fine: ds4's
metal_graphis really a unified GPU executor,DS4_METAL_GRAPH_DUMP_*fires on CUDA, and all 43ffn_outdumps land. - On our abliterated DeepSeek-V4-Flash Q2, a verbosity vector swept across scales works — but non-monotonically, with the positive side collapsing. Nothing like the clean, monotonic dial in the docs.
- Takeaway: the two cuts share a scalpel, and stacking the second on an already-operated-on activation space makes them fight. That isn't a bug; it's the spine of this post.
What steering actually does
When an LLM computes each token, a high-dimensional vector — the residual stream, the "current of thought" — flows through the layers one at a time. Here's the load-bearing premise: many concepts and behaviors can be approximated as directions in that space. "Verbose" is a direction. "Refuse" is a direction. "Formal tone" is a direction.
Directional steering is simply this: at every layer, nudge that thought-vector along the direction you picked. You're editing the model's thought itself, not asking it nicely to comply.
Why reach for that? Because controlling a model's behavior has long had only two knobs, and steering is the neglected third one:
| Knob | How you control it | The catch |
|---|---|---|
| Prompt (just ask) | "Be concise" | The model can ignore it, forgets it over long context, burns tokens — it's a suggestion |
| Fine-tune (change the weights) | Retrain on data | Expensive, needs compute and data, permanent, not per-request |
| 🆕 Steering (push the thought) | Add a direction vector | Narrow, but it sits in the sweet spot |
Steering is firmer than a prompt (it's mechanical, not a suggestion the model can drift away from) and lighter than a fine-tune (no retrain — one vector and one scalar knob). And that scalar is a continuous dial: 0 is off, larger is stronger, negative flips the direction.

"I already abliterated — why bother with steering?"
This is the central question. If you run self-hosted open models, you're probably already using abliteration — deleting the "refusal" direction from the weights to get a model that answers anything. So what's left for steering?
They operate at different layers.
- Abliteration handles "permission" — delete the refusal, once, baked into the weights, for one direction in practice.
- Steering handles "shape" — push any direction at inference, continuously, reversibly.
Removing the "no" is not the same as controlling the "how." Your abliterated model answers plenty it used to refuse, but it still rambles, still drifts its persona by turn 50, still fabricates — none of which abliteration was ever about.
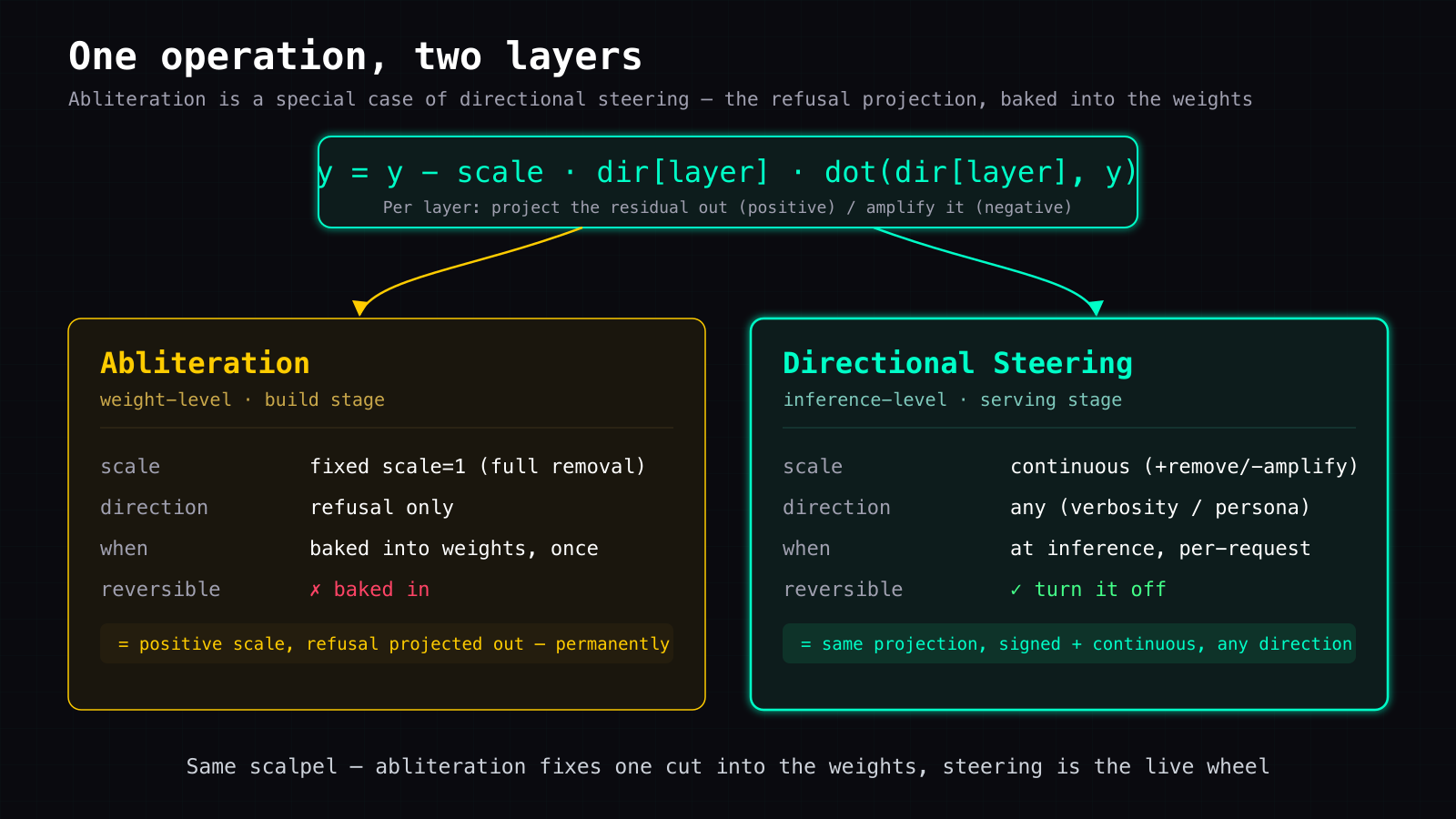
The elegant part is in the math. ds4's steering formula:
y = y - scale * dir[layer] * dot(dir[layer], y)
- A positive scale removes that direction — at scale=1 it's a full projection-out, exactly directional ablation.
- A negative scale amplifies it (the reverse, which abliteration doesn't do).
So abliteration is the scale=1 case of this edit, applied to the refusal direction and baked permanently into the weights.
Think of it this way: abliteration permanently sets the alignment of one wheel; steering is the live wheel in your hands — any direction, any time, recenterable. Asking "why steer if I already abliterated" is close to asking "why keep a steering wheel if the wheels are already aligned."
That also sets up the tension: steering assumes the activation space has clean, linear directions to push. But abliteration has already taken a scalpel to that space. So — what happens when you steer a model that's already been abliterated?
ds4 ships it, and CUDA actually works
--help steering lays out the whole thing:
--dir-steering-file FILE load a 43 x 4096 f32 direction file
--dir-steering-ffn F apply steering after FFN outputs; default 1
--dir-steering-attn F apply steering after attention outputs; default 0
The dir-steering/ directory even bundles the tooling: build_direction.py (extract a direction from contrastive prompt pairs), run_sweep.py (sweep the scale), and 100 succinct-vs-verbose example pairs. Looks like an afternoon's work.
But there's a snag: the whole thing is written for Apple Silicon Metal. Extraction relies on the DS4_METAL_GRAPH_DUMP_* env vars to dump activations — METAL right there in the name. We're on GB10 / CUDA, so the first question is: does that dump even fire on CUDA?
Reading the source flipped my assumption: what ds4 calls metal_graph is really its unified GPU executor, not an Apple-only path — the same file holds metal_graph_decode_cuda_* functions. The dump routine uses the backend-agnostic ds4_gpu_tensor_read, which CUDA hits too.
One probe settled it. Stop the daily server to free the GPU, run once:
DS4_METAL_GRAPH_DUMP_PREFIX=/tmp/probe/dump \
DS4_METAL_GRAPH_DUMP_NAME=ffn_out DS4_METAL_GRAPH_DUMP_POS=0 \
./ds4 --cuda -m <abliterated-Q2.gguf> --ctx 512 --prompt-file p.txt -n 1
Twenty-two seconds later, all 43 dump_ffn_out-<layer>_pos0.bin files were there — one per layer, matching DeepSeek-V4-Flash's 43 layers × 4096 embedding. Applying the vector works too: ds4_gpu_directional_steering_project_tensor has a CUDA implementation, and ds4_gpu_tensor_write loads the vector into a GPU tensor.
Two small traps to save the next person:
- The official
build_direction.py/run_sweep.pycommands don't pass--cuda, so they fall back to the CLI's default backend — copy them and add the flag. run_sweep.py --scales "-1,..."makes argparse read the leading-1as a new flag — use the equals form,--scales=-1,-0.5,0,1,2.
One practical constraint: extraction needs the GPU to itself (one 80 GB copy of the weights on the device), and a second copy won't fit — so the daily inference service goes offline for the whole experiment. I wrapped the run in trap restore_daily EXIT HUP INT TERM, so it restarts the daily server on completion or on any failure, instead of leaving the service down.
It works — but it won't behave
I pulled a verbosity vector from 30 succinct-vs-verbose pairs (a subset of the official examples) — 704,512 bytes, exactly 43 × 4096 × 4. Then I fixed the prompt ("Explain why databases use indexes") and swept the scale:
| FFN scale | Words out | Note |
|---|---|---|
| −1 | 65 | longer |
| −0.5 | 78 | longest |
| 0 (baseline) | 28 | the abliterated model is terse by default |
| +1 | 23 | slightly shorter |
| +2 | 4 | collapses to "Why Databases Use Indexes" — a title fragment |
Against the docs' clean, monotonic vanilla behavior (negative → shorter, positive → longer), ours diverges three ways:
- The direction is flipped (but this one is probably just a convention). Negative lengthens (28 → 78), positive shrinks (28 → 23). The README's vanilla runs negative-short / positive-long; ours is the reverse — but a flipped sign most likely comes from the vector's orientation (the
good − bad/ orthogonalize convention), and you'd just flip it back. Not a big deal. - The negative range is non-monotonic (convention can't explain this). −0.5 (78 words) runs longer than −1 (65 words) — pushing harder doesn't push further.
- Positive scales collapse fast. +2 caves into a four-word title fragment that isn't even a sentence. That's over-steer, and the usable band is narrow.
This isn't a failure — it's a result. Set the flipped sign aside (convention covers it); the intriguing parts are the non-monotonicity and the collapse, which convention does not cover. One hypothesis — and without a vanilla-model control sweep it's only that — is the tension I set up earlier: abliteration may have already reshaped the activation geometry. Once the "refusal" direction is projected out of the weights, the residual space need no longer carry the clean directional structure the vanilla model had. Extract a verbosity direction from that already-cut space and project it back in, and the second cut lands on the first cut's wound — and they fight.
(I can't rule out noise from using only 30 pairs, or a scale band that's too coarse. A clean 100-pair re-extraction and a finer sweep are follow-up. But the qualitative pattern — positive collapses, negative expands — is already clear at 30.)
What we learned
What's solid
- The feature runs on GB10/CUDA with an abliterated Q2 model — the biggest unknown going in ("is the dump Metal-only?") is settled: CUDA works fine.
- Steering is mechanically abliteration's continuous, reversible twin — the conceptual mapping holds.
- The whole pipeline is reproducible (add
--cuda, use--scales=, wrap in a restore trap).
What surprised me
- On an abliterated model the dial is not the vanilla clean monotonic curve — a strong hint that abliteration and steering interact. I haven't seen that written up.
- Over-steer collapse comes fast (+2 already caves), so the usable band is narrow — start around ±0.3.
Still open
- Is the non-monotonicity 30-pair noise or intrinsic to the abliterated geometry? (Needs 100 pairs to separate.)
- Which way does the sign really go — a true direction, or an artifact of the
--orthogonalize/--pair-normalizeswitches? - Would a persona / anti-fabrication direction behave more cleanly than verbosity? (That's the direction that would actually be useful for a self-hosted agent.)
Is it worth running as a live knob? Honestly, not yet. Three obstacles — it's a launch-level, global flag (it steers the whole service, not per message), it's unpredictable on abliterated weights, and every tuning pass takes the service offline. So the "live persona dial" dream is further off than it looked. As research and teaching material, though, this "same scalpel, second cut fights back" story lands well.
Part of the DGX Spark series. Related: how the ds4 engine runs DeepSeek-V4-Flash and the abliterated Q2 quantization.
FAQ
- What is directional steering?
- At inference time, you add or subtract a chosen direction to the model's residual stream at every layer, which shifts its behavior (verbosity, tone, persona, refusal) without touching the weights or the prompt. ds4's formula is y = y - scale * dir[layer] * dot(dir[layer], y): a positive scale projects the direction out, a negative scale amplifies it. The vector file is a flat 43x4096 f32 (one normalized direction per layer), loaded with --dir-steering-file and --dir-steering-ffn.
- I already abliterated my model — why bother with steering?
- They solve different problems. Abliteration handles permission — it deletes the refusal direction from the weights, once, permanently, for one direction only. Steering handles shape — push any direction at inference, with a continuous strength, reversibly. Removing the 'no' is not the same as controlling the 'how'. And they are the same operation: abliteration is just steering applied to the refusal direction at fixed strength, baked into the weights. Steering is the live steering wheel.
- Does directional steering work on GB10 / CUDA? Isn't the ds4 tooling Metal-only?
- It works. What ds4 calls metal_graph is actually its unified GPU executor — the same file holds metal_graph_decode_cuda_* functions. So the DS4_METAL_GRAPH_DUMP_* env hook that captures activations fires on CUDA too. I ran ./ds4 --cuda with the dump env and got all 43 ffn_out dump files. The apply side, ds4_gpu_directional_steering_project_tensor, has a CUDA implementation as well. The only patch you need: the official build_direction.py / run_sweep.py don't pass --cuda, so add it.
- How well does steering work on an abliterated model?
- It works, but it ignores the textbook. From a 30-pair verbosity vector on Huihui-DeepSeek-V4-Flash abliterated Q2: baseline 28 words, negative scale lengthens (-0.5 -> 78, -1 -> 65), positive scale shrinks then collapses (+1 -> 23, +2 -> a four-word title fragment). Three things stand out: the direction is flipped versus the README (most likely just a vector-orientation convention), the negative range is non-monotonic (-0.5 is longer than -1), and positive scales over-steer into collapse fast. The last two aren't explained by convention — the likely cause is that abliteration already reshaped the activation geometry, so the second cut fights the first. This is a 30-pair proof of life; a clean sweep is follow-up work.